




jj1987
Members
-
Joined
-
Last visited
Everything posted by jj1987
-
Dann lösch den Ordner doch auf disk1?!
-
Durchaus Möglich. Ich selbst habe den Vorgänger (SN550) und keine Probleme. Aber offenbar bin ich damit eher die Ausnahme. WD SSDs sind wohl tendenziell nichts für Stromsparer. Aber das ist auch sehr speziell. SSD 1 mit Mainboard A verhält sich uU ganz anders als SSD 2 mit Mainboard A oder aber auch SSD1 mit Mainboard B. Die Samsung 970 Evo Plus scheint allgemein als unproblematischste SSD in der Beziehung zu gelten. Falls du so eine vielleicht rumliegen hast, kannst du das ja mal gegenprüfen. Es könnte aber auch am Realtek LAN Chipsatz hängen. Die sind auch gerne mal zickig was ASPM angeht
-
Da steht aber ja auch "Array gestartet" und "Parität ist gültig" - also doch alles gut?!
-
Würde mich aber stark wundern wenn das am Update liegt. Powertop selbst macht ja erstmal nichts (außer wenn man dann powertop -- auto-tune ausführt). Aber freut mich natürlich dass es nun zu deiner Zufriedenheit läuft
-
Naja du setzt zumindest schonmal eine veraltete Version von powertop ein, könnte also einfach ein Anzeigefehler sein
-
das ist leider normal. VMs und C-States passen offenbar nicht zusammen
-
Puh da kann ich auch nicht weiterhelfen, habe keine Nvidia. Bin nur im Jellyfin Template über die Variable gestolpert. Habe allerdings auch den offiziellen Container Jellyfin/Jellyfin Evtl kann @ich777hier weiter helfen?
-
Hast du die GPU denn auch korrekt im Container drin?:

-
Um die Fritzbox Mal (zum Teil) aus dem Spiel zu nehmen, könntest du als DNS Server Mal z.b. Google nehmen (8.8.8.8). Ich vermute da irgendwie das Problem. Läuft vielleicht noch irgendwo ein pihole/adguard?
-
Du weißt aber schon wie das UNRAID Array funktioniert? Das läuft unabhängig vom verwendeten Filesystem. Bei einer schleichenden Datenveränderung, sollte der (regelmäßige) Parity Check Alarm schlagen (wobei man da leider nicht sieht welche Daten ggfs betroffen sind) Und bei total Ausfall kann man die Daten durch die Parity wiederherstellen lassen
-
Ich bin mir nicht ganz sicher, aber ich meine zfs ist in erster Linie für Pools?! Mag sein dass man ins Array auch zfs formatierte Disks schmeißen kann, aber das ändert ja nichts an der grundlegenden Funktionsweise des Parity-geschützten Arrays. Was wiederum heißt Wird so nicht klappen
-
Wäre dafür nicht die Option "Nur"?!
-
Deine Aussagen widersprechen sich aber auch... Und ins Array gehören (für mich) keine SSDs, schon gar nicht wenn da auch noch HDDs drin sind. Und selbst bei SSD-only Array sollte man genau wissen was man tut. Stichworte TRIM und Overprovisioning werfe ich da Mal in den Raum
-
Wobei ich mir nicht sicher bin ob in letzter Konsequenz BTRFS der Auslöser ist. Denn ebenso häufig sieht man ja zb die fragen zu AER Fehlern im Forum. Ich könnte mir vorstellen, dass ein (schlecht implementierter) Stromspar-Mechanismus das RAID1 stört, man dann aber nur als Endeffekt den BTRFS Fehler sieht. Ich zb nutze BTRFS Cache seit über 2 Jahren und außer ganz am Anfang (durch eben einen solchen Stromspar-Mechanismus auf einem anderen Board) hatte ich nie irgendwelche Probleme. Wobei ich natürlich auch einen recht entspannten usecase für meinen UNRAID Server habe (was bei zickigen Stromspar-Mechanismen dann allerdings wieder stärker zum tragen kommen würde). Da werden andere User ihre Maschinen ganz anders knechten
-
Shfs ist meine ich das UNRAID Array
-
Du musst als Hardware Beschleunigung "VA-API" auswählen
-
Subjektiv genau das. Offiziell sind die WD Red pro natürlich mit ganz viel Voodoo ausgestattet damit die Vibrationen der Festplatten sich nicht gegenseitig aufschaukeln etc PP... Wer dran glauben möchte🤷♂️
-
Meinen Cache habe ich im Plugin auch exkludiert Ansonsten wie geschrieben, mal das original Plugin deinstallieren und den fork installieren
-
Nutzt du das "original" Plugin, also aus den community apps? Das wird leider seit Ewigkeiten nicht mehr gepflegt, zumindest ist das mein letzter Stand. Aber es gab hier einen fork. Der funktioniert bei mir: https://forums.unraid.net/topic/100385-s3-sleep-geht-nicht-mehr/?do=findComment&comment=942357
-
Beim NAS, da der Lenovo ja eh nur 1GBE LAN zur Verfügung stellt (hättest du Zuhause überhaupt die Infrastruktur für mehr?): Überhaupt nicht. Die ~112mbyte/s schaffen ja sogar mechanische Platten. Bei der Latenz ist ne SSD sicherlich vorteilhaft, den riesen Unterschied zwischen SATA und NVME hab ich aber am Desktop zb auch nicht bemerkt. Der Wechsel von HDD zu SATA SSD hat sich stärker bemerkbar gemacht. Bei Docker/VM macht NVME dann definitiv schon mehr Sinn bzw "spürt" man den Unterschied eher, da parallele Zugriffe besser abgearbeitet werden können als bei SATA.
