Leaderboard


Popular Content
Showing content with the highest reputation on 08/01/21 in all areas
-
I fear the day that the community succeeds and the Limetech staff won't survive these relentless attacks4 points
-
2 points
-
Turbo Write technically known as "reconstruct write" - a new method for updating parity JonP gave a short description of what "reconstruct write" is, but I thought I would give a little more detail, what it is, how it compares with the traditional method, and the ramifications of using it. First, where is the setting? Go to Settings -> Disk Settings, and look for Tunable (md_write_method). The 3 options are read/modify/write (the way we've always done it), reconstruct write (Turbo write, the new way), and Auto which is something for the future but is currently the same as the old way. To change it, click on the option you want, then the Apply button. The effect should be immediate. Traditionally, unRAID has used the "read/modify/write" method to update parity, to keep parity correct for all data drives. Say you have a block of data to write to a drive in your array, and naturally you want parity to be updated too. In order to know how to update parity for that block, you have to know what is the difference between this new block of data and the existing block of data currently on the drive. So you start by reading in the existing block, and comparing it with the new block. That allows you to figure out what is different, so now you know what changes you need to make to the parity block, but first you need to read in the existing parity block. So you apply the changes you figured out to the parity block, resulting in a new parity block to be written out. Now you want to write out the new data block, and the parity block, but the drive head is just past the end of the blocks because you just read them. So you have to wait a long time (in computer time) for the disk platters to rotate all the way back around, until they are positioned to write to that same block. That platter rotation time is the part that makes this method take so long. It's the main reason why parity writes are so much slower than regular writes. To summarize, for the "read/modify/write" method, you need to: * read in the parity block and read in the existing data block (can be done simultaneously) * compare the data blocks, then use the difference to change the parity block to produce a new parity block (very short) * wait for platter rotation (very long!) * write out the parity block and write out the data block (can be done simultaneously) That's 2 reads, a calc, a long wait, and 2 writes. Turbo write is the new method, often called "reconstruct write". We start with that same block of new data to be saved, but this time we don't care about the existing data or the existing parity block. So we can immediately write out the data block, but how do we know what the parity block should be? We issue a read of the same block on all of the *other* data drives, and once we have them, we combine all of them plus our new data block to give us the new parity block, which we then write out! Done! To summarize, for the "reconstruct write" method, you need to: * write out the data block while simultaneously reading in the data blocks of all other data drives * calculate the new parity block from all of the data blocks, including the new one (very short) * write out the parity block That's a write and a bunch of simultaneous reads, a calc, and a write, but no platter rotation wait! Now you can see why it can be so much faster! The upside is it can be much faster. The downside is that ALL of the array drives must be spinning, because they ALL are involved in EVERY write. So what are the ramifications of this? * For some operations, like parity checks and parity builds and drive rebuilds, it doesn't matter, because all of the drives are spinning anyway. * For large write operations, like large transfers to the array, it can make a big difference in speed! * For a small write, especially at an odd time when the drives are normally sleeping, all of the drives have to be spun up before the small write can proceed. * And what about those little writes that go on in the background, like file system housekeeping operations? EVERY write at any time forces EVERY array drive to spin up. So you are likely to be surprised at odd times when checking on your