




goldbondx
Members
-
Joined
-
Last visited
Everything posted by goldbondx
-
What is the status with noted error previously: 2026/05/19 10:14:33 [DEBUG] Default SQLite driver initialized 2026/05/19 10:14:33 [ERROR] unable to load config, waiting 5 seconds before exiting... 2026/05/19 10:14:38 [FATAL] error unmarshaling YAML data: [136:3] unknown field "defaultLandingPage" 133 | darkMode: true 134 | dateFormat: false 135 | debugOffice: false > 136 | defaultLandingPage: "" ^ 137 | deleteWithoutConfirming: false 138 | disableOfficePreviewExt: "" 139 | disableOnlyOfficeExt: .md .txt .pdf 140 | I came back to a previously work but upgraded version I hadn't used in a bit and received this. I reinstalled and have the same error. Update: Commented out offending lined relating to defaultLandingPage and appear to be up and running.
-
So, I see a Booklore back on Github and Grimmory has been giving me some issues on upgrades like this evening again. (3.0) Error: Updated to 3.0.0 tonight on Unraid Docker and all library paths are showing as "inaccessible". Looked at the log files and this error comes up at restart: 2026-04-22T20:40:13.521-04:00 INFO 1 --- [booklore-api] [MessageBroker-1] o.s.w.s.c.WebSocketMessageBrokerStats : WebSocketSession[0 current WS(0)-HttpStream(0)-HttpPoll(0), 0 total, 0 closed abnormally (0 connect failure, 0 send limit, 0 transport error)], stompSubProtocol[processed CONNECT(0)-CONNECTED(0)-DISCONNECT(0)], stompBrokerRelay[null], inboundChannel[pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 0], outboundChannel[pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 0], sockJsScheduler[pool size = 2, active threads = 1, queued tasks = 0, completed tasks = 0] And, this error comes up attempting to access library/books: 2026-04-22T20:44:57.573-04:00 ERROR 1 --- [booklore-api] [ async-14] o.b.s.library.LibraryProcessingService : Library path not accessible: /books/fiction Are we changing back to Booklore again? Update: I don't know what is going on but it looks like I lost or didn't have a share to the books collection.
-
Would it be simpler to just chown on the image folder to allow writes given everything else seems to work? (at least that is what AI is suggesting) And if so, to what? The issue seems to be writing of book covers. (and other images) Update: I deleted the 2 entries you suggested I remove and now it seems to work..messed up. mind boggling but happy nonetheless..
-
I changed the repository from Booklore to Grimmory and all seems to work except I cannot write covers it seems to /image folder: 2026-04-02T06:56:07.299-04:00 WARN 1 --- [booklore-api] [mcat-handler-79] o.b.s.metadata.BookMetadataUpdater : Failed to download cover for book 22414: Error reading files from path: Failed to create directory: /app/data/images/22414 2026-04-02T06:56:11.129-04:00 INFO 1 --- [booklore-api] [MessageBroker-1] o.s.w.s.c.WebSocketMessageBrokerStats : WebSocketSession[3 current WS(3)-HttpStream(0)-HttpPoll(0), 3 total, 0 closed abnormally (0 connect failure, 0 send limit, 0 transport error)], stompSubProtocol[processed CONNECT(3)-CONNECTED(3)-DISCONNECT(0)], stompBrokerRelay[null], inboundChannel[thread-per-task], outboundChannel[thread-per-task], sockJsScheduler[pool size = 1, active threads = 1, queued tasks = 0, completed tasks = 0] I have added the group and user ID as instructed and performed the chown as instructed. Any help would be appreciated.
