Leaderboard



Popular Content
Showing content with the highest reputation on 06/24/21 in all areas
-
Makes sense. Looks like I have disabled most of the docker logs at this point, got to give it a day to see the results to see what effect it has on writes. Then I will start disabling healthchecks and see what improvement that has.3 points
-
Turbo Write technically known as "reconstruct write" - a new method for updating parity JonP gave a short description of what "reconstruct write" is, but I thought I would give a little more detail, what it is, how it compares with the traditional method, and the ramifications of using it. First, where is the setting? Go to Settings -> Disk Settings, and look for Tunable (md_write_method). The 3 options are read/modify/write (the way we've always done it), reconstruct write (Turbo write, the new way), and Auto which is something for the future but is currently the same as the old way. To change it, click on the option you want, then the Apply button. The effect should be immediate. Traditionally, unRAID has used the "read/modify/write" method to update parity, to keep parity correct for all data drives. Say you have a block of data to write to a drive in your array, and naturally you want parity to be updated too. In order to know how to update parity for that block, you have to know what is the difference between this new block of data and the existing block of data currently on the drive. So you start by reading in the existing block, and comparing it with the new block. That allows you to figure out what is different, so now you know what changes you need to make to the parity block, but first you need to read in the existing parity block. So you apply the changes you figured out to the parity block, resulting in a new parity block to be written out. Now you want to write out the new data block, and the parity block, but the drive head is just past the end of the blocks because you just read them. So you have to wait a long time (in computer time) for the disk platters to rotate all the way back around, until they are positioned to write to that same block. That platter rotation time is the part that makes this method take so long. It's the main reason why parity writes are so much slower than regular writes. To summarize, for the "read/modify/write" method, you need to: * read in the parity block and read in the existing data block (can be done simultaneously) * compare the data blocks, then use the difference to change the parity block to produce a new parity block (very short) * wait for platter rotation (very long!) * write out the parity block and write out the data block (can be done simultaneously) That's 2 reads, a calc, a long wait, and 2 writes. Turbo write is the new method, often called "reconstruct write". We start with that same block of new data to be saved, but this time we don't care about the existing data or the existing parity block. So we can immediately write out the data block, but how do we know what the parity block should be? We issue a read of the same block on all of the *other* data drives, and once we have them, we combine all of them plus our new data block to give us the new parity block, which we then write out! Done! To summarize, for the "reconstruct write" method, you need to: * write out the data block while simultaneously reading in the data blocks of all other data drives * calculate the new parity block from all of the data blocks, including the new one (very short) * write out the parity block That's a write and a bunch of simultaneous reads, a calc, and a write, but no platter rotation wait! Now you can see why it can be so much faster! The upside is it can be much faster. The downside is that ALL of the array drives must be spinning, because they ALL are involved in EVERY write. So what are the ramifications of this? * For some operations, like parity checks and parity builds and drive rebuilds, it doesn't matter, because all of the drives are spinning anyway. * For large write operations, like large transfers to the array, it can make a big difference in speed! * For a small write, especially at an odd time when the drives are normally sleeping, all of the drives have to be spun up before the small write can proceed. * And what about those little writes that go on in the background, like