Leaderboard



Popular Content
Showing content with the highest reputation on 03/17/20 in all areas
-
Everyone is "right" in this topic, let me explain: First, Andrew, aka @Squid was given the "ok" by me to publicize the BOINC and Folding@home plugins for purpose of making people aware of their existence, please get off his back for this. CA is an awesome piece of software and @Squid has curated both it and the appfeed with the utmost care and respect. Honestly, I've been personally swamped with many things and didn't think much of it, other than thinking it was a great idea because a lot of people feel helpless and this is a tangible - albeit small - thing they can do in this time we are living through now. We have users all over the world including areas severely affected and we have received messages of appreciation for bringing attention to this. That said, it has been our policy since the beginning: We do not send unsolicited e-mail to anyone, nor do we authorize anyone else to do so on our behalf. Exception: we may send email notifications of critical security updates. In hindsight I see this was not right to send the notification email and we'll see to it that it doesn't happen again. Finally I don't see any real purpose in re-opening this topic. I think all's been said that needs to be said.6 points
-
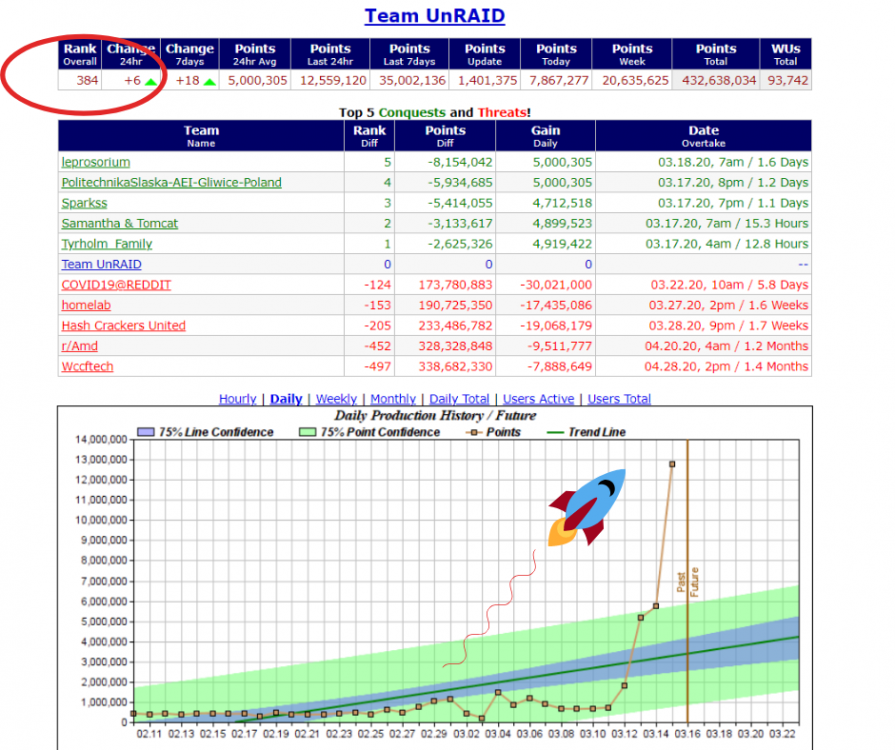
Update: We're up over 1,200+ Unraid users across the BOINC and Folding@home Unraid teams. Wow- thank you all. 🙏 http://boinc.bakerlab.org/rosetta/team_display.php?teamid=18943 https://folding.extremeoverclocking.com/team_summary.php?s=&t=227802
.thumb.png.577b51b419add7a2e77c98d568a5b9d5.png)
 4 points
4 points -
Just updated it. That fixed it. Thank you very much2 points
-
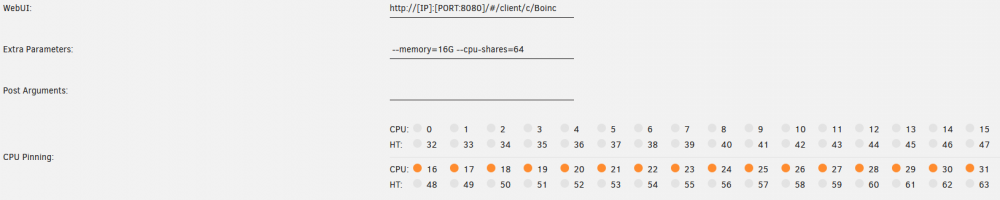
To everyone who has performance issues / unresponsiveness / lag while BOINC docker is running: Go to Docker template, click on "Advanced View" (upper right corner, on the same level as "Update Container") to see the advanced view and then: Select the cores you want BOINC to use and make sure to NOT select (a) CPU 0 + HT and (b) any core isolated to VM. Add --cpu-shares=64 to the Extra Parameters box. This will ensure BOINC does not starve other dockers when running (while allowing BOINC to always run full steam when other dockers are not running). Optionally add --memory=[#]G to limit the docker RAM usage to [#] gigabytes. This will prevent your other apps and VM getting killed if BOINC uses too much RAM. Screenshot as an example - core 16-31 are selected for BOINC and memory limited to 16GB.