array, and expecting all of your drives to be spun down, and finding every one of them spun up, for no discernible reason. * So one of the questions to be faced is, how do you want your various write operations to be handled. Take a small scheduled backup of your phone at 4 in the morning. The backup tool determines there's a new picture to back up, so tries to write it to your unRAID server. If you are using the old method, the data drive and the parity drive have to spin up, then this small amount of data is written, possibly taking a couple more seconds than Turbo write would take. It's 4am, do you care? If you were using Turbo write, then all of the drives will spin up, which probably takes somewhat longer spinning them up than any time saved by using Turbo write to save that picture (but a couple of seconds faster in the save). Plus, all of the drives are now spinning, uselessly. * Another possible problem if you were in Turbo mode, and you are watching a movie streaming to your player, then a write kicks in to the server and starts spinning up ALL of the drives, causing that well-known pause and stuttering in your movie. Who wants to deal with the whining that starts then? Currently, you only have the option to use the old method or the new (currently the Auto option means the old method). But the plan is to add the true Auto option that will use the old method by default, *unless* all of the drives are currently spinning. If the drives are all spinning, then it slips into Turbo. This should be enough for many users. It would normally use the old method, but if you planned a large transfer or a bunch of writes, then you would spin up all of the drives - and enjoy faster writing. Tom talked about that Auto mode quite awhile ago, but I'm rather sure he backed off at that time, once he faced the problems of knowing when a drive is spinning, and being able to detect it without noticeably affecting write performance, ruining the very benefits we were trying to achieve. If on every write you have to query each drive for its status, then you will noticeably impact I/O performance. So to maintain good performance, you need another function working in the background keeping near-instantaneous track of spin status, and providing a single flag for the writer to check, whether they are all spun up or not, to know which method to use. So that provides 3 options, but many of us are going to want tighter and smarter control of when it is in either mode. Quite awhile ago, WeeboTech developed his own scheme of scheduling. If I remember right (and I could have it backwards), he was going to use cron to toggle it twice a day, so that it used one method during the day, and the other method at night. I think many users may find that scheduling it may satisfy their needs, Turbo when there's lots of writing, old style over night and when they are streaming movies. For awhile, I did think that other users, including myself, would be happiest with a Turbo button on the Main screen (and Dashboard). Then I realized that that's exactly what our Spin up button would be, if we used the new Auto mode. The server would normally be in the old mode (except for times when all drives were spinning). If we had a big update session, backing up or or downloading lots of stuff, we would click the Turbo / Spin up button and would have Turbo write, which would then automatically timeout when the drives started spinning down, after the backup session or transfers are complete. Edit: added what the setting is and where it's located (completely forgot this!)1 point
-
In the settings of the docker there's a field called "License key". Put your key there, (or BETA for beta). There always seems to be a lag at the first of the month, though, in getting the app to recognize the beta key or get the new version.1 point
-
Please download the the package for Slackware 14.2 not for current please.1 point
-
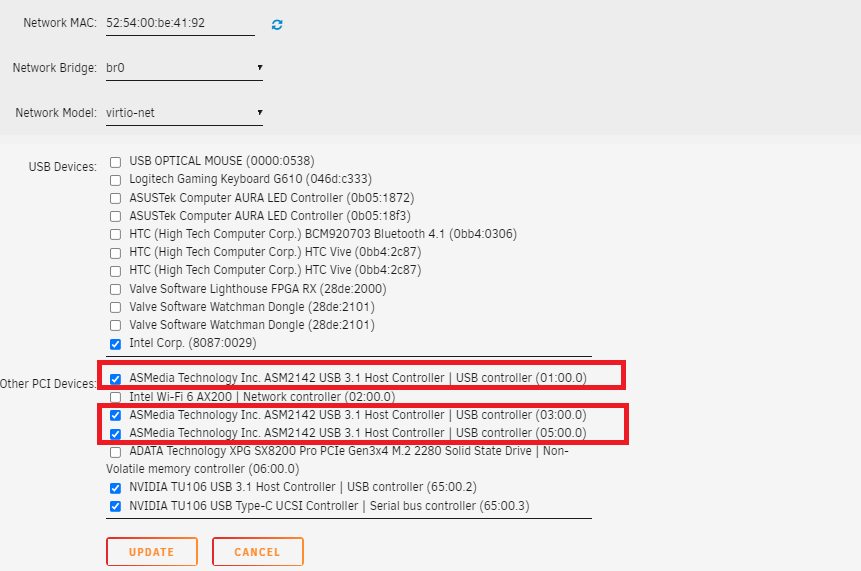
Danke für eure Antworten. Laut System hab ich wohl 3 USB Conroller (Immou-Grupppe). Habe diese nun mal ausgewählt und werde das testen. PS: OK jetzt geht nichts mehr ^^ Die VM meckert als was von unkonwn PCIe device und meine Tastatur wird während des Starts von UnRaid nicht mehr angesprochen (die RPGs bleiben dunkel)? Das soll man jetzt verstehen ^^ ? PPS: Jetzt ist meine VM ganz weg und nur meine zweite ist zu sehen WTF? Ich glaube ich mache nochmal alles neu ^^