file system housekeeping operations? EVERY write at any time forces EVERY array drive to spin up. So you are likely to be surprised at odd times when checking on your array, and expecting all of your drives to be spun down, and finding every one of them spun up, for no discernible reason. * So one of the questions to be faced is, how do you want your various write operations to be handled. Take a small scheduled backup of your phone at 4 in the morning. The backup tool determines there's a new picture to back up, so tries to write it to your unRAID server. If you are using the old method, the data drive and the parity drive have to spin up, then this small amount of data is written, possibly taking a couple more seconds than Turbo write would take. It's 4am, do you care? If you were using Turbo write, then all of the drives will spin up, which probably takes somewhat longer spinning them up than any time saved by using Turbo write to save that picture (but a couple of seconds faster in the save). Plus, all of the drives are now spinning, uselessly. * Another possible problem if you were in Turbo mode, and you are watching a movie streaming to your player, then a write kicks in to the server and starts spinning up ALL of the drives, causing that well-known pause and stuttering in your movie. Who wants to deal with the whining that starts then? Currently, you only have the option to use the old method or the new (currently the Auto option means the old method). But the plan is to add the true Auto option that will use the old method by default, *unless* all of the drives are currently spinning. If the drives are all spinning, then it slips into Turbo. This should be enough for many users. It would normally use the old method, but if you planned a large transfer or a bunch of writes, then you would spin up all of the drives - and enjoy faster writing. Tom talked about that Auto mode quite awhile ago, but I'm rather sure he backed off at that time, once he faced the problems of knowing when a drive is spinning, and being able to detect it without noticeably affecting write performance, ruining the very benefits we were trying to achieve. If on every write you have to query each drive for its status, then you will noticeably impact I/O performance. So to maintain good performance, you need another function working in the background keeping near-instantaneous track of spin status, and providing a single flag for the writer to check, whether they are all spun up or not, to know which method to use. So that provides 3 options, but many of us are going to want tighter and smarter control of when it is in either mode. Quite awhile ago, WeeboTech developed his own scheme of scheduling. If I remember right (and I could have it backwards), he was going to use cron to toggle it twice a day, so that it used one method during the day, and the other method at night. I think many users may find that scheduling it may satisfy their needs, Turbo when there's lots of writing, old style over night and when they are streaming movies. For awhile, I did think that other users, including myself, would be happiest with a Turbo button on the Main screen (and Dashboard). Then I realized that that's exactly what our Spin up button would be, if we used the new Auto mode. The server would normally be in the old mode (except for times when all drives were spinning). If we had a big update session, backing up or or downloading lots of stuff, we would click the Turbo / Spin up button and would have Turbo write, which would then automatically timeout when the drives started spinning down, after the backup session or transfers are complete. Edit: added what the setting is and where it's located (completely forgot this!)1 point
-
no issues, and qemu already supports tpm 2.01 point
-
Gut, das ging schnell 😅 Mit der Android App PingTools Pro bekomme ich es auch hin:
 1 point
1 point -
 Problem solved as expected with the dummy HDMI thing. Thanks!1 point
Problem solved as expected with the dummy HDMI thing. Thanks!1 point -
OK thanks. Really hope you can return to it some time as it is a VERY interesting container. Keep up the great work.1 point
-