 2 points
2 points -
its very possible that there was an issue with autodl-irssi at the time of the build (pulls from master branch), and this issue has now been resolved, so subsequent builds are ok, i will create a new image shortly and see if this fixes the issue.2 points
-
joined team Unraid on Boinc for this! Let's do it!2 points
-
Hi @Toskache, @nik82, @sunpower, Apologies for being absent this past week, and thanks for your patience! Thank you for letting me know about this issue. From your description and screenshots, I believe I understand the problem, and have deployed a fix to resolve the "Not Available" message under the Version column on the Docker tab. However, since the bug is related to checking for and applying updates... we may need to be a little more hands-on to repair your individual Docker containers. Details of the bug at the bottom, but first, let's get your Docker containers fixed.... this process will be one-time only to get past this update-related issue. From your Docker tab, find the ocrmypdf-auto docker container that you have configured. It will be shown as in @nik82's screenshot, with the "Not Available" status in the Version column. Click on your ocrmypdf-auto docker container and select Edit From the editor, find the field named Repository and edit the value to be exactly: cmccambridge/ocrmypdf-auto Please note that you will likely be deleting the text "quay.io/" from the beginning of this field. At the bottom of the page, click Apply. Unraid will restart your container and update it to point to the Docker Hub repository instead of quay.io. This will also update the image if your local container was not previously up to date. After returning to the main Unraid Docker tab, click the "Check for Updates" button at the bottom of the page. This process will take a few moments. You should now see proper version information for ocrmypdf-auto: That's it! Let me know if you continue to experience any issues. More technical details, for the curious: The container itself was not experiencing any problems. You should have noticed that it was still shown as ▶️started and was operating correctly. The trouble lies in Unraid's docker manager page, which is designed for the standard/first-party container repository Docker Hub. Although Unraid's docker manager does support installing and running a container from a third-party container repository like quay.io, it does not properly handle version and update checks for such a third-party repository. I learned about this rather too late, and had already deployed a few Community Applications using quay.io 🤦♂️ ocrmypdf-auto has not had any feature changes since I learned of the version reporting issue, so I had never gone through the migration process to Docker Hub, and Unraid's docker page simply reported "Update available" in many cases when no update was actually needed. For better or worse, the latest Unraid version is improved to be aware of the failure to query version information from third party repositories, and shows this failure as the "Not Available" message we've all been seeing on ocrmypdf-auto lately. The Fix: I've migrated the ocrmypdf-auto repository from quay.io to be mirrored at Docker Hub I've updated my Community App template for ocrmypdf-auto to refer to the Docker Hub version of the container, so all future users will never experience this issue. I've documented the manual remediation steps for you all, as I'm not confident that the update to the Community App template will necessarily be automatically applied for you, given that the bug is related to checking for updates, and I don't want anyone stuck with a broken container! Thanks again for reporting this issue, - @cmccambridge

 2 points
2 points -
Made a quick video that may help people having difficulty setting up2 points
-
There is unlikely to be a cure. COVID-19 is caused by a virus so focus would be on vaccine and treatment (to alleviate symptoms). And then we have the side burden of dealing with anti-vaxxers and idiots but the no amount of Rosetta@home can help with that.2 points
-
