Leaderboard




Popular Content
Showing content with the highest reputation since 04/26/23 in Report Comments
-
If all you have is the array, and no cache or other pools, then your Primary is the array, and secondary is none If you have a pool named 'cache', then cache:no = Primary:array, Secondary:none cache:only = Primary:cache, Secondary:none cache:yes = Primary:cache, Secondary:array, Mover action: cache->array cache:prefer = Primary:cache, Secondary:array, Mover action: array->cache Just substitute another pool name for 'cache' above for other pools.8 points
-
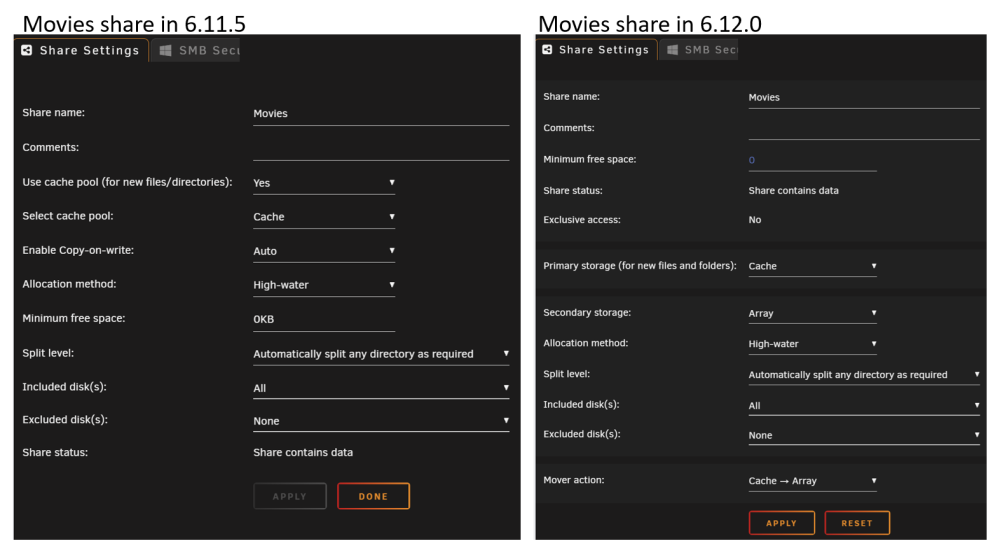
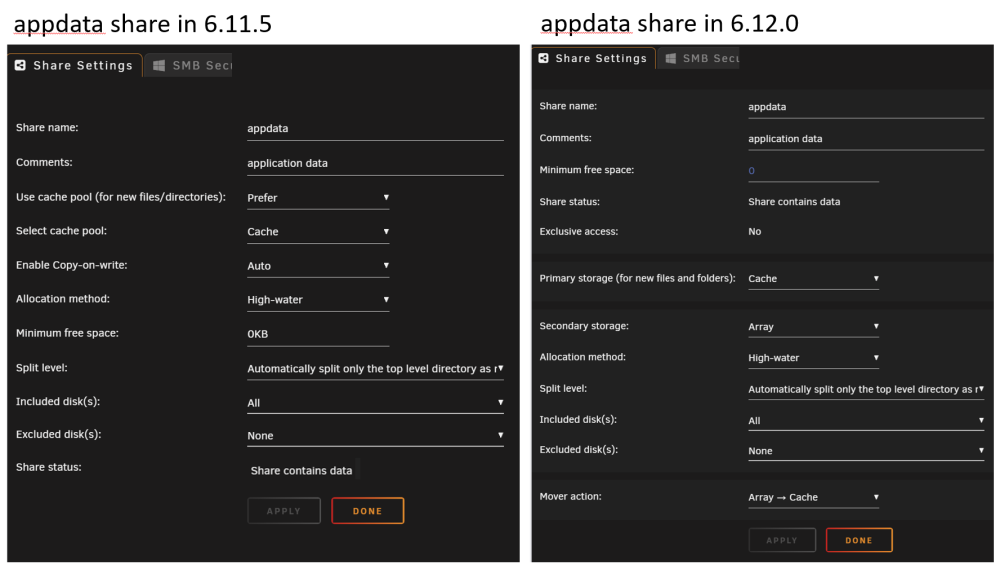
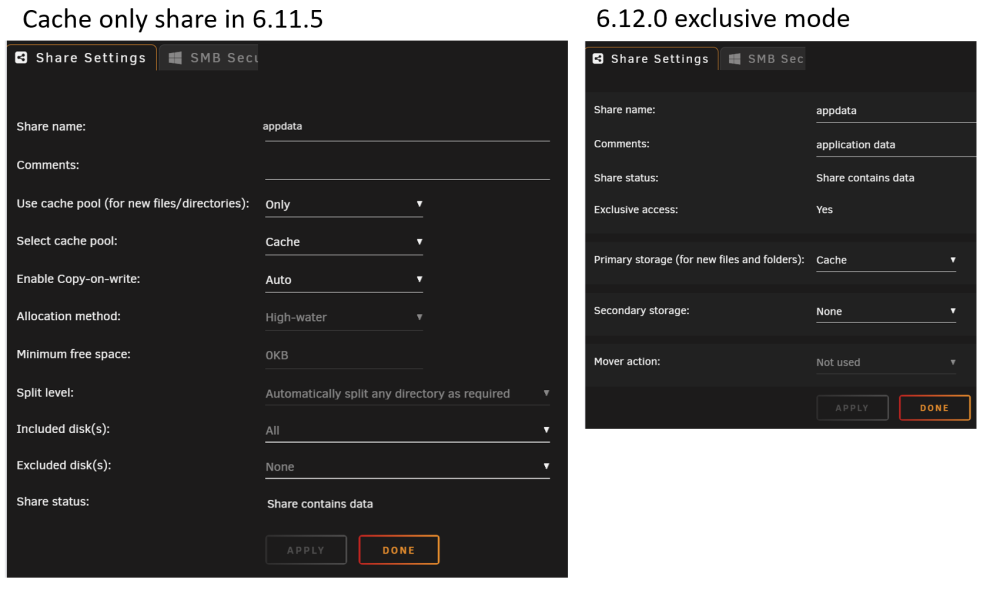
Let's see if this helps. Below is a typical Movies share, where new files come in to the cache drive and are then moved to the array. Hopefully the 6.12.0 screenshot is more clear about what is happening: Below is a typical appdata share, where files are normally on the cache but if files end up on the array they will be moved to the cache: And finally here is a cache only share in 6.11.5, automatically upgraded to exclusive mode in 6.12.0: Edit: consolidating other comments here One interesting thing about this, and the reason we are calling it a "conceptual change", is that your share.cfg files are not modified during the upgrade. In 6.12 this is entirely a front-end change, a different way of displaying the same configuration information. This change should make the configuration easier to understand at a glance, and it sets us up nicely for the future. It would have been horribly confusing to try and extend the old UI to handle multiple arrays and cache pool to data pool transfers, etc. At least from a UI perspective, those features will be easy to add going forward. Regarding exclusive mode - My favorite thing about configuring the new exclusive mode is that there is nothing to configure. It is fully automatic at the time the array starts. Looking at my image above of "6.12.0 exclusive mode"... when you start the array the system checks for "sharename" on all your disks. If it only exists on the specified pool then "exclusive mode" is enabled and you will get the speed benefits of the bind mound to that pool. If, at the time the array starts, "sharename" exists on storage outside of the specified pool then you automatically get the old "cache only" functionality, where files in "sharename" are included in the user share regardless of what disk/pool/etc they are on. From the release notes: "If the share directory is manually created on another volume, files are not visible in the share until after array restart, upon which the share is no longer exclusive."