@IGHOR YOU ARE THE MAN!!!!!! powered down my unraid system. removed usb key plugged into laptop and copied your file over. back into machine, boot up and autodetect set custom driver. it flippin' works! whilst i don't get BATTERY CHARGE % RUNTIME LEFT NOMINAL POWER UPS LOAD i do get UPS LOAD % when i kill power to the UPS, unraid knows about it! i've set it to power down the system after 4 minutes of battery time. when i turn power back on, the unraid recognises it is! all telegram notifications work as well. thank you so much for doing this!1 point
-
Yes and no. You don't need to stop the container. You don't need to change the parameter in the Extra Parameters as long as you named it: '/dev/dvb' because it's the same. I would do it as follows: Upgrade to 6.9.2 Reboot (after the reboot the TVHeadend container does not start because the /dev/dvb directory is missing because you have to install the DVB Driver plugin first) Install the DVB Driver plugin Go to the Settings page and click on DVB Driver on the bottom Select your preferred driver package and click update Reboot (please note that the plugin will download the new driver on boot so make sure that you have a active internet connection on boot, only saying that because some people have installed PiHole on their Unraid server) The TVHeadedn container should start right away and you should be able to use your DVB cards as usual. (you can also check on the plugin page if the cards are all found) If a new version from Unraid is released wait a few hours (since my server has to compile the drivers and update the driver packages) and then upgrade, the plugin will check on boot if the driver that is currently downloaded is compatible with the installed Unraid version and update itself if necessary. If you got any further question please feel free to ask.1 point
-
I've come across https://github.com/P3R-CO/openrgb-container which seems promising for my RAM, but thee OpenRGB site suggests they no longer support Mystic Lights as there are different implementations and basically, you can brick things. It comes with lots of warnings in general so I'm hoping to try look at it and read up when I have a good chunk of time rather than rushing... I don't fancy breaking things just for a bit of colour control lol. If I get it working though, I'll probably aim for things listed as compatible when I eye up some colour fans. I did wonder that but I'd expect to at least see something for GPU clock or something. No doubt I've missed something but I'll spend some time RTFM/support threads to see if I've overlooked something obvious to start with.1 point
-
The process to follow in this scenario is covered here in the online documentation that can be accessed via the Manual link at the bottom of the Unraid GUI.1 point
-
there is one from @ich777 https://unraid.net/community/apps?q=ferdi-client#r1 point
-
Thanks, figured my issue out, corrupt libvirt.img now that the image is deleted and recreated all is well.1 point
-
I got it worked out. Had some dust blocking the pins. Do I need to mark the topic as SOLVED or something?1 point
-
It worked !! Many thanks for the help
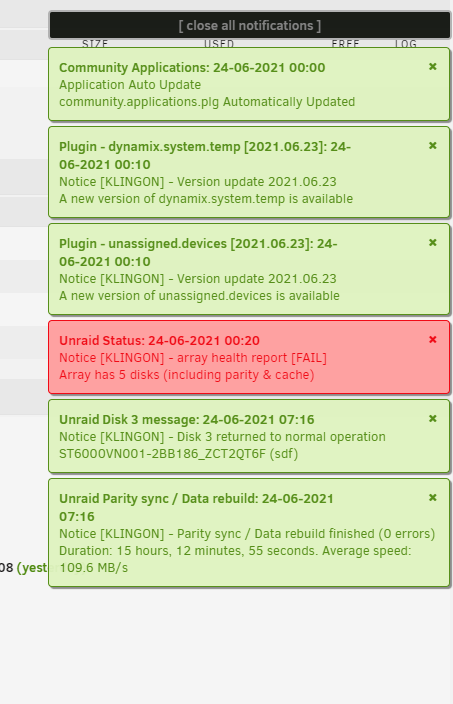 1 point
1 point -
Thanks to everyone that responded. I managed to get rid of it Thank you guys!!1 point
-
For the absolute bleeding edge I'd probably suggest passing thru a thunderbolt PCI-E card and using a fiber optic thunderbolt cable with a thunderbolt dock at the other end. This would give you video outputs and USB inputs for basically raw performance. It's a bit on the expensive side. For the budget oriented I would head in the direction of using Moonlight to access the VM's remotely. This would limit your I/O options a bit, and would introduce some latency (the thunderbolt dock option would be effectively zero latency.) Moonlight has clients on basically every OS imaginable at this point. The KVM/HDMI/USB over IP solutions are also going to be fairly low latency, but they will be heavily limited on what resolutions they support and what I/O they enable. In all cases you will need a "client" box at the display end to handle the display output and I/O. I think some of the fanless braswell units available from china would be attractive moonlight "thin clients" since they would be fairly low cost, silent, and capable of outputting 4k60hz, and decoding 4k60hz natively. In theory you could lower the cost further by buying them barebones with no ram or storage, adding a single 2gb SoDIMM module and setting up a PXE server to hand out the thin client image on unraid. There'd be a lot of legwork involved in that but it would be cheaper and pretty slick.1 point