Vaultwarden is a unofficial Bitwarden compatible server written in Rust Templated by Selfhosters, used by many. Featured in this video by @SpaceInvaderOne FAQ: Q: I get ` An error has occurred. Cannot read property 'importKey' of null` when trying to login. A: This is expected when trying to login over HTTP, especially in Chrome. This is a security measure by the browser, not a bug.1 point
-
Just noticed that on the Dashboard one cpu at a time goes to 100%. Running top shows wsdd taking 100% (I am assuming that means 100% on one processor). It jumps around to both regular and HT processors, all of which are not pinned to a VM. It does not seem to be impacting any function or performance; I have not seen this before upgrading to 6.8.0. I do not see any issues in the system log.1 point
-
Just curious but any reason it needs to be near the TV? For gaming VM or media streaming purposes? Sent from my Pixel 2 XL using Tapatalk1 point
-
Yep, that's the biggest negative of this case, but, since I have an Intel CPU with integrated GPU which I use for Plex, Handbrake, etc. hardware transcoding, it has never been an issue. Even if I decided to go with a dedicated GPU for transcoding; an Nvidia Quadro P2000 (the preferred choice) is only 7.9 inches long. I don't have VMs to which I pass through a graphics card, but, if I did I would not need anything high-end as I am not a gamer and there are plenty of good cards under 9" Obviously, I am talking about my needs, not yours.1 point
-
I know you said no towers, but, I have the Silverstone CS380 and it has 8 front-accessible hot-swap bays + 2 5.25" slots. It can accommodate a graphics card up to 9.5" in length (don't know if that meets your needs). I currently have five of the eight drive slots in use. It's short for a tower at less than 17" (426mm). You could lay it on the side that has no air vents and the front door would then open down. It has 2 USB 3 front ports and you could use the 5.25" bays how you wish. I have a 4 x 2.5" SSD hot-swap caddy in one of the 5.25" slots and an optical drive for MakeMKV rips in the other. Two of the four slots are occupied as seen by the bright blue lights. Fortunately, with the door closed, you don't see the blue lights. Here's a picture (I had to put a piece of ugly tape over the power button light because it was so bright and was affecting the picture- still is):
 1 point
1 point -
I have the gd07 and it's a brilliant case. The removable drive cage is a great feature. There are a few downsides. It can be tight to work in, and doing any after-build changes usually requires removal of all the drives and a good deal of pfaffing about. Also, you can't really access or use any front USB ports because of the front flap. Not a deal breaker, but something to be aware of. Apart from that though, I like it a lot. Great flexibility, decent cooling and reasonably well built.1 point
-
Any memory error that's explicitly mentioned in a syslog means that its ECC (otherwise it couldn't detect it). And unless you're either lucky (or very unlucky depending upon your viewpoint), Memtest won't catch the problem as it'll be corrected. Only if the stick is bad enough that it doesn't catch it will memtest show anything1 point
-
ECC Memory, so memtest won't show any error as it'll be corrected.1 point
-
From a post earlier in this thread: You'll have to install it manually, but it supports iGPU.1 point
-
Great to hear @sunpower, @nik82! Thanks for letting me know that it's working for you - now I can be confident that I correctly understood the problem I will file an issue in my github backlog here to try and provide an explicit warning (or maybe even an error) from the container logs if it detects permissions that are unlikely to work properly... Since the /output directory is mapped to another location (e.g. appdata or a share), the permissions are set and controlled from outside ocrmypdf-auto... but I can try and at least observe them and provide a recommendation for folks to go use the "Docker Safe New Perms" tool. Nice detective work! - @cmccambridge1 point
-
Any word on the template? (Or is it in a different repository than all the other containers?)1 point
-
You need to setup an account on Rosetta@home then login to the account and search for the Unraid team in the Community section. From the search results you can join the team.