 6 points
6 points -
for all, who are looking for a fix, here it is:4 points
-
https://forums.unraid.net/topic/92285-new-use-cache-option/?do=findComment&comment=854925 https://forums.unraid.net/topic/94080-individual-mover-settings-for-different-cache-pools/?do=findComment&comment=869566 I've been advocating for this change for a few years now.4 points
-
This is definitely an improvement. I never could think of a good way to clear up the confusion of the "old" way of thinking. I think this is it. What we have with 6.11: A user share setting labeled "Use cache pool", which isn't necessarily about a pool named 'cache' since we can name pools as we wish. The 4 possible values for this setting are not self-explanatory, and has always confused new users. Another user share setting labeled "Select cache pool" which is not necessarily about a pool named 'cache'. This setting is where you specify which pool that other setting is about. What we have with 6.12rc4: A user share setting labeled Primary storage which specifies where new files are written. A user share setting labeled Secondary storage which specifies where overflow gets written. A user share setting labeled Mover action which specifies source/destination for mover. The old way and the new way of thinking are functionally the same, but the new way is much easier to explain and understand. And it provides a way forward for future functionality.4 points
-
Everything functions the same, this is conceptually a different way of looking at things to make it clear how cache pools interact with the array and the actions that mover takes.4 points
-
Please update to 6.12.10-rc.1. It should fix this issue. It's available on "Next".3 points
-
Sorry can't share the diagnostic @JorgeB (there's Engineering Sample equipment on my unraid, i can't do that due to NDAs) model name : AMD EPYC 7B13 64-Core Processor root@Megumin:~# grep -c ^processor /proc/cpuinfo 128 The big difference from my look at both of them is the multiple GPUs vs my 1 (which is a converged accelerator, which is the ES part) root@Megumin:~# du -sh /run/udev/* | sort -h | tail -3 0 /run/udev/tags 0 /run/udev/watch 17M /run/udev/data (this is my udev size) I know there was changes on the kernel on udev for multiple gpus due to issues at booting them "fast" enough on AI clusters. (just don't remember which 6.1 version got it, but it's one between 6.12.6 and 6.12.8, still looking at patches to see where it was applied, as we upgraded to 6.6 at work to have the patch before it was on 6.1) So, one thing i should think is making the udev 64MB for 6.13 (which would help for weird and complex systems.) I know Rome vs Milan also do udev differently, as it was an updated architecture on the cpu side. Mobo: Asrock Rack RomeD8-2T CPU: Epyc 7B13 Ram: 1TB PCIe Expensions: 1 x LSI 9400-8i (x8) 3 x ASUS Hyper M.2 card filled with m.2 1 x Nvidia A100X ES 1 x Connectx-5 pro 2 x Oculink to U.2 2 x M.2 (On-board) Those are all my specs as i posted yesterday on Discord to confirm where the issue could be.3 points
-
i got the same problem. almost 2 minutes to load Dashboard
 3 points
3 points -
Also on 6.12.4, can't access SSH over tailscale... Not interested in hacking up the go file.3 points
-
Thanks for all of your help testing the rc series, Unraid 6.12.4 is now available! Changes from rc19 are pretty minor, but if you are running one of the RCs please do upgrade as it simplifies support to have everyone on a stable release.3 points
-
I wanted to share that I too have mostly figured out the Samba macOS nuance. I'm on Unraid 6.12.3 with macOS Ventura 13.5.1 To start, setting fruit:metadata = stream in the SMB Extras in the Unraid UI was the single biggest contributor to getting things working. Here's exactly what I have, in its entirety: [Global] fruit:metadata = stream Note that I don't use Unassigned Devices, which I think would add to these lines. After adding this and stopping/starting the array, pre-existing Time Machine backups were NOT working reliably, so I also had to create new Time Machine backups from scratch. I kept the old sparsebundles around just in case. Once new initial backups were made successfully, one of my MacBooks was able to reliably back up on a daily cadence. It's been running this way for a couple months. Meanwhile, one of my other MacBooks refused to work well with Time Machine, making one successful backup every few weeks, contingent on a recent Unraid reboot. I couldn't deal with this, so I factory reset it (reinstalling macOS) and created an additional new Time Machine backup on Unraid. Then it worked flawlessly. Then one of my MacBooks died, so I needed to restore data from Time Machine. I first tried to connect to Unraid and mount the sparsebundle through Finder, but it would time out, beachball, and