Leaderboard




Popular Content
Showing content with the highest reputation since 03/26/24 in Report Comments
-
Please update to 6.12.10-rc.1. It should fix this issue. It's available on "Next".3 points
-
6.12.10-rc.1 does reslove the issue. Thanks.2 points
-
You can use rsync or freefilesync that will list both sides and copy only what's missing.2 points
-
@dlandon, Any thoughts on when this issue is going to be resolved? I know that I will not be upgrading from 6.12.8 until it is.2 points
-
Thanks for the report, known issue, should be fixed for next release.2 points
-
P.S. as a workaround for now, if you need to import a degraded pool give it the number of lots it should have, that won't trigger the bug, e.g.:
 2 points
2 points -
Understandable, I was just trying to make it easier to reproduce, because I wasn't able at first, but I've now managed to do it, difference was the number of slots for the new pool. Thanks for the report, it's a corner case, but still a bug.2 points
-
I've put some time into troubleshooting UD to see if there is something in the way UD is mounting remote shares. There doesn't seem to be anything that UD does or can do to cause this problem. I'm not one to play the blame game, but as we get into this I believe we are going to find it's related to a change in Samba or a Kernel change causing this. In our beta testing for one of the recent releases, we found an issue with CIFS mounts where 'df' would not report size, used, and free space on a CIFS mount point. When UD sees a CIFS mount with zero space, it disables the mount so UI browsing and other operations could not be performed. UD assumes there is a problem with the mount. It ended up being related to a 'stat' change in the Kernel failing on the CIFS mount. As has been said, this is related to remote mounts through UD. It does not affect the NAS file sharing functionality through SMB. I understand that this is an important functionality for many users and for the moment, downgrading to 6.12.8 is the answer. We will release a new version of Unraid as soon as we have an answer.2 points
-
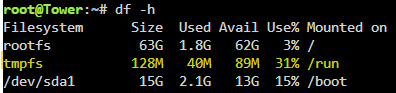
Issue is resolved for me with the fix in 6.12.9: root@Tower:~# grep -c ^processor /proc/cpuinfo 128 Thanks everyone
 2 points
2 points -
Last night I took the painful step of just blowing up the networks altogether. I deleted the network.cfg and the local-kv.db for Docker, then set up eth0, updated to 6.12.10, added the other interfaces and Docker networks back, and then set up my dozens of containers all over again. Three hours later I'm up on a current working state on 6.12.10 - still running macvlan as is my preference. I just hope that I get more stability on 6.12 this time than I ever did when I could update through 6.12.5. I'llmark this as the solution, but note that there are others who have had other successful workarounds.1 point
-
It would be great to finally fix it1 point
-
I tested the bonding suggestion, and that worked for me. After a reboot the container got the correct IP, but my network setting maybe different from yours. Next I’ll attempt an upgrade to 6.12.10 and see if that also works with regards to the container network settings surviving. EDIT: Upgraded and the network settings is indeed still sticking, I'll keep monitoring for stability:

 1 point
1 point -
Sorry for the late reply, but I have some personal issues to deal with first. I can't test at the moment, but there are two ways to deal with your configuration. 1. Define eth0 as bonding interface as well (next to bond2). Then upgrade and see if all assignment are correctly processed. 2. If the above doesn't work, then (temporary) configure eth2 as regular interface (remove bonding)1 point
-
I've ordered replacement processor, motherboard, and RAM. I'm currently testing, but it seems like it's actually the RAM, even though it didn't show any errors, and I tested each one separately, so both must be defective or both incompatible. Although i checked compatability before 🤔 ASUS ROG STRIX B760-I GAMING WIFI with Corsair Vengeance, DDR5-4800, CL40 - 32 GB Dual-Kit, black Now I have the Kingston FURY Beast Black DDR5 16GB (2x8GB) 5600MT/s DDR5 CL40 DIMM Desktop Gaming Memory Kit with 2 - KF556C40BBK2-16 and so far, Unraid is running without any error messages. I'll do another test later with the old RAM to double check it was the RAM, one module at a time.1 point
-
no more kenel panics, Gracias @JorgeB1 point
-
I expect that is inherent in the fact that Unraid is based on Linux and the pre-clear stops a system ‘sync’ call from completing.1 point
-
I've already waned 2 separate users in their threads in General, and verified the same thing was happening in mine. Note that each of them were using separate VPN enabled containers, deluge and sabnzbd Here's one that's still up in the support thread you linked, their password is in plain text in system/ps.txt:1 point
-
Done, let see what happen . I will post the result in a couple of days if everything goes well. thanks1 point
-
I can confirm, 6.12.10, also crashing nginx, server unresponsive and the only way to get it back to life is a hard reboot, which then triggers a parity scan1 point
-
It's not measuring RAM, it's showing how much of the docker image file is in use. All three of the non-RAM items are percentage of allocated storage in use.1 point
-
Changed Status to Solved1 point
-
Fixed in 6.12.101 point
-
Hi all, Against better judgement i updated to 6.12.10 RC.1... but for the greater good..... 🙂 All disks present with multiplyer board.. Not found any other issues. regards // Hans1 point
-
Hi, So far so good. No more errors. I will report back later after some more testing1 point
-
I no longer see this issue when rsyncing to a remote smb share on 6.12.10-rc.1.1 point
-
It looks like Freefilesync adds /mnt/user as the source storage by default; this won't pick up the remote shares. You'll have to change that to just /mnt, then you'll be able to access /mnt/remotes from Freefilesync. Using /mnt/user will only give your Unraid shares.1 point
-
You need to install 6.12.10 for the fix.1 point
-
Yes, thank you.1 point
-
v6.12.10 should be out soon with a fix.1 point
-
I have RMAd the CPU and replacement one does not have the issue. Turns out it was a hardware issue after all.1 point
-
Yep, this would be the problem, not the board SATA controller. 6.12.10 should be out soon with a fix.1 point
-
Don't know how I missed that 😳 - thanks, closing.1 point
-
There's a setting to enable mover logging, enable it when needed for troubleshooting then disable afterwards, point is not to have thousands of lines of log spam when nothing's wrong.