 1 point
1 point -
I added team from the rosetta website.1 point
-
joined the fight!. gone with boinc with rdp, hope my cpu holds up under the load 🙂 edit - wow thanks for the heads up on the ram consumption @testdasi just checked and boinc was seriously chomping on my ram!, 4GB+, limited it for now.1 point
-
Count me in on this, i joined unraid on Boinc1 point
-
The assumption for the "fixed next release" is that regardless of whether the dashboard is continually showing updates available, or never showing updates available is the the docker tab is consistently showing the update status correctly. If that is correct, then the dashboard is fixed next release (or it should be). If the docker tab is showing wrong information then you need to post screenshots etc1 point
-
Actually, the new diagnostics show that the parity disk IS now online and from the SMART report it looks to be healthy. You could try running an extended SMART test on it to be sure. Unraid will leave a disk marked as disabled (I.e. marked with a red ‘x’) until you take a positive recovery action. The steps to do this are covered In the Replacing a Disk section of the online section. In particular the part for re-enabling a drive currently marked as disabled that you want to re-enable.1 point
-
Your problem is right here. The permissions are wrong for mnt/user. They should be:

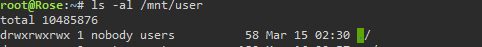
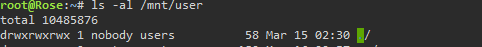 1 point
1 point -
Is this still good for 6.8.3 ? Even though I've been using Macs since '92 I've never been a huge fan of Time Machine, preferring apps like Super Duper and more recently Carbon Copy Cloner. Is CCC a viable option with unRAID? And do most of the guidelines for Time Machine in the link above apply to working with CCC? cheers1 point
-
@Squid I'm seeing the opposite problem. Some of my dockers have updates, but i don't see the "update" button on the main dashboard when i click on a docker with an update. Is that fixed too in the next release? Edit: Actually I'm seeing both. Dockers with no updates have an update button. Dockers with updates don't have an update button. I see it also in 6.9 Beta 1.1 point
-
I am also transcoding in RAM. Let me know if you think it is not working (you should have Trascode/Sessions folders under /tmp if it is working).1 point
-
My tower now serves as a space heater for my home office 😁1 point
-
Got a VM running with half my CPU pinned to it along with a GTX1060 and also my gaming PC with all cores and a GTX1070. Hope it helps the cause. My 2 GPUs are working overdrive for the foreseeable future and both computers are pumping out major heat.
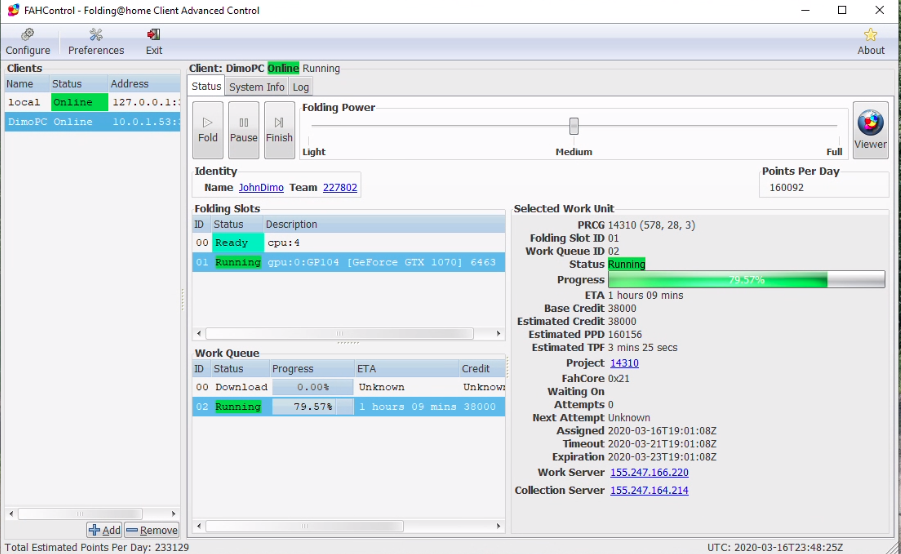 1 point
1 point -
TDP is a very poor measure of consumption over time for a specific workload. TDP is there solely as a design requirement for how much heat shedding capacity is needed for the heat sink system. If you have airflow or overall package or harsh temperature environments, then sure, you need to be concerned with TDP. For a home server, typically a low TDP version of an otherwise identical chip will likely consume MORE power in the long term, because CPU heavy tasks will be throttled to keep the TDP down while the drives are forced to stay spun up for a longer duration, vs the higher TDP processor completing quicker and allowing the server to spin down. It's much more important to look at the overall consumption of the motherboard, RAM, HBA, and GPU than it is to focus on the processor TDP. Also, keeping the spindle count to the lowest possible number will help tremendously. Running 3 8TB drives straight off the motherboard is going to be hugely more efficient than running 9 2TB drives that have the same usable capacity but require a separate HBA because the motherboard only supports 6 SATA ports. Designing a low power server is complex.1 point
-
Oh and in the Xeon range processors ending in L are usually the low power models but often they are only supplied to server manufacturers exclusively for datacentres, but they often come up on ebay after they have done 2-3 years service and replaced by a newer server.1 point
-
Hi guys, I joined the team this morning with my 2 servers and my PC! I hope that will help.