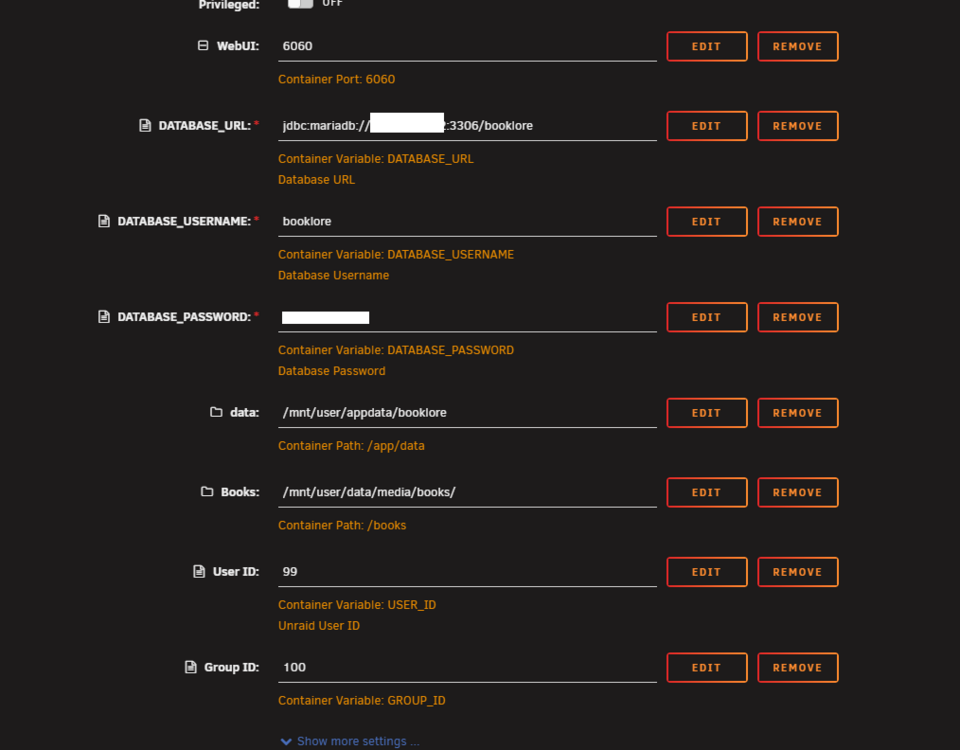
-
Thanks @bmartino1 . I am very hesitant to jump into scripts. However, this gave me some ideas where to start researching more. 1 comment I have as I continue to troubleshoot. GPU statistics are hammering 1-2 CPU cores (100%) like clockwork every 2-4 seconds. I verified this when I uninstalled gpu statistics plugin. The CPU usage went to <1 and stayed that way until I reinstalled and selected my RTX3070. Then the 1-2 CPU cores started bouncing to 100% again like clockwork. I have deselected my card in GPU statistics and seems to have stabilized. I will start up the array and monitor for several hours. It appears occurrences of [WARNING] [pool www] server reached max_children setting (50), consider raising it are indeed tied to load of Dashboard (specifically Main) in browser. Only occurrences thus far are tied to refresh or tab changes as I monitor real-time.
-
OK it has been 3 days after removing unassigned drive and unassigned drive plus with no max_children message that I can see. That said, still flooded with avahi_key_new() failed. Moving on.. Update: So, I started tackling the Avahi error and low and behold the max_children error came back. All I did was rename a share with a blank in it, and it seem to come up during some additional log info. This didn't exist before these last updates leading to 7.2.3. I don't know what is going on and not deep enough skills to fix them. What I do know, I am not the only 1 to report these problems.
-
I suspected that was the case and you indirectly confirmed that removal is only option. Thanks for the quick reply.
-
Removed my last post. I am not sure anymore on DelugeVPN as it seems this warning (max_children) popped up on every login as you suspected. It is somewhat inconsistent. One critical follow-up question. Plug-ins are remove only. There is no ability to "disable" as mentioned? I tried removing Unassigned Devices as a test and received this: Dec 29 11:40:41 mcunraid nginx: 2025/12/29 11:40:41 [error] 12364#12364: *109459 FastCGI sent in stderr: "Unable to open primary script: /usr/local/emhttp/plugins/unassigned.devices.preclear/include/Preclear.php (No such file or directory)" while reading response header from upstream, client: 1<Desktop Client IP>, server: , request: "POST /plugins/unassigned.devices.preclear/include/Preclear.php HTTP/2.0", upstream: "fastcgi://unix:/var/run/php-fpm.sock:", host: "<Unraid IP>", referrer: "https://<Unraid IP>/Plugins" ....... php-fpm[12253]: [WARNING] [pool www] server reached max_children setting (50), consider raising it I quickly re-added the plug-in successfully. I don't use NGINX at all. I access my server ext by VPN only. There is no reverse proxy. Hesitant to go any deeper as do not feel my skills follow your entire recommendations.
-
Thanks for the quick reply on. The USB issue was dealt with. External drive bay (5 TB) that is failing regularly. It's garbage and throwing it out. Unfortunately, the errors were still happening even after reboot it looks like. I'll keep an eye. The big issue trying to mitigate is item 1 (and 2) and thanks for clarifying root cause. I was unsure if GUI or something deeper. I wanted to confirm nothing that would impact data/writes. Item B seems like a good choice to start and eliminate polling culprits. I do have a bunch of dashboard elements as you mention. I'll be honest. My Linux skills are limited. I have never touched NGINX and hesitant to mess around with the pm.max_requests or slowlog. Will do a bit more research. My only remaining question. I haven't had any issues with this error up until the last 2 updates to OS. The only thing I have done is regular updates to Dockers and added FileBrowser Quantum. What could have introduced this?
-
Would appreciate any help here as getting similar/same error since 7.2.2. Only thing that has really changed in past couple of months: OS upgrade, FileBrowser Quantum installed, Regular Docker and Unraid Connect upgrades. Rebooted ~a day ago. I do have a few things going on but figured I would start with this error which is becoming more frequent.
-
Same.
-
7.2.2 and this just showed up: (4 times in recent log) - RTX 3070 / Nvidia Driver Version: 580.119.02 / GPU statistics is present/enabled. server reached max_children setting (50), consider raising it Seems tied to JF playback. Coincidentally (or not) was dealing with this issue just prior to: NVRM: GPU 0000:01:00.0: RmInitAdapter failed! (0x22:0x51:884) This seemed to fix itself with a NVIDIA driver update and reboot. Is there some underlying video card/vram/driver issue I am missing that has cropped up recently?
