



Vr2Io
Members
-
Joined
Everything posted by Vr2Io
-
I haven't preclear disk longtime, this seems UD / preclear associate together, for me, if I click "X" it won't preclear disk, (I haven't install preclear plugin). You may try uninstall Preclear disk plugin. I always use Wipefs, simple and seems deep clean little bit.
-
Strange haven't detect docker on br0, but expected won't detect device / docker on br0.xx.
-
If you click "X" to clear disk, then UD could create the filesystem success ? After that it just grey out the mount button ? Pls provide the message / log as above. Pls also try " wipefs -f /dev/sda ".
-
Problem look like because you only insert one disk in RAID0 box, to be support form a 24TB disk, this really depends on the box support or not. But why don't simple create a RAID0 pool and mount that by UD, the only reason I expect is lack of SATA / SAS port. Not recommend use RAID box, you probably will loss disk health status monitoring.
-
If VM and docker set in same br0, then no reason both wouldn't see each other. Does your VM ( Windows ? ) allow response PING ?
-
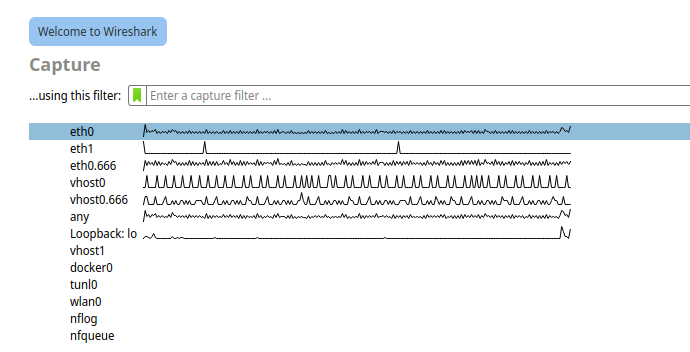
Depends on the docker and setting in what network mode , for example, I assign Wireshark in host mode and it can access all interface., you can open different Windows to monitor different interface. In previous, I use Fing Box to do same work as "container - WatchYourLan", but to be honest , not much meaning of that. But Fing develop a hardware and Apps for this solutions.
-
I would suggest you continue use Windows VM to troubleshoot first. Fix driver install issue, try below Then confirm ESP controller also recognises / working ( DON'T flash the firmware ) http://blog.rfxcom.com/ ..... Use esp.huhn.me to flash new software in the ESP32-S3 controller of the RFX-433. ..... Spacehuhn BlogHow to flash ESP32 or ESP8266 from your BrowserUpload .bin files to your ESP from this website. No installation is required.
-
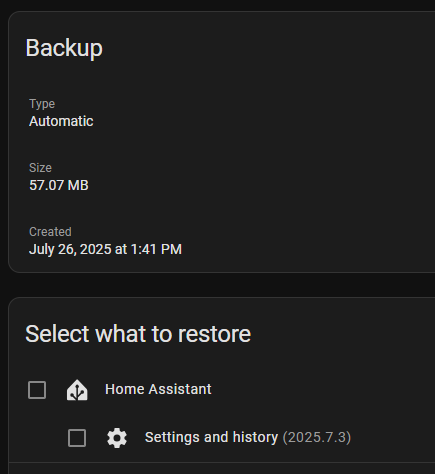
I have't notice this thread, so reading through. I start HA in Raspberry then direct migrate to VM for 1 (or 2 yrs). But after trying docker then never return back ( since Sep 2023 ), it use much less resources and restart almost on the fly. The main problem are you can't migrate from VM to docker, so you need start in fresh. Next is its worst backup functionality ( should overcome in current version ) ..... but backup docker appdata actually much simple then that. ( My HA appdata ~164MB ) Below are current backup functionality , I just simple trying ,but never use.

-
I have same conversation with you in previous post about those converter. Even you buy those converter with correct spec. but end up how they perform with your existing equipment is another story. I buy three different converter, two are max at 2.5g and one is 10g in spec. The one which work perfectly with 2.5g also not the 10g one. It haven't pause frame generate. When you say those converter actually work in 10g in SFP+ side this also incorrect. The 10g converter were 3x expensive then those 2.5g converter. At the end, I also use the 10g one working in 10g but not 2.5g. I use Mikrotik and Unifi switch, there SFP+ port are natively suppprt 2.5g and 10g but no 5g.
-
I think you shouldn't focus on setting, it likely the 2.5g NIC not compatible/solid with the router/switch, when I first apply 2.5g to my network, there also many strange issue, my switch are 10g SFP+ ( also have 10G Ethernet, but it wouldn't support multi giga ), so SFP+ to 2.5g converter need, I try 3 different type multi giga converter then found only one work perfectly, and this involves many troubleshooting hrs. Rencetly, I upgrade existing router to a new one, it also have some strange issue, but to be true all nothing relate to Unraid, anyway this is my experience only. My Unraid 2.5g NIC are realtek 8125(B?), I haven't install realtek driver plugin, it rock stable.