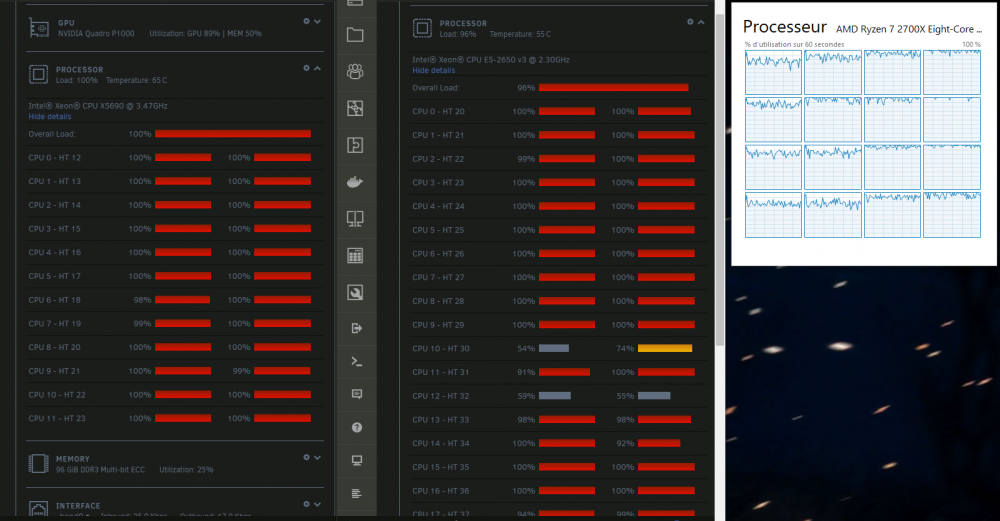 1 point
1 point -
Both my friend and I are getting this same error as well. I understand the issue is with autodl itself but is there any eta on when a fix is coming, whether a downgrade of the autodl version within the docker or some fix? It looks like that has been happening since March 11th cause both my friend and I haven't had any autoadded since then.1 point
-
Joined the team today. A big virtual hug to all contributors from shutdown Italy. Hope you all doing well and thanks for Unraid notification to @Squid1 point
-
Greetings all! I just upgraded from 6.8.1 without any noticeable problems. Thank you for another awesome build and the great dev and support quality.1 point
-
One suggestion for the Boinc Install instructions. In order for the File->Select Computer option to show up, you have to switch to Advanced View. Simple view does not show that option.1 point
-
may take a look if its ok like this, if not let me know please.1 point
-
I have resolved my password issues! DO NOT put a URL in the Client Portal box. It will SCREW you. Also there is a separate hidden page for client logins at host.com/client/login so when testing their passwords you must go there. I will be deleting all these posts and creating a sum up post with less chaotic instructions soon.1 point
-
Yes we are preparing a 6.9 beta release with 5.5.8 kernel, and then move to 5.6 kernel ultimately.1 point
-
Hi guys, I've not had much need to come back to the forums for a while as everything has been purring away just nicely but it was time to make a change so I'm seeking advise once again. I've got a ASRock Z97 Extreme4 motherboard which gives me a M.2 PCIe Gen2 x2 slot to work with so I've got a Samsung PM961 M.2 2 256GB drive to play with. I've installed the drive in the motherboard, unraid has detected it fine and I've installed Unassigned Drives so I could present it as a share for a few file copies to see how it performs. I'm happy with the write speed as I believe I'm hitting what I should expect from Gen2 x2 but the write speed tapers off after about 8gb of write. I've tested the disk with jbartlett777/diskspeed to get a ball park of the performance and it shows a write at about 800mb from start to finish so I'm trying to get an idea of why the write performance drops to 120mb after about 8gb of transfer. Given this is a unassigned drive I wouldn't expect to take any write hit like you would writing to the array so can someone pitch in and give me some thoughts of where to resolve this? Eventually I'd like to move to a 512 or 1tb SDD cache so I can take advantage of the 10gb networking and also give a little spring in the step of my VM's. Is it the SSD thats the issue (age, memory type etc) or something more fundamental behind the scenes? Cheers guys1 point
-
This was happening to me too and it's infuriating. Because of the way the Unraid works and the way sabnzbd works, it was bringing my computer down to its knees whenever a file decided to repair. And this is with a brand new 9600k, 32GB RAM, 6x2TB WD Blue (1 parity), and 1 evo 500GB for cache. I tried forcing downloads only to cache, the docker image only, etc. The only thing that actually fixed it was to move downloads to their own drive outside the array / cache. I bought a 256GB nvme when I built the computer that was not in the raid / cache yet. Here is what ended up being fairly stable (at least so far): Installed Unassigned Devices Plugin. Formatted NVME as XFS then mounted as unassigned