 1 point
1 point -
Nope, the liblzma version used in unraid is safe.1 point
-
I downgraded directly to .8.1 point
-
If there was still any remaining doubt, I switched to a 6-port ASM1166 (no port multipliers) and all of my disks show up now after upgrading again.1 point
-
This issue will happen with any Asmedia 1064 with more than 4 ports, or any Asmedia 1166 controller with more then 6 ports, i.e., controllers that use SATA port multipliers, any devices on ports that come from a PM will not be detected, this is a kernel issue, they have already reverted this change but it didn't make to kernel 6.1.x., so possibly LT will need to apply the patches themselves.1 point
-
Yes, it is related to listing files and directories. I occurs with the File Manager in the UD UI and in the cli.1 point
-
Looks to be someone's attempt to prevent a buffer overflow intentionally or unintentionally. I suspect one of the parameters being passed in to the function causes the failure - like the buff_start or end_of_buffer pointers are incorrect. Good find. Thank you.1 point
-
I think on a NAS anytime file sharing capabilities regress that's a major issue.1 point
-
LT is already aware of this, I think they were looking to use rasdaemon for v6.131 point
-
I am able to reproduce the issue. It appears when you remote mount a share from a server that is not another Unraid.1 point
-
Confirmed. Back to 6.12.8 as well.1 point
-
I had thesame issue. Rollback fixed it all. And it wasn't that the episodes werent added to Sonarr, or even Plex, they just literally could not see the files. I had existing random files dissapear aswell from Sonarr, and Plex. Upon investigating i realised that the entirety of Unraid itself could not see, or access those files, as they did not exist for it. Most likely because of this overflow error. Rolling back fixed everything. And plex rescraping those folders showed the extent of the issue as 100's of files were re-added to plex.1 point
-
Do you have the zfs master plugin installed?1 point
-
There's nothing logged in the syslog after 1:30AM, and the server rebooting on its own doesn't sound like an Unraid problem, but try downgrading back to v6.11 and retest.1 point
-
Wait times are how long the system waits after starting the container before starting the next one. In your case it did wait 60 seconds (presumably that's what you had it set to) Jul 6 20:38:31 Liberty rc.docker: plex: started succesfully! Jul 6 20:38:31 Liberty rc.docker: plex: wait 60 seconds ... Jul 6 20:39:31 Liberty rc.docker: telegraf: started succesfully! Why not move plex to the bottom of the start order and the second last container enter in a wait time?1 point
-
Bumping this because it keeps popping up on the forum from time to time, note that it also happens with single parity, if the user tries to add a new disk at the same time as parity or before parity finishes syncing, and while it's just an annoyance it shouldn't be a complicated fix, if parity isn't valid and a new data disk is added give an error that actually gives a clue to the user what the problem is.1 point
-
Directly executing scripts stored on the flash drive is no longer allowed due to security changes The easy workaround though is to change your go file to something akin to bash /boot/path/To/myScript.sh1 point
-
The Samba team has a habit of changing defaults, and in effort to banish SMBv1 looks they they are "encouraging" users to do likewise. https://www.samba.org/samba/history/samba-4.11.0.html We'll have to rethink some config settings but for now this might do the trick: First make sure NetBIOS is enabled in Settings/SMB Next add this to your config/smb-extra.conf file: server min protocol = NT1 if that doesn't work use server min protocol = LANMAN1 (and please post if you have to use LANMAN1 to get it to work)1 point




