-
I know mate i'm at a los we will try a fresh UnRaid and slap the GPU in, And see what happens ill come back to you with the findings1 point
-
Sounds like you have not set a mapped volume for your cache1 point
-
Very unlikely to happen.1 point
-
Stop and edit the docker. Change Repository: to this... linuxserver/openvpn-as:2.8.8-cbf850a0-Ubuntu18-ls122 Click Apply and it will rebuild the image You should be good to go after that once it finishes loading up o/1 point
-
I did because of this: My mistake since it wasn't posted by the OP, removed SOLVED.1 point
-
I recommend moving the power for the server to another circuit so you can leave it running and communicating with the UPS. For a dummy load, a portable heater on low or medium, or a hair dryer on low heat works well. WAG from the screenshot, looks like you want somewhere around 500W to simulate max possible draw, assuming the screenshot was showing typical load. If you set it up this way, you can monitor the server's reaction to the power loss, and make sure it shuts down properly without further input from you. BTW, testing like this is recommended for any UPS setup, especially if it's new. That way you have confidence that A. it works at all B. the server shuts down properly before the UPS runs out of steam and quits powering the dummy load.1 point
-
https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=5373831 point
-
figured this out had to type exit then just pressed enter, and now it works perfect! Any idea why that happened?1 point
-
It's not permissions, it's incorrect paths. Read this carefully. https://forums.unraid.net/topic/57181-docker-faq/?do=findComment&comment=5643061 point
-
You can just add extra parameter in docker config, then docker container can get IPV6 automaticly. --mac-address xx:xx:xx:xx:xx:xx --sysctl net.ipv6.conf.all.disable_ipv6=0 Give container a unique mac-address then container should get a SLACC IPV6 address. There is no need to set up ipv6 on Unraid Server1 point
-
UPDATE: Found a solution which is in line with the fix for OE/LE. I created /etc/modprobe.d/snd-hda-intel.conf and put the same line in it that is used for OE/LE (options snd-hda-intel enable_msi=1). Audio works as expected now. I know that "demonic" audio is an issue for Nvidia based cards and there are fixes for Windows and OE/LE guests. However, I don't see a fix for Linux distro guests (Ubuntu 16.04.1 in my case). I'm doing a vanilla install and have only done an apt-get update/upgrade and installed OpenPHT...but I have the "demonic" audio bug. The manual seems to only address Windows guests: http://lime-technology.com/wiki/index.php/UnRAID_6/VM_Guest_Support#Enable_MSI_for_Interrupts_to_Fix_HDMI_Audio_Support Is there a Linux fix (non-OE/LE)? XML... <domain type='kvm' id='56'> <name>HTPCFAMILYRM</name> <uuid>f31215fd-5042-c086-4b96-ba7f8531458d</uuid> <metadata> <vmtemplate xmlns="unraid" name="Linux" icon="linux.png" os="linux"/> </metadata> <memory unit='KiB'>4194304</memory> <currentMemory unit='KiB'>4194304</currentMemory> <memoryBacking> <nosharepages/> <locked/> </memoryBacking> <vcpu placement='static'>2</vcpu> <cputune> <vcpupin vcpu='0' cpuset='10'/> <vcpupin vcpu='1' cpuset='11'/> </cputune> <resource> <partition>/machine</partition> </resource> <os> <type arch='x86_64' machine='pc-q35-2.5'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd</loader> <nvram>/etc/libvirt/qemu/nvram/f31215fd-5042-c086-4b96-ba7f8531458d_VARS-pure-efi.fd</nvram> </os> <features> <acpi/> <apic/> </features> <cpu mode='host-passthrough'> <topology sockets='1' cores='1' threads='2'/> </cpu> <clock offset='utc'> <timer name='rtc' tickpolicy='catchup'/> <timer name='pit' tickpolicy='delay'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/domains/HTPCFAMILYRM/vdisk1.img'/> <backingStore/> <target dev='hdc' bus='virtio'/> <boot order='1'/> <alias name='virtio-disk2'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x03' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/isos/ubuntu-16.04.1-desktop-amd64.iso'/> <backingStore/> <target dev='hda' bus='sata'/> <readonly/> <boot order='2'/> <alias name='sata0-0-0'/> <address type='drive' controller='0' bus='0' target='0' unit='0'/> </disk> <controller