




Kilrah
Members
-
Joined
-
Last visited
Everything posted by Kilrah
-
Delete the containers_backup folder in your appdata share, then you should be able to install it again.
-
Do you have the RAM-Disk for Docker logs plugin installed? if so try removing it temporarily
-
Correct, as long as you don't use those features that don't exist in 7.2 or manually upgrade any zfs pools you're good.
-
It's on the Tools page
-
Update and switch to internal boot went fine. One thing I don't see mentioned in release notes is that ZFS ARC no longer defaults to 1/8th of RAM but 1/5th. Caused a slight surprise when seeing significantly higher RAM usage.
-
Solution's been mentioned, and watchtower's deprecated at this point anyway
-
For the record I had a similar issue and had to do some cleanup
-
/var is the container path here, host side is a docker volume. Just don't use docker volumes unless it's absolutely necessary which it doesn't seem like it is in this case, change to an appdata folder.
-
Looks like a layout problem, it's there but somehow ends up under the bottom bar Opening the menu extends the page but not enough for all of it to fit.
-
Was still on the old mpepping repo which he apparently still maintains somewhat and uses 8000 so didn't see 😅 Switched to official now
-
That image you're using with intel GPU support says it's using ollama 0.9.3 but ollama's currently at version 0.23.1. So yeah you're kinda stuck unless you find something else that supports those cards. Maybe can run the standard build using Vulkan?
-
It can't, when passed through the card isn't visible to the host anymore. If it did it'd show you a card that's not there and it'd be even worse for troubleshooting...
-
It can't start something that isn't there, so that suggests you didn't remove the old container before moving to compose
-
Go to Apps->Previous Apps and reinstall from there.
-
Expand container settings, enter a group name, apply, then select the group on any other container that needs to be part of it, then you have a separate block on the right to order them.
-
Should report that in the plugin thread then since it's not related to the OS itself and would have more chance of being seen
-
Did you group the containers that should be together and set order for that group?
-
Plugin dev has fixed that so it should no longer be an issue in the future
-
Usually people would do that by connecting the HDD directly to the Unraid machine and auto-syncing with an UD script rather than pulling through the network, no issue then.
-
Where exactly, you mean you can't read the backup that's on the external HDD on another machine? They're backups, should never be needed. If one day they are you just change the perms if you need to? 🤷
-
I never said they would mess with other parts, but with what is intentionally accessible to the vulnerable container.
-
Did you rename it from the default? If so that'll "break the link".
-
Had to downgrade as all my compose stacks broke... EDIT: Looked into it, using docker container ls -a it looks like something 2 years ago left some container folders in the Docker filesystem for containers that had been removed, previous Docker version didn't care or even see them but apparently Docker 29 does and for some reason wants to reuse the same hashes, then fails to create containers since there's already a folder. Removed the related folders, restarted Docker and everything's good again.
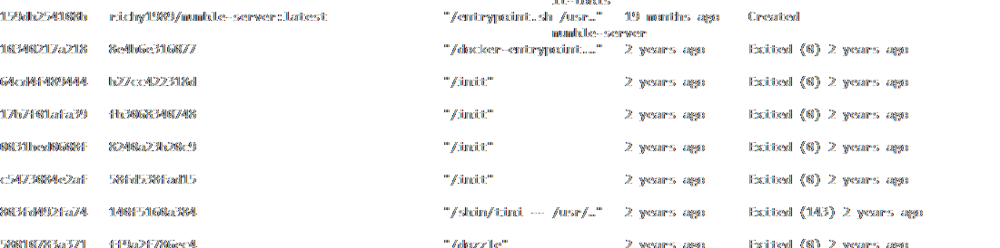
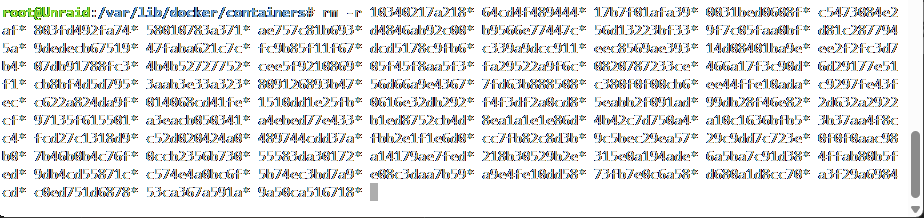
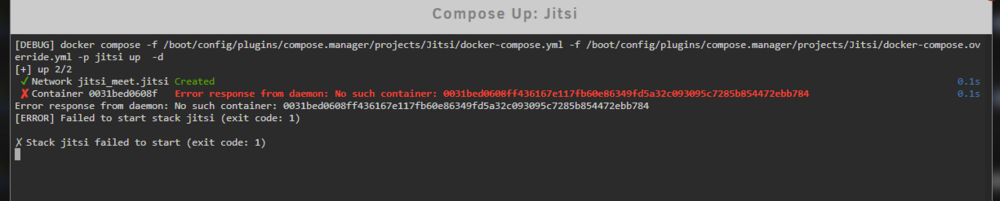
-
What matters is that an attacker would need to already be able to execute arbitrary code in your container. If that happens you already have major issues and they probably deleted all the data they could reach from the container without needing this. By using this if an attacker could also reach the host as an unpriviledged user they could become root - but since if you reach the host in unraid you're already root it basically doesn't change anything.
-
The kernel ones are normal and will happen any time a container is started/stopped. Looks like the plugin adds a little more.