overall never end up working. I was however able to get it mounted and accessible through the Terminal/CLI using the command `hdiutil attach /Volumes/path/to/sparsebundle` and with that, access the list of Time Machine snapshots and the files I wanted to recover. Then, I tried to use Apple's Migration Assistant to attempt to fully restore from a Time Machine backup. I was able to connect to the Unraid share and it was able to list the sparsebundles, but it would get stuck with "Loading Backup..." indefinitely. I moved some of the other computers' sparsebundles out of the share so it could focus on just the one sparsebundle I wanted, but even after waiting 24 hours, it would still say that it was loading backups. Looking on the Open Files plugin's tab in Unraid, I would see it reading one band file at a time. After enough of this, I tried to access a different sparsebundle that only had two backups, instead of months of backups, and "Loading Backups..." went away within 10 minutes and I was able to proceed with the Time Machine restoration, albeit slowly, and not with the data I wanted. This did clue me in to something, though. Using `find /path/to/sparsebundle/bands/ -type f | wc -l` to get the file count inside the sparsebundle, the one that made it through Migration Assistant was only 111 files, and the one that stalled for 24h was over 9000 files. I then went back to the Unraid SMB settings and tried to fiddle around a bit more. I found, as others did, that changing the following settings in smb-fruit.conf caused big improvements. The defaults for these settings are `yes` so I changed them to `no`: readdir_attr:aapl_rsize = no readdir_attr:aapl_finder_info = no readdir_attr:aapl_max_access = no As the Samba Fruit man page notes in https://www.samba.org/samba/docs/current/man-html/vfs_fruit.8.html, `readdir_attr:aapl_max_access = no` is probably the most significant of these, as the setting is described: "Return the user's effective maximum permissions in SMB2 FIND responses. This is an expensive computation. Enabled by default" My suspicion is that the thousands of files that make up a sparsebundle end up getting bottlenecked when read through Samba, causing Migration Assistant to fail. After adding these lines to `/etc/samba/smb-fruit.conf` and copying that updated file over to `/boot/config/smb-fruit.conf` and stopping and starting the array, I confirmed the settings were applied with `testparm -s` and looking at the output: [global] ~~~shortened~~~ fruit:metadata = stream fruit:nfs_aces = No ~~~shortened~~~ [TimeMachine] path = /mnt/user/TimeMachine valid users = backup vfs objects = catia fruit streams_xattr write list = backup fruit:time machine max size = 1250000M fruit:time machine = yes readdir_attr:aapl_max_access = no readdir_attr:aapl_finder_info = no readdir_attr:aapl_rsize = no fruit:encoding = native Now that the new settings were in place, Migration Assistant got through the "Loading Backups" stage within a minute or two, and I was able to successfully fully restore the old backup sparseimage with thousands of files. I know there's some nuance around setting Apple/fruit settings depending on the first device to connect to Samba, so this entire experiment took place with only Macs connecting to Unraid. I did not yet repeat the experiment with Windows connecting first or in parallel, but I hope the behavior is the same as I cannot guarantee Macs will always connect before Windows computers in my network. Anyway, I wanted to share as I avoided updating Unraid 6.9.2 for literal years to keep a working Time Machine backup. I then jumped for joy at the MacOS improvements forum post a year ago just to find it didn't help in any way, and was again excited to update to 6.12, just to find it STILL didn't work reliably with default settings. Very disappointing, LimeTech. And a huge thanks to the folks in these threads that have shared their updates and what has or has not worked for them. Let's keep that tradition going, as it's clear we are on our own here. Some Time Machine related posts from over the years. I'll make update posts in each directing here. TLDR: Working Time Machine integration. Adding fruit:metadata = stream to the global settings and then readdir_attr:aapl_max_access = no and readdir_attr:aapl_finder_info = no and readdir_attr:aapl_rsize = no into the smb-fruit settings allowed me to run Time Machine backups AND restore from or mount them using Finder and Migration Assistant.3 points
-
I made a fix for displaying the IPv6 address in network settings. Should be included in the official release.3 points
-