-
Does both in same network / subnet ? Any blocking between them ? Could you try on other browser or PC ?
-
And completed now.
-
As mention, the access PC internet service, not Unriad self internet service. Once resume the access PC internet service, then update on-going as normal.
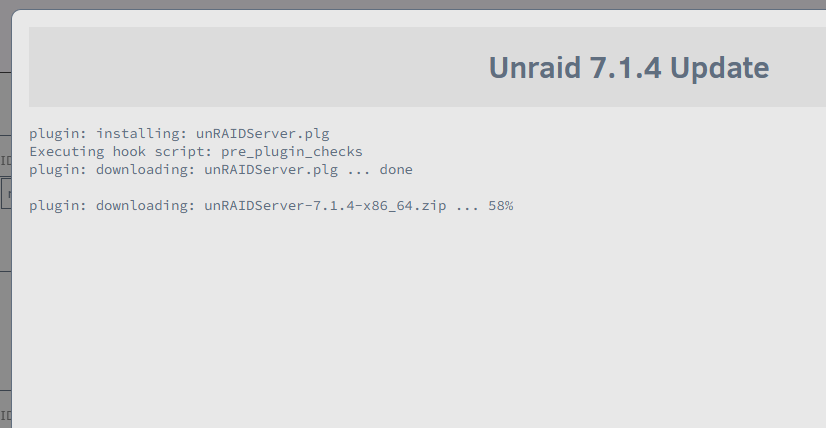
-
I simulate if the access PC haven't Internet access, it stay in same screen outlook as your screen capture. So pls ensure the access PC Internet service is normal.
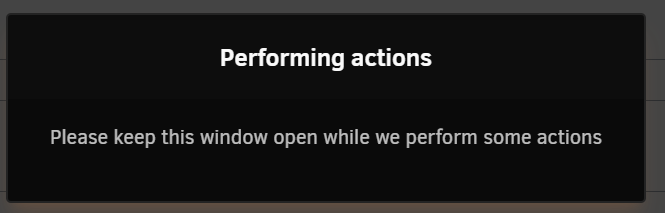
-
Update usually complete within 30min. If nothing happening or on-going then you should close it and restart. Post screen capture would better know whats going on. Pls make sure the access PC have normal internet access too.
-
Recent month have two internet issue, those cause little bit long outage time. My ISP modem problem : It's IP change and all internet access stop, I never got this type strange problem , my router can get IP from ISP, but all internet access fail, many hrs troubleshoot still can't fix the problem. Finally I request ISP onsite maintenance on next two day ....... but before they reach, I observe there are a reset button on modem, so I try to pin it and all problem solve, WTF this cause my internet service down for 24hrs+ My router WAN DNS setting problem, I use router self update dynamic DNS, it suddenly not work , also troubleshoot in some hrs and finally identify a setting which control router WAN use which DNS have problem, that public DNS won't resolve all request, after change to other public DNS then problem solve. This setting haven't change in longtime, so I already completely forget that. ( My LAN / Internet access haven't any problem because router WAN DNS and LAN DNS are different )
-
Also check the PC which access Unraid to perform update, its clock must up-to-date and internet aaccessable.
-
Look like problem relate ISP's IP change, due to not sure how you remote access your network and overcome this, but most likely reboot won't solve the problem. BTW, push power button usually perform normal shutdown, but don't hold the button too long, otherwise it will power-off immediately instead soft shutdown, we don't want corrupt file system.
-
Congratulations, network bridge somehow trouble. Does HA success control Eve device ?
-
Both correct.
-
Both are same, when Thread device connect thr WiFi, that is Thread over WiFi, if connect thr zigbee, that is Thread over Zigbee.
-
That's why I suspect problem here, your Thread device were connect thr ZBT1's WiFi network and your phone in ISP's WiFi network. During commissioning, Phone and Thread device need in same network, so you may try commissioning (pairing Thread device) by HA instead Phone. Your HA have connect multiple network, one is usual home network and one is ZBT1 network. But me just one, all IPv4 / Thread also in one. I recommend in this way, at least this look more simple and work.
-
The AP like a network Switch, you no need to setup a Switch to support IPv4 / IPv6 /Thread ..... both just need understand Ethernet frame for fundamental function. Pls note English is not my nature language, hope you understand what I say.
-
As mention before, I use existing WiFi AP, that AP no need to setup support IPv6 or Thread. The thread device just connect to it, and actually comunicate to Unraid in Thread (IPv6) with Unraid (Matter server). Just enable Unraid IPv6 and broadcast IPv6, also enable host access in docket setting.
-
But you use ZBT1 to form the Thread WiFi network ?