 1 point
1 point -
@Meliodases geht nicht um die Ports...USB ist ein Bussystem, Es geht zunächst um die Anzahl der USB-Controller und dann wie die Ports darauf verteilt sind. Je nach MB hast Du 1 oder 2 USB-Controller, welche (evtl.) auch eine eigene IOMMU-Gruppe haben (zB für USB3.x und 2.x) Dann kannst Du die auch einzeln an VMs durchreichen...in unRaud UI -> Tools -> system devices - IOMMU-groups. Findest Du dort 2 USB controller, dann los. Sonst einen mit ner Karte nachrüsten oder USBIP versuchen, wie @SimonFoben schon schrieb. Welche USB-Geräte an welchen Bus hängen, siehst Du mit einem "lsusb -t"...nie den bus mit dem unraid Stick mittels vt-d verschieben1 point
-
Tut mir leid, spreche kein Deutsch, ist auf USB 2.0-Controllertyp eingestellt, so können nur 3 Benutzergeräte für bis zu 14 auf USB3 wechseln. Mein Plugin unterstützt denselben Anbieter. schau mal auf der Support-Seite vorbei. Google Übersetzer.1 point
-
schonmal versucht alle USB Geräte auf einen Controller zu stecken und diesen dann komplett per vt-d an die VM zu reichen? Darf natürlich nicht der Controller sein, wo der unRaid Stick drauf ist Notfalls einen dedizierten USB-Controlelr per PCIe Karte nachrüsten.1 point
-
The diagnostics you ported earlier had this in the SMART report for disk6 197 Current_Pending_Sector -O---K 100 100 000 - 12600 so I would say that disk is very sick and needs to be replaced. The syslog also backs this up with lots of errors being reported for that drive.1 point
-
I understand the hack violates the EULA, but I'm curious about how Hyper-V can now support GPU-P which accomplishes the same thing (on both Nvidia and AMD) without creating issues with licensing. We might get lucky and similar changes get adopted in KVM. Another video from Jeff for context 😛1 point
-
None of the elements you attached are available, can you try again ? Just to be sure, you are on 6.9.2 ? If so, a moderator will move the post to the appropriate sub-forum.1 point
-
Moin mgutt, danke für deine hilfe wenn ich UnRaid neu starte bekomme ich info sehe --> Screenshot SMART Werte root@UnRaid:~# smartctl -A /dev/sdf smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.10.28-Unraid] (local build) Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 083 064 006 Pre-fail Always - 184740262 3 Spin_Up_Time 0x0003 091 091 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 39 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 072 060 045 Pre-fail Always - 17420699 9 Power_On_Hours 0x0032 099 099 000 Old_age Always - 1537 (53 79 0) 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 16 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 099 000 Old_age Always - 1 1 1 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 040 035 040 Old_age Always FAILING_NOW 60 (Min/Max 60/60 #628) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 2 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 445 194 Temperature_Celsius 0x0022 060 065 000 Old_age Always - 60 (0 23 0 0 0) 195 Hardware_ECC_Recovered 0x001a 083 064 000 Old_age Always - 184740262 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 771h+16m+21.230s 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 32827230064 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 16652753490 SpinDown /dev/sdf: drive state is: standby SpinUP /dev/sdf: drive state is: active/idle Muss sagen wenn ich UnRaid neu starte, array anbinde, und nur den ruTorrent CT starte der auch nur auf die SDF1 zugewiesen ist läuft alles, ohne Probleme. Starte jetzt nach und nach andere CT NginxProxyManager --> rennt, keine Probleme mit SDF1 Bitwarden --> rennt, keine Probleme mit SDF1 Jellyfin --> rennt, keine Probleme mit SDF1 Info erhalten --> Screenshot hat aber nichts mit dem start von Jellyfin zu tun nehme ich an da dieser auf SDF nicht zugreift, (hatte nebenbei einen 11GB Torrent am Laden um zu testen das in der zeit etwas geschieben wird auf die SDF1) Windows 11 VM Gestartet = gleiche Problem Festplatte ist ausgefallen, somit musste ich bei den Windows 11 Einstellungen nachschauen, und Voila warum auch immer habe ich die SDF Platte auch dem Windows 11 zugewiesen so das es auch über USB erreichbar sein soll bei Windows 11 keine ahnung warum da der Haken an war siehe --> Screenshot hab den Haken da rausgenommen, UnRaid & Windows 11 erneut gestartet läuft alles wieder, Festplatte doch nicht Löffel abgegeben juhuu Danke für euren Hilfen. cYa BUSTER1 point