generally spoken, sure, we are free to use own hardware. and now may one culprit, Fritz is more or less the only one who make decent cable modem/routers ... and as there are meanwhile many cable users here the only option would be to make a dual setup (2 routers ...). which may really doesnt fit in the time anymore considering energy consumptions and so on ... even i thought about it to finally get rid of this issue now ... i spent 2 excessive month figuring it out also, Fritz has a wide distribution of DECT smart home accessoires (like here too ...) so basically, yes, either im locked to the Fritz "appliances" or i drop everything and just keep a fritz as modem and get another router, hoping it can handle ipvlan properly ... while i was surprised that also unify has firewall isuues in some combinations ... and when i think about it, alot of hardware is somehow binding networking to mac addressing and not ip's only so personally, i wouldnt even know what to buy now ... the 2nd NIC solution is posted sometimes already, sadly with no diags afaik ... if it wouldnt be such a mess to reconfigure everything i could also test it again, but for now after relying long on 6.11 i switched now almost all dockers to bridge usage and the ones which are impossible i setted up seperatly LXC containers for my usage ... when i find some spare time i ll report the 2nd NIC usage results here, sadly i dont have a 2 NIC setup in my small Test Server ... otherwise it would be already posted3 points
-
Nothing changed regarding that, just the value shows up as a percentage instead of an absolute value, but like posted above it will go back to an absolute value once v6.12.4 is released.3 points
-
I agree, I asked for this to be changed to an absolute value to avoid user confusion and for next release it should be back to that.3 points
-
So, you’re saying you will not go into the go file & add the short script that’ll take you a couple seconds? If you can’t do that. Then okay. Not be rude or anything, we can’t help you if don’t add it in. All of us were able to get working & it’s great! I, myself, suggest adding it in, but again. It’s up to you if want to or not.3 points
-
Soo i fell over this forum I want to point out , that I DONT HAVE UNRAID , but my kernel panic errors directed me to this site. Im running OMV / Debian And my server started these CPU errors and i found out (at least i think) that this was related to network / docker / bridge And right now im on testing phase for possible solution. Here's what i did : I simply added forward/accept br0 connection: iptables -A FORWARD -p all -i br0 -j ACCEPT Im not sure if this will help you guys or you already have tried this. EDIT: It seems this didn't work Im at work right now, and i cannot remote in to my pc.. So its properly in "kernel panic"3 points
-
Indeed NTP is broken in Unraid 6.12.0, will be fixed in the next release. Thanks3 points
-
Will be fixed in next version Thanks3 points
-
NFS cannot deal with a symlink. You can use the actual storage location. For example if you have Syslogs as a cache only share, use the /mnt/cache/Syslog reference rather than /mnt/user/Syslog. This avoids shfs when using /mnt/user/Syslog.3 points
-
The current internal release (rc6.1) allows for /mnt -> /mnt to work and have access to exclusive shares via that no problems. (note that any share that isn't exclusive does not have any problem via /mnt or /mnt/user) /mnt/user as a host path does not allow for access to exclusive shares. Work is underway to have a setting to Global Share Settings to enable / disable exclusive shares. Assuming that a setting for enable / disable gets implemented, then at the same time FCP would also have a new test that would look at the paths for installed containers and then either warn people to ensure that exclusive access is enabled if the host path isn't compatible or a message saying that it's OK to enable.3 points
-
Hello i have an i5 11500 an experiencing the same issue since 6.12 rc3. Yesterday i add the flag i915.enable_dc=0 and now it's ok. Thank you3 points
-
Here is a link to the libtorrent bug tracker for this issue: https://github.com/arvidn/libtorrent/issues/69523 points
-
Works for me.3 points
-
Right, that is why we are calling this a "conceptual change". Your share.cfg files are not modified during the upgrade. This is entirely a front-end change, a different way of displaying the same configuration information. But your ideas are spot-on with regards to what becomes possible in the future. It would have been horribly confusing to try and extend the old UI to handle multiple arrays and cache pool to data pool transfers, etc.3 points
-
Please update to rc4.13 points
-
Published 6.12.0-rc4.1 which fixes a dumb coding error checking for bind-mounts if share name contains a space.3 points
-
