




MowMdown
Members
-
Joined
-
Last visited
Everything posted by MowMdown
-
You should be able to choose any filesystem type including the encrypted options, you just have to stop the array, erase the data partition, then click on "cache" and select xfs-encrypted from the filesystem menu, then go back and start the array and check the format box Just make sure you move your data out of the cache data partition before you do this.
-
Please post diagnostics too
-
You can only format the "data" partition of a single boot disk pool to encrypted xfs, if your boot pool consists of two disks, your only options are encrypted btrfs or zfs. the boot partition cannot be encrypted or changed from zfs.

-
considering unraid is not a full fledged linux distribution, your mileage may vary with installing such packages if their dependencies are not found. If you really insist on having those you need to find them on slackware's package site and you can place the .tar.gz file under /boot/extra on the boot USB/disk and unraid will extract and install them on each boot.
-
It appears that disk2 connection issues have been corrected, I dont see any connection issues in the new logs but now you need to repair the filesystem Stop the parity check. Stop the array. Check the "Maintenance Mode" checkbox, then click start array. Once array is started in maintenance mode, click on disk2, then click the check filesystem button, and report back once it finishes. (you can find further information by clicking on the underlined text) Note: If it cannot find a superblock after a few hours, it likely wont find one and you can stop the filesystem check.
-
Unraid is now very strict about the partition created on the USB drive. You may need to back it up and re-create it, then restore the config folder. This can be addressed later.
-
check and replace the cables on disk2 "WD40EZAX-00C8UB0" and post new diagnostics
-
It is new yes.
-
I really advise against installing plugins outside of CA as there is no validity to those plugins. Considering they run directly on your system.
-
you need to check your driver version, p2000 needs to be on nvidia 585 or lower to function.
-
In my opinion this plugin causes more problems than it solves.
-
Well unraid parity is more like RAID4 but without data striping of any kind. Each disk in the unraid array remains an individual filesystem. RAID1 is just a mirror of two drives which act as a single unit. If you need more technical details I highly suggest reading the unraid documentation as it explains it in detail.
-
You created two btrfs raid1 pools. If you wanted to use the unraid array you should have instead added the disks to the array slots above the pool section when the array is stopped. Btrfs goes into degraded mode when you pulled a disk, however it was likely in the process of rebalancing itself to single mode before you interrupted it. Please refer to the docs: https://docs.unraid.net/unraid-os/using-unraid-to/manage-storage/cache-pools/#removing-disks-from-a-pool To fix this you need to start the array with both disks assigned, let it rebalance back into RAID1 mode. Once that’s done you can remove ONE of the disks, set the slot to “missing” and start the array. Then it will once again balance into SINGLE mode. It will display degraded until the process is complete. You can check the balance status by clicking on the pool name “data” or opening the console/terminal and typing in btrfs balance status /mnt/data
-
Make sure Fastboot is disabled Check boot drive order in the BIOS to make sure it's booting off the correct device See if there is a BIOS update It cant be related to updating the OS if the OS doesnt even load which it sounds like it's not.
-
Might be worth a read? https://www.1password.dev/connect/get-started
-
UGreen DXP2800 has TPM 2.0 so if the USB device doesnt, OP has a backup fallback option. (source I own a dxp2800 running unraid)
-
Either: You have SAS disks that dont like spin-downs You have plugins reading/polling disks You are running VMs/Docker containers reading/writing to the disks. SMB/NFS client connections waking disks up to read contents. Boot into SAFE MODE, disable docker and VM services from the settings menu, and observe the disks.
-
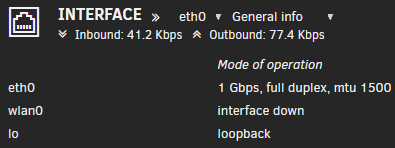
You need to check your entire network from start to finish to make sure it is all fully capable of supporting 2.5Gbps, Modem/Router, Cables, NIC, Switches, whatever you are using. All of it has to support 2.5Gbps. If you're using a commercial VPN service, you're likely capped at 1Gbps over the VPN. What does your network widget report?
-
It appears that rebar is required for the intel ARC GPUs to function in any capacity on linux. This is due to intel and the drivers more than unraid.
-
It either is one of those two containers (or both) or it's something else reading from the drives like SMB network shares or a terminal or a script. Something is reading the disks, you will have to figure out what it is. You also have a lot of shares that are set to use a pool only and files/folders exist on the array disks. For example your "system" share.
-
need more info, how is your storage assigned in unraid? Array + Parity? Zpool? btrfs pool? combination?
-
My guess is it was one of these. Not sure really what cache dirs does to keep disks awake but if it's doing reads over and over... file integrity will keep disks awake during it's scanning and hashing of files ZFS master will keep zfs disks spun up if you have the refresh setting enabled for snapshots and datasets
-
best way to see what disk(s) are causing the slowness is to use the disk speed docker container to benchmark them. Your 3TB disks are likely the reason why, they’re probably older tech and just generally slow overall. Your parity check will likely speed up after 3TB.
-
Yeah I think having it set to 1GB was likely your issue, I dont see anything else that would cause this. 0----------------------------------4 # Share does not exist appdata shareUseCache="no" # Share exists on disk1, disk2, disk3, disk4, disk5 a-----e shareUseCache="no" # Share exists on disk5 b----p shareUseCache="no" # Share exists on disk5 c-----s # Share exists on disk5 domains shareUseCache="no" # Share exists on disk1 G---s shareUseCache="no" # Share exists on disk4, disk5 isos shareUseCache="no" # Share exists on disk5 M--------d shareUseCache="no" # Share exists on disk4, disk5 N---------e shareUseCache="no" # Share exists on disk1, disk2, disk3, disk4, disk5 P-------a shareUseCache="no" # Share exists on disk1, disk2, disk3, disk4, disk5, disk6 S---h shareUseCache="no" # Share exists on disk1, disk2, disk3, disk4, disk5, disk6 S------R shareUseCache="no" # Share exists on disk1, disk2, disk3 system shareUseCache="no" # Share exists on disk1 t-------------------4 # Share does not exist t-------------------------f # Share does not existYou can see two of your shares do have data on disk6
-
Would you be willing to share a screenshot of your dashboard and post the diagnostics?