-
Version 6.10.0 beta25a 2021.07.271 point
-
@bat2o if it works externally and you try to access your nextcloud from the same LAN with your DuckDNS URL then maybe DNS-Rebind Protection / DNS Hairpinning (nat loopback) on your router/firewall can help you.1 point
-
I disagree. Recently since my last upgrade to a private beta release one of the lights on my garage door opener has started flickering. I refuse to believe that it's a coincidence.1 point
-
Da die Fehler wirklich überall auftauchen, sogar direkt im Boot-Bereich der HDD, würde ich sagen, dass das nicht an der HDD liegt, sondern eher am Kabel / der Verbindung: Jul 31 13:22:26 UnRaid emhttpd: shcmd (498): /usr/sbin/cryptsetup luksClose md5 Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=0 Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=16 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 2, async page read ### [PREVIOUS LINE REPEATED 1 TIMES] ### Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=32 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 4, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=64 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 8, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=128 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 16, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=256 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 32, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=512 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 64, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=1024 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 128, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=2048 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 256, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=4096 Jul 31 13:22:26 UnRaid kernel: Buffer I/O error on dev md5, logical block 512, async page read Jul 31 13:22:26 UnRaid kernel: md: disk5 read error, sector=8192 Jul 31 13:22:26 UnRaid emhttpd: shcmd (499): /usr/sbin/cryptsetup luksClose sdg1 Jul 31 13:22:26 UnRaid kernel: mdcmd (43): stop Dass keine SMART-Werte in den Logs stehen, ist auch komisch. So als könnte Unraid diese nicht wegen USB auslesen. Führe mal über das Web Terminal das Kommando aus, um dir die SMART Werte anzeigen zu lassen: smartctl -A /dev/sdf Nun versetz die Disk in den Spindown und check mit dem Kommando den Power-State: hdparm -C /dev/sdf Hier aus deinem Report die SMART Werte. Die sind wichtig und stehen alle auf Null: 5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0 7 Seek_Error_Rate -OSR-K 200 200 000 - 0 196 Reallocated_Event_Count -O--CK 200 200 000 - 0 197 Current_Pending_Sector -O--CK 200 200 000 - 0 198 Offline_Uncorrectable ----CK 200 200 000 - 0 Der hier bezieht sich auf die Verbindung zwischen Mainboard und HDD: 199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 21 Diesen gilt es zu beobachten. Der sollte nicht weiter steigen, weil das sonst bedeutet, dass weiterhin ein Verbindungsfehler vorhanden ist. Meine Glaskugel sagt bis hier hin, dass USB schlafen geht und die Verbindung zur Platte kurz komplett weg ist. Nutzt du Stromsparmechanismen im BIOS oder hast du in Unraid powertop installiert oder sonst irgendwas in der Richtung eingestellt? Dann allgemein: Verschlüsselung und USB und Array und kein Backup (?) sind eine ganz böse Kombination.1 point
-
Yeah I've never hit my seed max and I get "credit" for it being "available" to download. I thought about the above as well as I was typing and may give it a shot. I'm already seeding close to 3TB of files. I was just thinking about cache pools since it can be added to but it may be better going back to the array. Thanks Tristankin1 point
-
Sorry but there is very little I can suggest other than posing on Plex support and hoping somebody has an idea on how to fix it. Sent from my CLT-L09 using Tapatalk1 point
-
This should be theoreticaly possible, you have to create the map on your PC and then copy it over to the container with all needed files.1 point
-
Same error on my 6.9.2 box after the latest container update. Looks like there is already a GitHub issue targeting a fix in Glances 3.2.3 release: https://github.com/nicolargo/glances/issues/1905. Workaround would be to add a version tag to the container config like this:
 1 point
1 point -
Done.1 point














