Leaderboard


Popular Content
Showing content with the highest reputation on 05/08/20 in all areas
-
a little bird told me that they already were at beta8, huge changes coming....2 points
-
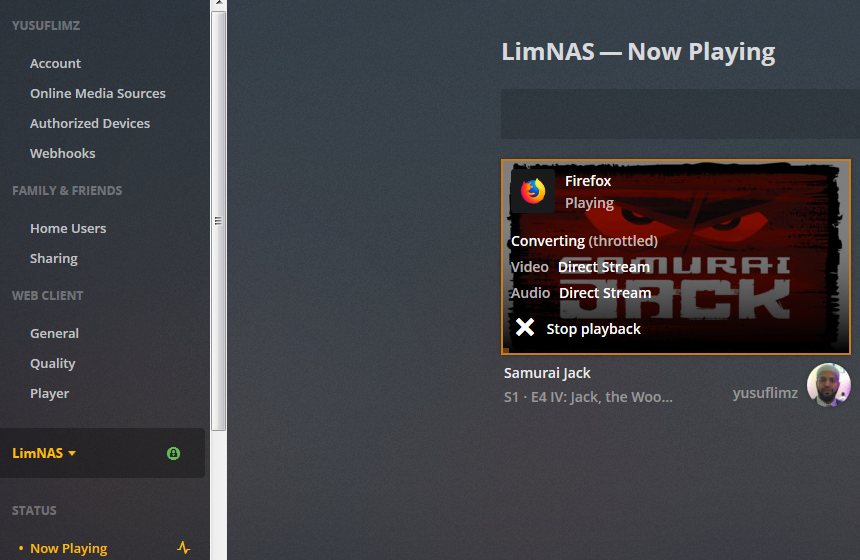
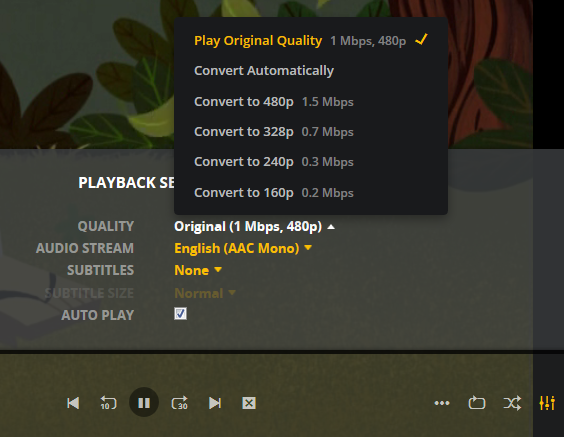
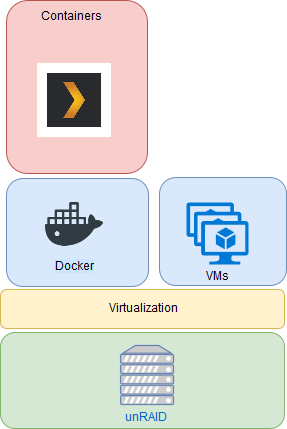
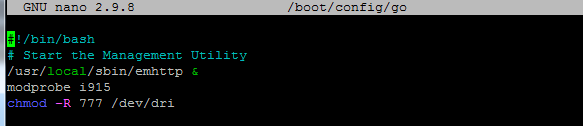
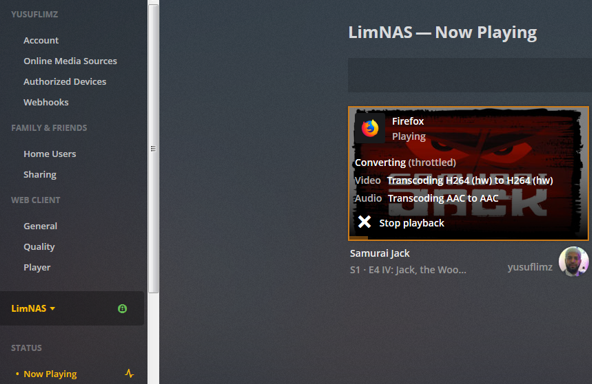
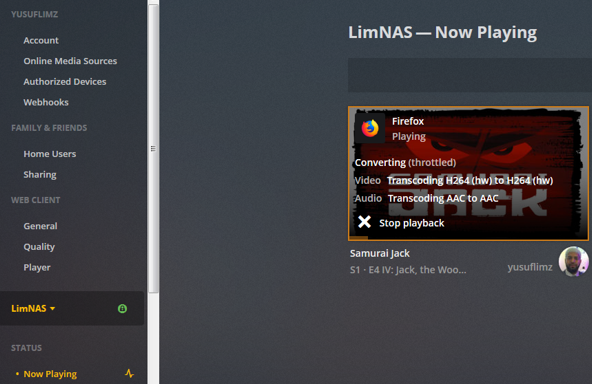
***Update*** : Apologies, it seems like there was an update to the Unraid forums which removed the carriage returns in my code blocks. This was causing people to get errors when typing commands verbatim. I've fixed the code blocks below and all should be Plexing perfectly now Y =========== Granted this has been covered in a few other posts but I just wanted to have it with a little bit of layout and structure. Special thanks to [mention=9167]Hoopster[/mention] whose post(s) I took this from. What is Plex Hardware Acceleration? When streaming media from Plex, a few things are happening. Plex will check against the device trying to play the media: Media is stored in a compatible file container Media is encoded in a compatible bitrate Media is encoded with compatible codecs Media is a compatible resolution Bandwith is sufficient If all of the above is met, Plex will Direct Play or send the media directly to the client without being changed. This is great in most cases as there will be very little if any overhead on your CPU. This should be okay in most cases, but you may be accessing Plex remotely or on a device that is having difficulty with the source media. You could either manually convert each file or get Plex to transcode the file on the fly into another format to be played. A simple example: Your source file is stored in 1080p. You're away from home and you have a crappy internet connection. Playing the file in 1080p is taking up too much bandwith so to get a better experience you can watch your media in glorious 240p without stuttering / buffering on your little mobile device by getting Plex to transcode the file first. This is because a 240p file will require considerably less bandwith compared to a 1080p file. The issue is that depending on which format your transcoding from and to, this can absolutely pin all your CPU cores at 100% which means you're gonna have a bad time. Fortunately Intel CPUs have a little thing called Quick Sync which is their native hardware encoding and decoding core. This can dramatically reduce the CPU overhead required for transcoding and Plex can leverage this using their Hardware Acceleration feature. How Do I Know If I'm Transcoding? You're able to see how media is being served by playing a first something on a device. Log into Plex and go to Settings > Status > Now Playing As you can see this file is being direct played, so there's no transcoding happening. If you see (throttled) it's a good sign. It just means is that your Plex Media Server is able to perform the transcode faster than is necessary. To initiate some transcoding, go to where your media is playing. Click on Settings > Quality > Show All > Choose a Quality that isn't the Default one If you head back to the Now Playing section in Plex you will see that the stream is now being Transcoded. I have Quick Sync enabled hence the "(hw)" which stands for, you