Let's not get ahead of ourselves : ) Today the unRAID array is "The Array". In the future it will be another type of pool along with zfs, btrfs, etc. But let's not confuse this thread with future talk. I'd suggest keeping an eye on the Uncast for discussions of what is coming: https://forums.unraid.net/forum/38-unraid-blog-and-uncast-show-discussion/3 points
-
What impact does this change have on existing unraid arrays? Now, "i am" confused...3 points
-
P.S. as a workaround for now, if you need to import a degraded pool give it the number of lots it should have, that won't trigger the bug, e.g.:
 2 points
2 points -
Understandable, I was just trying to make it easier to reproduce, because I wasn't able at first, but I've now managed to do it, difference was the number of slots for the new pool. Thanks for the report, it's a corner case, but still a bug.2 points
-
I tried time machine like a year ago and couldn't get it to work - excited to see if this allows it to function again!2 points
-
JorgeB dug up this piece of info.2 points
-
@miicar zfsmaster just added a setting so it doesn't refresh unless you click the refresh button. That keeps it from spinning up disks now.2 points
-
Yes, I can confirm it is not necessary do do something special. My procedure was: - Stop VM and Docker - Install Update - Change the network settings Settings -> Network Settings -> eth0 -> Enable Bridging = No Settings -> Docker -> Host access to custom networks = Enabled - Start VM and Docker - No additional modifications needed2 points
-
thank you very much! This release fixed problem with apcupsd. Now UPS is being shutting down and start after.2 points
-
Update: The nginex crashes and open socket have stopped. No crach for 24h. Changes made in Unraid: - set Interface eth0 to IPv4 only Changes made in WIN10: - Chrome updated to Version 114.0.5735.199 (Official Build) (64-bit) Most of my crashes happed while using Chrome. Fall back to EDGE for som days but is chrashed while using it but not as fast as when using Chrome. Chenge made in router: - Disabled IPv6 -> resulted in a DNS trouble that mede me rebuild the AiMesh from screatch. I hade to rebuild the AiMesh (running AC5300 as main , AC88U and AC68U as nodes) 24h has passed since the router rebuild (reinstall) and the unraid server WebGUI is still running. Fingers crossed!2 points
-
I have decided I like the new behaviour but would like the timeout to be longer (possibly something like 10 seconds) Maybe it IS worth making the timeout configurable (with 0 meaning no timeout) to satisfy both camps?2 points
-
did you try We are aware that some 11th gen Intel Rocket Lake systems are experiencing crashes related to the i915 iGPU. If your Rocket Lake system crashes under Unraid 6.12.0, open a web terminal and type this, then reboot: echo "options i915 enable_dc=0" >> /boot/config/modprobe.d/i915.conf Setting this option may result in higher power use but it may resolve this issue for these GPUs.2 points
-
Changed Status to Open Changed Priority to Urgent2 points
-
On second though I think a zfs clone would be more efficient for what you need, assuming it still works: zfs snapshot cache-mirror/appdata@borgmatic zfs clone cache-mirror/appdata@borgmatic cache-mirror/borgmatic This won't take any extra space unless source dataset is changed, same as a snapshot. Then work with /mnt/cache-mirror/borgmatic and once done destroy the clone and the snapshot: zfs destroy cache-mirror/borgmatic zfs destroy cache-mirror/appdata@borgmatic2 points
-
Removed the i915 option from kernel cmdline in Syslinux Config, kept the option in modprobe.d, updated to rc8 and so far everything looks fine, cat /sys/module/i915/parameters/enable_dc returns 0 and there are no crashes.2 points
-
You should not do that. This gives access to everything on the system, including unwanted shares and content. Instead use a more specific path, like /mnt/user/myfolder --> /unraid2 points
-
the small Test Server doesnt even have VM enabled, so its not VM related (what i 1st thought from my Main Server) and if we talk about bridge, macvlan br0 mode is the one which is causing the issues ... sample (now from the 6.11.5 mashine which is working) from a docker setup the 6.12rc Test Server is now running fine since 7 days + with eth0 setup ... if i use br0 mode on 6.12rc (2 local mashines, totally different hardware) the Server's will always startup with the posted errors and always will crash after few hours or few days (max where 4 days or so without traffic on the Server), doesnt matter if VM is on, off, active, disabled, ... hope its understandable
 2 points
2 points -