device. Sonarr / Radarr /data -> /mnt/disks/{nvme}/downloads /media -> /mnt/user/media/{tv/movies} (media is a share, setup as 'Cache Yes') SABnzbd /data -> /mnt/disks/{nvme}/downloads. Both completed and in-progress mapped below that. The nvme gets thrashed with the download, verification, repair (if needed), and extraction without taking IO from any of my other docker containers / etc. Just to make sure SABnzbd doesn't ever lock everything, I pegged that VM to 3 of my 6 cores too. Once a download completes sonarr/radarr moves it to the media share, which because it's going from SSD to SSD transfers it over to the cache at a fairly fast speed. Even downloading at the same time as mover is running doesn't seem to kill it anymore. I hope it works well this way.1 point
-
I've finally solved my issue with the rutorrent process being deadlocked in IOWAIT. If this is your problem you will see all of the below symptoms: rutorrent will load, but you will get an error 500, 504, or 502 on getplugins.php and the queue will not load when the queue does load you will rarely get updates and "the request to rtorrent timed out" will be your most common response. torrents will get stuck in checking status torrents that are downloading/seeding will get abysmal performance. all of the above will be intermittent and will usually occur after adding new, large torrents, or several smaller torrents Checking "iotop" when the above is occuring will have the rtorrent process listed at the top, with 99.99% IOWAIT and very low read/write speed. I had previously attempted many things to fix this problem: changing nginx scgi buffer size. increasing rtorrent memory allocation changing php-fpm workers and memory allocations changing php-fpm and nginx timeout to allow rtorrent more time to respond to requests. The final nail in the coffin was switching IO Schedulers. I swapped from mq-deadline to BFQ and the problem has entirely gone away. Not entirely sure why internally this was the fix - but immediately upon switching to BFQ the problem is completely gone and I can actually watch checking progress on a 200gb torrent while data is moving on the other torrents in the queue.1 point
-
For users who want the letsencrypt in Poste IO working but are already using a letsencrypt docker, all you need to do is share the .well-known folders between your Poste IO and letsencrypt docker i.e. in the Poste IO docker config: This will not work if your domain has HSTS turned on with redirects to HTTPS (or this was the case with the version of letsencypt in the docker a while ago as it was reported here: https://bitbucket.org/analogic/mailserver/issues/749/lets-encrypt-errors-with-caprover ) You can instead mount the default certificate files in the docker directly to the certificates from the letsencrypt/SWAG docker. To be explicit with my volume mounts for SSL working: /data/ssl/server.crt → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/cert.pem /data/ssl/ca.crt → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/chain.pem /data/ssl/server.key → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/privkey.pem I do not recall the exact details of why the above is optimal but I suspect that Poste is handling making it's own full chain cert which results in some cert mangling if you do give it your fullchain cert rather than each separately (various internal services inside the docker need different formats) - I believe that without the mounts as above the administration portal will be unable to log you in.
