
Xaero
-
Posts
413 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Xaero
-
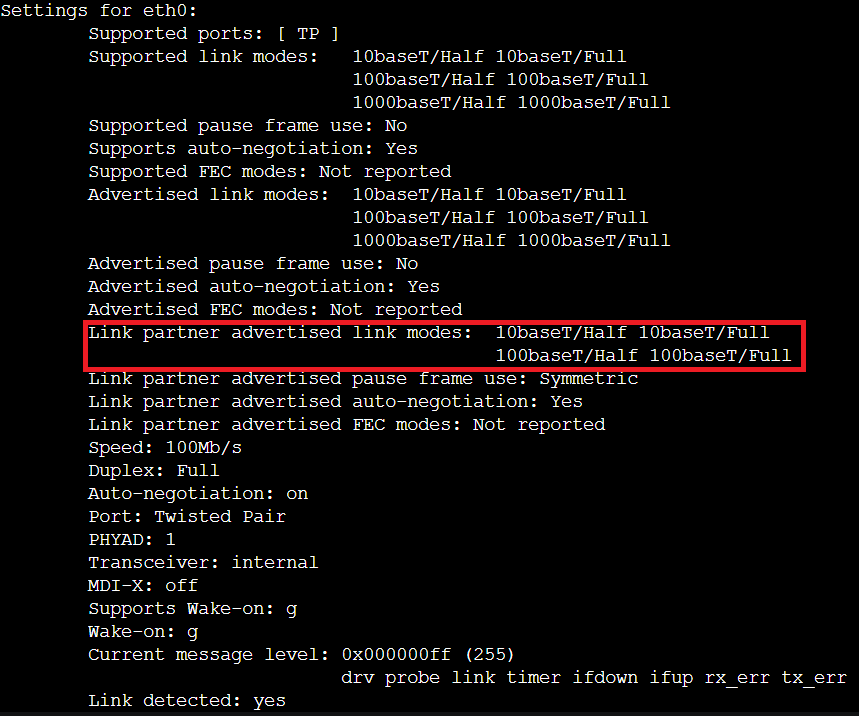
Here's your problem: The partner it is plugged into is saying it only supports 10/100 for some reason. I would double check that it is indeed a gigabit switch, and if it is - I would try a different switch in that position. I'm also working off some assumptions here. It's possible the switch is degrading all links to 10/100 because the upstream link is 10/100, though that isn't common these days. You've already confirmed the card in the server and the cables aren't the problem - the server negotiates a 10/100/1000 link just fine when connected to a different endpoint, so the suspect is the switch, and that output confirms it. The switch is only advertising 10/100. EDIT: I see you say it also does that when plugged into the wall. From the wall termination, where does it go? Is the cable pulled thru the wall good? How long is that run? Has that run been tested with a cable tester? There's lots of questions here. If it works with a short cable directly between two endpoints, then the endpoints are working properly.
-
unRAID 6 NerdPack - CLI tools (iftop, iotop, screen, kbd, etc.)
Xaero replied to jonp's topic in Plugin Support
Would it be possible to add Mame-Tools? Packages exist for Slack. Depends are LibSDL2 and GlibC 2.33 being available for a current version. Mostly desired for CHDMAN. There is a docker for CHDMAN but it has a static script that isn't very flexible for my needs. I'm trying to bulk convert ~10TB+ of archived Bin/Cue & ISO images to CHD since they are directly playable and this would be best suited doing directly on the server (especially since CHDMAN is multithread and I have 48 threads to work with on my unraid box.) I was able to manually install Mame-Tools and SDL2 with upgradepkg --install-new; however the GLIBC available through NerdPack/DevPack and Unraid is too old. I'll try manually installing a new GLIBC and hoping that doesn't break the runtime. If it does a reboot should recover me. Thanks for the consideration EDIT: For now I am rebuilding that container by editing the DockerFile to execute a script that I am binding via -v as a file. This lets me edit the script easily to suit my needs and lets me execute CHDMAN without needing to worry about dependency hell and such. -
Linux Systems Administration. Sysadmins spend a lot of time being intimately familiar with configuration files, packages and their dependencies and resolving conflicts between them. They would be expected to have some familiarity with programming languages (C/C++ generally) as well as being comfortable with a terminal and scripting languages. Modern sysadmins also work with automated deployment systems a lot, things like CHEF/Docker/Kubernetes are going to be premium skills to acquire. This is the field I would like to get into, but never feel confident enough with my skill level to dive right into.
-
It would also be nice to address the color blind accessibility concerns by implementing terminal color profile support. I had a topic on this previously, but it seems heavily related to this since we're talking about readability. I basically am forced to use putty/kitty/ssh in another terminal emulator just so I can have colors that I can see (specifically the folders being light blue on bright green is awful)
-
This would be a question better directed at Plex, rather than unraid. They would be able to confirm what those IPs are for, or if they are foreign. Most likely, however, they are the IPs for the Plex server as the Plex application allows both direct and indirect connections thru their own "proxy" service on their side.