definately, the upper described crash "borked" the tvh docker (lsio alpine based) which pretty sure allocated this error, i redid the tvh docker to make sure, i think we can drop this for now. about the "regular macvlan errors", one more came up while idle May 4 15:52:43 AlsServerII kernel: ret_from_fork+0x1f/0x30 May 4 15:52:43 AlsServerII kernel: </TASK> May 4 15:52:43 AlsServerII kernel: ---[ end trace 0000000000000000 ]--- May 4 16:35:57 AlsServerII emhttpd: read SMART /dev/sdb May 4 16:52:51 AlsServerII emhttpd: spinning down /dev/sdb May 4 17:37:44 AlsServerII webGUI: Successful login user root from 192.168.1.83 May 4 17:49:43 AlsServerII kernel: ------------[ cut here ]------------ May 4 17:49:43 AlsServerII kernel: WARNING: CPU: 1 PID: 22408 at net/netfilter/nf_nat_core.c:594 nf_nat_setup_info+0x8c/0x7d1 [nf_nat] May 4 17:49:43 AlsServerII kernel: Modules linked in: wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha xt_nat xt_tcpudp macvlan md_mod bluetooth ecdh_generic ecc cmac cifs asn1_decoder cifs_arc4 cifs_md4 oid_registry dns_resolver xt_conntrack nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat xt_addrtype br_netfilter bridge xfs xt_MASQUERADE ip6table_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 tcp_diag inet_diag nct6775 nct6775_core hwmon_vid efivarfs ip6table_filter ip6_tables iptable_filter ip_tables x_tables 8021q garp mrp stp llc x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel i915 kvm iosf_mbi drm_buddy i2c_algo_bit ttm drm_display_helper crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 drm_kms_helper drm aesni_intel mei_pxp mei_hdcp crypto_simd intel_gtt i2c_i801 agpgart cryptd rapl i2c_smbus intel_cstate mei_me mei i2c_core ahci r8169 libahci realtek May 4 17:49:43 AlsServerII kernel: syscopyarea sysfillrect sysimgblt fb_sys_fops thermal fan button video wmi backlight intel_pmc_core unix [last unloaded: md_mod] May 4 17:49:43 AlsServerII kernel: CPU: 1 PID: 22408 Comm: kworker/u8:1 Tainted: G W 6.1.27-Unraid #1 May 4 17:49:43 AlsServerII kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./J3355M, BIOS P1.90 11/27/2018 May 4 17:49:43 AlsServerII kernel: Workqueue: events_unbound macvlan_process_broadcast [macvlan] May 4 17:49:43 AlsServerII kernel: RIP: 0010:nf_nat_setup_info+0x8c/0x7d1 [nf_nat] May 4 17:49:43 AlsServerII kernel: Code: a8 80 75 26 48 8d 73 58 48 8d 7c 24 20 e8 18 db fc ff 48 8d 43 0c 4c 8b bb 88 00 00 00 48 89 44 24 18 eb 54 0f ba e0 08 73 07 <0f> 0b e9 75 06 00 00 48 8d 73 58 48 8d 7c 24 20 e8 eb da fc ff 48 May 4 17:49:43 AlsServerII kernel: RSP: 0000:ffffc900000fcc78 EFLAGS: 00010282 May 4 17:49:43 AlsServerII kernel: RAX: 0000000000000180 RBX: ffff888162b3b000 RCX: ffff888106097900 May 4 17:49:43 AlsServerII kernel: RDX: 0000000000000000 RSI: ffffc900000fcd5c RDI: ffff888162b3b000 May 4 17:49:43 AlsServerII kernel: RBP: ffffc900000fcd40 R08: 000000000d01a8c0 R09: 0000000000000000 May 4 17:49:43 AlsServerII kernel: R10: 0000000000000098 R11: 0000000000000000 R12: ffffc900000fcd5c tomorrow (may today) i have more time to check further into it, put traffic on there etc.2 points
-
sure, 1st feedback, somehow the little Server crashed completely last nite now while i left it in the last state really weird, the syslog was "cutted" ... only the failure entries left, so a reboot was required as the array didnt properly stop anymore (left in stopping state), nevermind. rebooted now, applied the changes and looking ok for now, i ll let it run a little and give feedback, currently no macvlan errors in the logs. alsserverii-syslog-20230504-0330.zip2 points
-
@Tristankin I signed up here to contribute my findings with the same issue. I have not yet tried the Unraid OS, but I believe this is actually a Linux Kernel issue, as I am experiencing the exact same problem of hard freezes on my Intel NUC 6CAYH (Intel Celeron J3455) but on the Debian OS. Specifically Debian 10 and 11, running Kernel 5.10 or Kernel 6.1 respectively. I have not yet tried downgrading Debian back to 4.19, but I might do a fresh debian 10 install on a USB-Stick just to test this out. Curiously, the Debian-based Ubuntu 22.04 on Kernel 5.19 is NOT experiencing the same freezes, so I am really unsure what is going on. It might be that Kernel 5.19 is the magic one-off kernel that just works, or maybe Canonical did something special with the Ubuntu-Kernel that prevents the hard-freezes. I, and it seems the linux community as a whole, is somewhat puzzled by this. A more thorough description of what I tried and tested can be found here (in German): https://debianforum.de/forum/viewtopic.php?t=186674 Edit: Small update: It appears that disabling Intel VT-d solved or at least improved the situation for me. I am typing this currently on a Debian 11 Kernel 5.10 Machine running 4 contemporany transcodes and the system is not showing any signs of freezing (usually froze within 2-3 minutes). I picked this up somewhere in this tread, so thank you for your input! Now to find out why it crashes with VT-d enabled for specific linux distros and not for others....2 points






