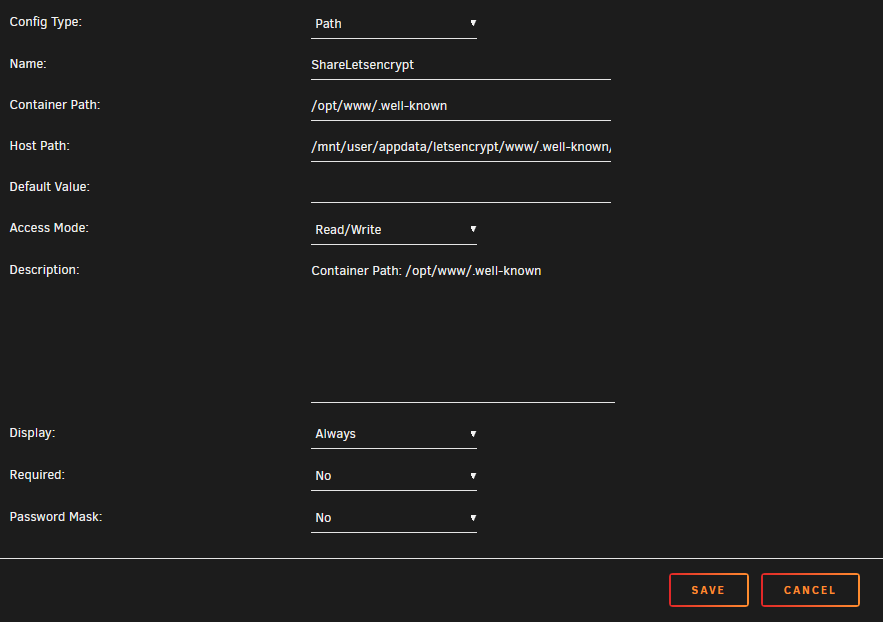 1 point
1 point -
The problem was that in 6.8.0-rc1 I could not access the the Flash Drive ( boot drive) from Krusader. The reason being that Limetech has changed the permission to the flash drive when it is mounted in the version. The only way in this version (and all future versions) to access the drive is through SMB or as user 'root'. (Understand that they are insistent that they are not going to change.) Currently, Krusader is being run as user 'nobody'. For anyone else looking for an answer, the answer is "YES". All you have to do is edit the Krusader Docker and change the PUID and PGID to that for the 'root' user. It is currently set for the 'nobody' user. On my system, the 'root' PUID is 0 and PGID is 0. I did run some tests and I did not find any problems after making the changes. EDIT: 2021-05-05 I wanted add a cautionary security notice to this post. There is a possibility that someone could access Krusader via a webrowser from any computer that has LAN access. (If you made these changes, that person will have root privileges and can do a lot of mischief! Of course, even without the changes, they could trash a lot of data files stored on the array because the possibility is still there to gain access.) To prevent this from happening, you should 'Stop' Krusader from running except when you are actually using it. This is not that much of usage issue as Krusader starts in a very few seconds when you want to use it.1 point
-
I fixed this by checking 'Enable Write support' under Konfigurator - Archives.
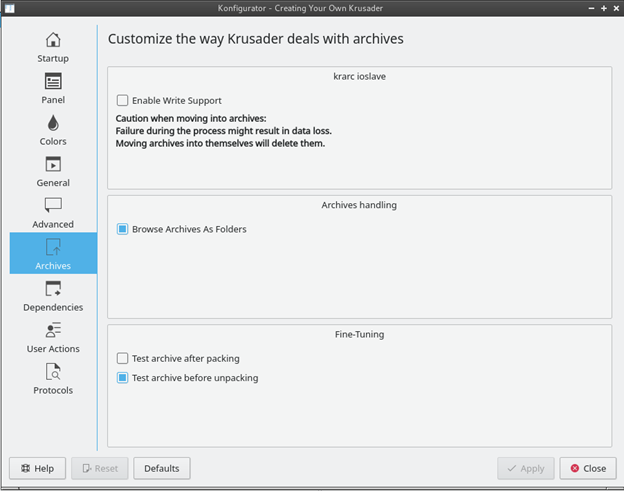 1 point
1 point

.png.bd385ba0eac073cf3d89ca586b95e97d.png)