guessed it, Hardware. "(hw)" will not be shown if Quick Sync isn't being used in transcoding. PreRequisites 1. A Plex Pass - If you require Plex Hardware Acceleration Test to see if your system is capable before buying a Plex Pass. 2. Intel CPU that has Quick Sync Capability - Search for your CPU using Intel ARK 3. Compatible Motherboard You will need to enable iGPU on your motherboard BIOS In some cases this may require you to have the HDMI output plugged in and connected to a monitor in order for it to be active. If you find that this is the case on your setup you can buy a dummy HDMI doo-dad that tricks your unRAID box into thinking that something is plugged in. Some machines like the HP MicroServer Gen8 have iLO / IPMI which allows the server to be monitored / managed remotely. Unfortunately this means that the server has 2 GPUs and ALL GPU output from the server passed through the ancient Matrox GPU. So as far as any OS is concerned even though the Intel CPU supports Quick Sync, the Matrox one doesn't. =/ you'd have better luck using the new unRAID Nvidia Plugin. Check Your Setup If your config meets all of the above requirements, give these commands a shot, you should know straight away if you can use Hardware Acceleration. Login to your unRAID box using the GUI and open a terminal window. Or SSH into your box if that's your thing. Type: cd /dev/dri ls If you see an output like the one above your unRAID box has its Quick Sync enabled. The two items were interested in specifically are card0 and renderD128. If you can't see it not to worry type this: modprobe i915 There should be no return or errors in the output. Now again run: cd /dev/dri ls You should see the expected items ie. card0 and renderD128 Give your Container Access Lastly we need to give our container access to the Quick Sync device. I am going to passively aggressively mention that they are indeed called containers and not dockers. Dockers are manufacturers of boots and pants company and have nothing to do with virtualization or software development, yet. Okay rant over. We need to do this because the Docker host and its underlying containers don't have access to anything on unRAID unless you give it to them. This is done via Paths, Ports, Variables, Labels or in this case Devices. We want to provide our Plex container with access to one of the devices on our unRAID box. We need to change the relevant permissions on our Quick Sync Device which we do by typing into the terminal window: chmod -R 777 /dev/dri Once that's done Head over to the Docker Tab, click on the your Plex container. Scroll to the bottom click on Add another Path, Port, Variable Select Device from the drop down Enter the following: Name: /dev/dri Value: /dev/dri Click Save followed by Apply. Log Back into Plex and navigate to Settings > Transcoder. Click on the button to SHOW ADVANCED Enable "Use hardware acceleration where available". You can now do the same test we did above by playing a stream, changing it's Quality to something that isn't its original format and Checking the Now Playing section to see if Hardware Acceleration is enabled. If you see "(hw)" congrats! You're using Quick Sync and Hardware acceleration [emoji4] Persist your config On Reboot unRAID will not run those commands again unless we put it in our go file. So when ready type into terminal: nano /boot/config/go Add the following lines to the bottom of the go file modprobe i915 chmod -R 777 /dev/dri Press Ctrl X, followed by Y to save your go file. And you should be golden!



 1 point