-
I changed signup: true and reloaded the docker in order to allow new user sign-up. I confirmed showing in yaml. Doesn't seem to do anything. Am I missing something relating to signup? Update can you post the actual settings and full path syntax that are suggested? Do these settings look right? Seems to be a relative path with another config.yaml below data but not a complete list of settings:
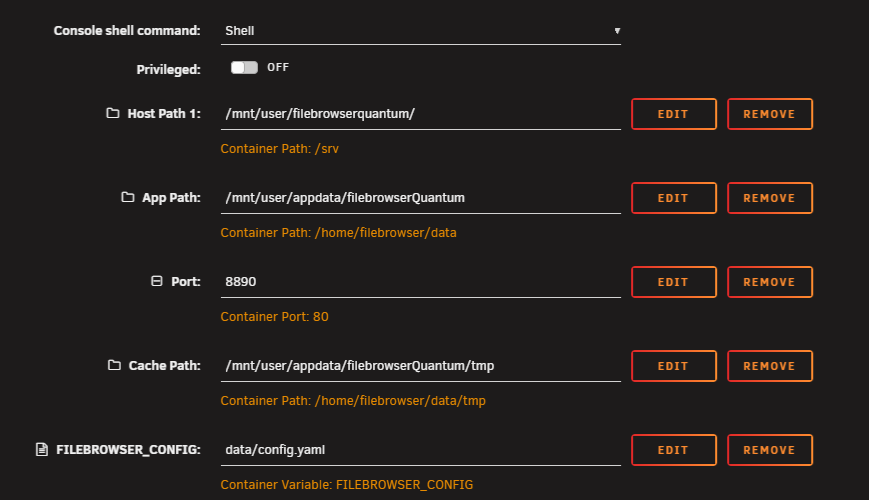
-
I can confirm this is busted as of today's build. It is indicating the password is missing for Proton. (when it has not been changed for over 5 months) I'll try rolling back as well. https://github.com/qdm12/gluetun/issues/2992
-
I am receiving the same error. I searched and found this: https://github.com/Kareadita/Kavita/issues/2248 However, the problem doesnt' seem resolved on our build? (v0.7.13) Was your issue on PDF's? Did you find a fix?
-
I just had the exact same issue post 6.12.6 upgrade where the drive information on main was blank. The unraid "busy" logo was flashing in the Disk Devices section. The drives were accessible via docker and navigation. I have rebooted and the problem appears to have gone away. The only thing I could see as "different" in my env was the fact I had an externally mounted usb 3.0 16 TB drive that didn't seem to populate dir listings correctly when navigating through krusader. I powered it off before restarting the 2nd time just to be safe.
-
2 updates were pushed within the past 2 weeks (1 last night for me..) Any idea what was in them?
-
Thank you for the quick reply. Diagnostics attached: I restarted to produce updated diagnostics and it looks like the update completed correctly. Weird but satisfied. Thank you.
-
Unraid 6.12.4. I have been unable to update the NVIDIA driver since 535.113.01. I have tried to update to both latest: v545.29.02 and Production Branch: v535.129.03 and rebooted in all cases. No joy. Still stuck on 535.113.01. Warning msg: Nvidia Driver: 12-11-2023 18:15 Notification To install the new Nvidia Driver v545.29.02 please reboot your Server!
-
I know it sounds easy and I was reasonably successful with NEXTCLOUD doing same. However, this is a little above my paygrade. But, thank you for pointing out this is possible. Will research steps to take to achieve. BTW fantastic work on this. Almost dumped entire family recipe catalog.
-
Sorry if related to previous question I see here. Trying to figure out how to store to external share as I am using many recipe images that are blowing up the size of the docker container. I would like my data on a separate share outside of appdata. Is this feasible? What process would you recommend for migrating the current db if so?
-
I think I have everything setup correctly minus HTTPS as I don't care with Nextcloud only available on internal and/or VPN. I am stuck at facial recognition stuck at: Faces scan started to work and saw the count going up. However, no faces found for either of 3 accounts. Any tips/tricks to offer?
-
OMG..yep that's a big DER on my part..sorry! AllTheMods9. It just doesn't install correctly and the only failure I can see is what I posted. I have only had the server running on 6.12.3 for about a month. But, it worked flawlessly. Whatever happened during the double update 2-3 days ago seems to have caused some grief. Update - I think I found the root cause/issue. I had ATM9 running on 25566 for about a month. Decided to go with default 25565 and I am back in business. - Fixed and Fixed now!
-
Sor Sorry for delay on the java version. I have tried forcing update multiple times but same effort occurs. Server eventually cacs. 7/19 - I even tried completely removing the docker and reinstalling from scratch and I receive the same error. Server will not start/load. I ensure folder was removed prior to re-install.
-
I was prompted for 2 updates today that came in within the last 24 hours. Something went wrong somewhere: [13:27:14] [main/WARN] [minecraft/Main]: Failed to load datapacks, can't proceed with server load. You can either fix your datapacks or reset to vanilla with --safeMode Sever won't start and hoping there is a quick fix/suggestion. Thanks.