- 1 reply
-
- 1
-

-
For the absolute bleeding edge I'd probably suggest passing thru a thunderbolt PCI-E card and using a fiber optic thunderbolt cable with a thunderbolt dock at the other end. This would give you video outputs and USB inputs for basically raw performance. It's a bit on the expensive side. For the budget oriented I would head in the direction of using Moonlight to access the VM's remotely. This would limit your I/O options a bit, and would introduce some latency (the thunderbolt dock option would be effectively zero latency.) Moonlight has clients on basically every OS imaginable at this point. The KVM/HDMI/USB over IP solutions are also going to be fairly low latency, but they will be heavily limited on what resolutions they support and what I/O they enable. In all cases you will need a "client" box at the display end to handle the display output and I/O. I think some of the fanless braswell units available from china would be attractive moonlight "thin clients" since they would be fairly low cost, silent, and capable of outputting 4k60hz, and decoding 4k60hz natively. In theory you could lower the cost further by buying them barebones with no ram or storage, adding a single 2gb SoDIMM module and setting up a PXE server to hand out the thin client image on unraid. There'd be a lot of legwork involved in that but it would be cheaper and pretty slick.
-
Does anyone have any input on this? Not super familiar with iptables and such; but this seems like the only way to approach it?
-
Reposting my response here so we don't keep bumping that other thread; From diag.zip -> system/ps.txt: nobody 31750 0.3 0.0 0 0 ? Zl May17 4:31 \_ [transmission-da] <defunct> The transmission-da process has become a zombie. Interestingly, the container is using dumb-init which should be handling the zombie process cleanup with a wait() syscall; but doesn't seem to be. Typically this would indicate that the offending zombie process is waiting on IO of some kind. I also note in your syslog that the BTRFS docker image was corrupted (twice) and recreated. I'm assuming a write operation in the docker.img is hanging and when forcibly rebooting the server that's corrupting it. Double check that none of the paths you have mapped to this container are on the docker image. If they are, this could be the culprit as that docker image could be filling up and then write operations just repeatedly failing.
-
Easiest way would be to just bridge all the cards together. A network bridge *is* software level switching. Don't expect good performance with this. Even if your CPU has hardware acceleration for network loads (some xeons) it's going to be substantially slower at the task than the FPGAs used in standard switching applications. It's why routers make poor switches and switches make poor routers. Servers can be pretty good firewalls and routers but they are generally awful switches.
-
You can try Chrome Remote Desktop as well. Video quality suffers from time to time in my experience, and depending on your corporate firewall, DPI might block CRD - though I doubt it if TeamViewer works for you. In my case TeamViewer did the same to me, which is unfortunate because I used to recommend their product - but aggressively flagging power users as "corporate" usage is just an indicator that they just want the cash grab at this point. I ended up breaking down and setting up Apache Guacamole and use RDP with NLA on the server-side of things. (I.E. you enable RDP and NLA in your VM, then add that RDP connection to Guacamole, and expose Guacamole to the internet - preferably with 2FA) Now I not only have secure access to all of my machines remotely - but I'm not using someone else's resources to do it, so I'm not reliant on them not changing the agreement.
-
So I'm trying to set up something slightly more "advanced" in terms of firewalling for the VPN. I have two tunnels configured, one which is only me, and I don't actively use this tunnel intentionally. It's my backup way in. My second tunnel is where all of my actual endpoint users connect. Ideally, I want them to have access to: 10.253.0.1 (Unraid on the Wireguard side), 192.168.252.72 (Unraid on the local LAN side), 192.168.252.254 (Local DNS) and no other local IP addresses. How can I set this up with a blacklist or whitelist? Currently I'm whitelisting the above addresses, but with 0.0.0.0/0 and ::0 in their peer configs, and DNS pointing to 192.168.252.254 the result is they have access to my server, and my DNS - but nothing else on the internet. If I switch to blacklist, I'd have to blacklist each individual IP address (from what I can gather) from 192.168.252.1 - 192.168.252.72 and then from .73 to .253. And then I'd have to repeat that for the wireguard subnet. Is there a simpler way to implement this type of access restriction that I'm overlooking?
-
I'm pretty sure plugins just "don't work" with this container. At least, I haven't been able to get any that aren't pre-bundled with deluge to work.
-
Any chance of adding support for Deluge-RBB plugin for this docker - it would make it infinitely more usable (it adds a browse button to WebUI and remote desktop clients) Currently, if you make no changes it errors out trying to import from common.py. I've tried adding the PYTHONPATH env variable which gets me further, but I stillg et "Cannot import name get_resource" on "from common import get_resource" but I don't see an actual python COMMON.PY anywhere (I see the deluge ones, but none for the actual python package)
-
Is it possible to stop the Unraid WebUI from listening on Wireguard interfaces? For one, since I use SSL - clients that don't have access to the LAN can't see the dashboard anyways; for two I'd like to be able to bind a dashboard docker to the HTTP port for clients that are connected via wireguard. Right now I believe the nginx server is bound to 0.0.0.0 - I'd like to change that to the fixed IP, if possible.