-
Da das mMn nicht die Standardeinstellung ist, hast du das vielleicht vor dem Neustart frisch geändert gehabt? Dann wäre das "normal" Nach einer nochmaligen Einrichtung sollte es dann aber eigentlich auch nach einem Neustart erhalten bleiben.
-
Dafür muss glaube ich das S3 Sleep Plugin installiert sein, findet man sonst im Dashboard oben links:
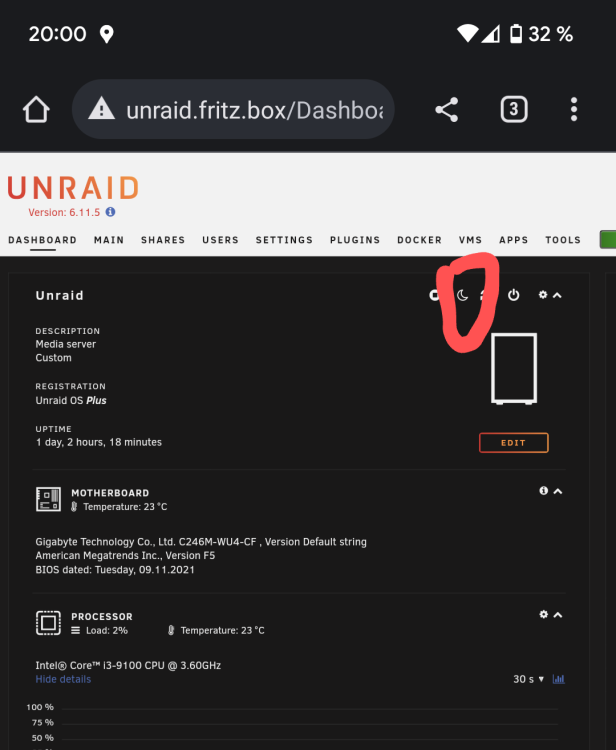
-
Ich hab damals die absolut nicht-DSGVO konforme Lösung via Google Photos gewählt. Einen Ordner "Hochzeit" erstellt, freigegeben für jeden der den Link hat. Link in QR Code umgewandelt und (mit einer kurzen Erklärung wofür der Code gut ist) auf die Tische gelegt. Könnte man vermutlich irgendwie auch mit z.b. Amazon Prime lösen. Da hätte man dann sogar unbegrenzt Speicherplatz in original Auflösung Muss aber natürlich jeder selbst wissen ob er diese Fotos einer Datenkrake anvertrauen möchte. Bei mir siegte halt die Bequemlichkeit. Gut und damals hatte ich noch kein UNRAID, sonst hätte ich vielleicht auch nochmal darüber nachgedacht.
-
Ich glaube das hat auch was mit Legacy und UEFI zu tun. Also i440 bei Legacy Boot und q35 bei UEFI Boot.
-
Intel arbeitet offenbar auch an einer Umsetzung: https://www.igorslab.de/intel-bereitet-auch-video-super-resolution-fuer-chrome-browser-vor/ Da die iGPU ja auch ne (abgespeckte) ARC ist, könnte es also auch damit funktionieren. Geht leider nicht so ganz aus dem Artikel hervor