type='usb' index='0' model='nec-xhci'> <alias name='usb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/> </controller> <controller type='sata' index='0'> <alias name='ide'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <controller type='pci' index='0' model='pcie-root'> <alias name='pcie.0'/> </controller> <controller type='pci' index='1' model='dmi-to-pci-bridge'> <model name='i82801b11-bridge'/> <alias name='pci.1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1e' function='0x0'/> </controller> <controller type='pci' index='2' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='2'/> <alias name='pci.2'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x01' function='0x0'/> </controller> <controller type='virtio-serial' index='0'> <alias name='virtio-serial0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x02' function='0x0'/> </controller> <interface type='bridge'> <mac address='52:54:00:69:c3:d7'/> <source bridge='br0'/> <target dev='vnet1'/> <model type='virtio'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x01' function='0x0'/> </interface> <serial type='pty'> <source path='/dev/pts/1'/> <target port='0'/> <alias name='serial0'/> </serial> <console type='pty' tty='/dev/pts/1'> <source path='/dev/pts/1'/> <target type='serial' port='0'/> <alias name='serial0'/> </console> <channel type='unix'> <source mode='bind' path='/var/lib/libvirt/qemu/channel/target/domain-HTPCFAMILYRM/org.qemu.guest_agent.0'/> <target type='virtio' name='org.qemu.guest_agent.0' state='disconnected'/> <alias name='channel0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x83' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x04' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x83' slot='0x00' function='0x1'/> </source> <alias name='hostdev1'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x05' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='usb' managed='no'> <source> <vendor id='0x045e'/> <product id='0x0291'/> <address bus='8' device='2'/> </source> <alias name='hostdev2'/> </hostdev> <hostdev mode='subsystem' type='usb' managed='no'> <source> <vendor id='0x20a0'/> <product id='0x0001'/> <address bus='2' device='10'/> </source> <alias name='hostdev3'/> </hostdev> <memballoon model='virtio'> <alias name='balloon0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x06' function='0x0'/> </memballoon> </devices> </domain> GPU card... root@unRAID:~# lspci -v -s 83:00.0 83:00.0 VGA compatible controller: NVIDIA Corporation GK208 [GeForce GT 730] (rev a1) (prog-if 00 [VGA controller]) Subsystem: Device 196e:1119 Flags: bus master, fast devsel, latency 0, IRQ 66, NUMA node 1 Memory at f4000000 (32-bit, non-prefetchable) [size=16M] Memory at b0000000 (64-bit, prefetchable) [size=128M] Memory at ae000000 (64-bit, prefetchable) [size=32M] I/O ports at dc00 [size=128] Expansion ROM at f3f80000 [disabled] [size=512K] Capabilities: [60] Power Management version 3 Capabilities: [68] MSI: Enable+ Count=1/1 Maskable- 64bit+ Capabilities: [78] Express Legacy Endpoint, MSI 00 Capabilities: [100] Virtual Channel Capabilities: [128] Power Budgeting <?> Capabilities: [600] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?> Kernel driver in use: vfio-pci GPU audio... root@unRAID:~# lspci -v -s 83:00.1 83:00.1 Audio device: NVIDIA Corporation GK208 HDMI/DP Audio Controller (rev a1) Subsystem: Device 196e:1119 Flags: bus master, fast devsel, latency 0, IRQ 64, NUMA node 1 Memory at f3f7c000 (32-bit, non-prefetchable) [size=16K] Capabilities: [60] Power Management version 3 Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+ Capabilities: [78] Express Endpoint, MSI 00 Kernel driver in use: vfio-pci1 point
-
Fixed the problem for me, thanks a lot johnodon. I came by this thread very circuitously so I'm going to leave a few notes and summarize in hope of making this more googleable for others: This gets rid of the crackling, demonic audio issue on linux guests (in my case Ubuntu 16.04) with an Nvidia GPU passthrough using HDMI audio by enabling Message Signaled Interrupts on the card. Simply create the file (as root) `/etc/modprobe.d/snd-hda-intel.conf` and fill it with the following: options snd-hda-intel enable_msi=1 Reboot and the problem should be fixed.1 point















.thumb.jpg.0c644260dacbdbc011d7ad8ba9a1c10a.jpg)