-
You are correct, it is automatic, I went ahead and proceeded blind (never a great idea) and it worked just fine.
-
I'm trying to format my cache drives with 1mb alignment with the new Beta30. I have moved all the data off the cache drives and created a backup, I've stopped the array, and I'm ready to format but my only options are BTRFS and BTRFS encrypted and I don't see a way to adjust the alignment? P.S. I've searche as best I can with Google and the site's search but I keep getting results from 2014 regarding alignment. Solution: Just formatting them automatically resolves the issue.
-
Since all of the errors are with AER and they are all Corrected - it would be safe to disable AER - however, I would not recommend doing so. Instead, since this issue is being triggered when attempting to access the memory mapped PCI Configuration; I would use the kernel option to switch back to legacy PCI Configuration you can do so by adding the following kernel parameter: pci=nommconf This will force the machine to ask the device itself for it's configuration parameters rather than mapping the device's configuration to a memory address. There's a completely negligible performance difference, and this will keep AER enabled, which can improve stability (for example, if an actual error occurs AER might be able to correct it on the fly and not result in a crash)
-
In this particular case, I would use either an Unassigned Device or a second cache pool exclusively for the ingest of these backups. There's a couple of reasons: 1. Wear leveling, and NAND degradation. Repeatedly filling and dumping an SSD is going to kill it. For bulk ingest disks that are constantly dumped to the array I would rather it not by the system cache drives that hold my appdata and such. Even if it's mirrored and/or backed up, when the drive inevitably dies I'd rather it be something I can replace and not have to mess with. 2. You can keep this volume completely empty and buy a disk (or disks) that match the needed capacity. If your needs expand down the road you can simply increase the size of the disk(s) utilized and move on, no need to worry about transferring settings, applications or data to the new disks.
-
Also note that mixed MTU affects inbound (write) performance more than outbound (read) performance. The reason is pretty simple; inbound 9000 MTU packets must be split (fragmented) by the network appliance (switch) before they are transmitted to the client. This nets a rather substantial loss in throughput per packet, and results in increased latency as well. Where as packets transferred by the lower MTU client are less than the frame size, and rather than having to combine or split them, they are just sent with zeroes padding to the right. Latency isn't increased at all, but there is a small (yet measurable) loss in throughput. The performance definitely improved substantially just being able to take advantage of multichannel.
-
You may also need to add: # ENABLE SMB MULTICHANNEL server multi channel support = yes I've not heard of issues using 9000 MTU with docker yet, but I also cannot run 9000 MTU with my current network configuration (my ISP provided modem will not connect above 1500 MTU) There will be significant performance implications if you use MIXED MTU. if everything is 1500 or everything is 9000 then things should be "more or less the same" outside of a large number (thousands) of large sequential transfers (gigabytes) - where the larger MTU will start to pull ahead. With MIXED MTU the problem is that any incoming packets must be fragmented when sent to a client that isn't using the larger MTU. This wastes a ton of resources on the switch or router to accomplish. On the flipside, when the smaller MTU client sends a packet it will use the smaller MTU and the potential overhead savings of the large frame is lost, though this is not as bad of an impact. EDIT: Removed flawed testing, will update later with proper testing again. I'm not on a mixed MTU network atm so I can't actually test this haha.
-
One important thing is that on Windows it's 9014 for Jumbo frames while on Linux the same is 9000 MTU. Setting 9014 MTU on Linux may very well break network connectivity. I would try setting 9000 MTU. Additionally, disable the SMBv1/2 support in Unraid - one of the reasons you are seeing reduced performance on Unraid's SMB implementation is likely because SMB Multichannel is not being utilized with the legacy support enabled. Your Windows 10 VM is using SMB Multichannel and so is your laptop/desktop. Of course iperf should not be impacted by this - but your SMB transfers will be.
-
This largely depends on your location. Most stores in my area that aren't technology-centric start at 16gb as the smallest size now. I also use my thumb drive to store a persistent home folder image, and some other stuff. Even with that though, I've only used 9.7gb/128gb. And I'm only using a 128GB drive for two reasons: It's faster than smaller drives It was free
-
That's not Linuxserver.io - Unraid Nvidia, that's totally different project, by a different creator. My point was to avoid the confusion that I've apparently created anyway. The point being: Currently, with the driver release available with the latest Linuxserver.io Unraid Nvidia plugin release - that driver version is not included.
-
The v6.9.0-beta25 release doesn't include that driver, either.
-
A gentleman - and a scholar. Can't wait for Power State switching to be reliable 🙂 EDIT: to be clear this release doesn't have the beta nvidia driver that fixes the power state. I realized in post this may cause confusion for some sorry.