1 point -
Easiest way to come close to what you want is to change mover to "hourly" and then set the "threshold of used cache" to your desired % of when to actually move files. Mover will not move anything if your cache is under that percent. It just exits with a log entry. https://imgur.com/gallery/ODc9sBV1 point
-
All you need is the config folder on a new install.1 point
-
yeah i had felling that it was getting a little confusing. okay i try my best to explain it. you see here i have to nvidia GPU's, 0 is gtx 1070 ti which im using for my vm and 1 is gtx 750 for plex hardware transcoding. (i only want to see the stats for gpu 1 i.e. gtx 750) https://imgur.com/a/mGddMgH Now if i select gpu 1 i.e. gtx 750 from the dropdown list of unit ID for dashboard option it will keep posting stats until vm starts, the moment i start the vm all info on dashboard page will go blank and it will only resume posting when i shutdown my vm. Now if i click on this default button (while vm is still running) on gpu stats's page it will shows stats for gpu 1 i.e. gtx 750 but now when i shutdown my vm it will switch back to gpu 0 i.e. gtx 1070 ti cause under unit id for option it has switched back to gpu 0 cause we selected default option earlier, so cause 0 should be default it is now set gpu 0 i.e.e gtx 1070 ti. https://imgur.com/a/YzY4YmW so as long as its set to gpu 0 it will keep posting stats, now ofcourse it wil switch between gpu's whenever vm starts or stops but now atleast its always posting gpu stats. So basically its like this if its set it to gpu 0 it will always show gpu stats, it won't go blank but if i set it to gpu 1 it wont shows stats when the vm's are running.1 point
-
Thank you. Always appreciated1 point
-
Sent you some $. The stuff you do is very useful.1 point
-
You need to set this up slave so it will have the correct setting when you have an unassigned drive. Otherwise Krusader will not be able to work with that unassigned drive. If you have the mapping, which is reasonable so it will be available when you have an unassigned drive, then you must make the mapping slave or it won't work when you plug in an unassigned drive because if it isn't slave it can only work with disks that are already plugged in when you boot up (technically when the docker service starts). I would word this differently. The user shares ARE the root folders on cache and array. Cache itself has root folders that are part of user shares. user is all root folders on cache and array, user0 is only the root folders on array. User shares are how Unraid allows folders to span disks. Each root folder on cache and array is part of a user share named for that root folder.1 point
-
The slave setting is for the mapping, not the drive.1 point
-
It's right in your picture. /unraid_unassigned mapped to /mnt/disks.1 point
-
Disregard that question for now... I'm reading some stuff that might set me straight. https://answers.splunk.com/answers/320021/how-do-i-set-timezone-properly-in-propsconf.html1 point
-
If there were read errors, yes it should be replaced, you can also run an extended SMART test to confirm.1 point
-
Fixed by reinstalling. Thanks Regards Sjoerd1 point
-
It wasn't really an error, just a bogus message. Thanks for reporting. Enviado de meu SM-N970F usando o Tapatalk1 point
-
Thanks, I'll give it a go. It's my first time setting up a gameserver.1 point
-
If you store your docker appdata share and the VM ISO and System shares on an SSD (highly recommended) your array drives will not spin up just because dockers/VMs are in use unless they are configured to use array drives in some way. When accessing media with Plex for example, the necessary drives will be spun up, but, they can be configured to spin down when not in use while Plex still runs as a docker container on an SSD. See above as these shares could be cache only shares using the cache drive. Also, you could put them on an unassigned devices SSD. If you intend to use the cache drive for write caching of share data (configurable by share), how much benefit you would get from that depends on how often and how much data you write the array. Yes, if so configured. It will run periodic checks and let you know of problems through the notification system and GUI. Only you can fully answer that question, but, media storage, management and playback is a primary unRAID use case. Parity protection is a nice safeguard against disk drive failure, but, it is not a backup solution. You should also make plans to keep important data backed up.1 point
-
If docker and/or VMs are enabled, but not actually utilized, the drives will still spin down. But in your case, if you're not using them, then don't even enable them. It does improve write speed. But, for many users (myself included), I only use the cache drive for applications (ie: VMs / docker apps), and all writes for media go straight to the array. For me, the write speed is good enough, and most of the writes are all automated (new downloads etc), so I don't even notice if it's slower than if I wrote directly to the cache drive. Yes. Just enter in the appropriate info in Notification settings1 point
-
I hope you don't mind me asking... Is it possible to get the two kernel modules: 'joydev' and 'uinput' with this plugin/images? I recently released a container to play Steam games with In Home Streaming (even over the internet) inside a container but the only problem is that these two kernel modules are needed to enable 'real' controller support, now i have to map the controller buttons to keyboard or even mouse inputs and that's really frustrating for some games. EDIT: Not needed anymore, got it solved.1 point
-
@housewrecker Is there a plan to make this an automated process, like re-scan daily?1 point
-
I've written a small user script that reliably stops the array 100%. I'm not quite sure how 'safe' it is though - I haven't noticed any issues since I've been using it though. Here it is : #!/bin/bash ########################## ### fusermount Script #### ########################## RcloneRemoteName="google_drive_encrypted_vfs" RcloneMountShare="/mnt/user/data/remote_storage" MergerfsMountShare="/mnt/user/data/merged_storage" echo "$(date "+%d.%m.%Y %T") INFO: *** Starting rclone_fusermount script ***" while [[ -f "/mnt/user/appdata/other/rclone/remotes/$RcloneRemoteName/mount_running" ]]; do echo "$(date "+%d.%m.%Y %T") INFO: mount is running, sleeping" sleep 5 done while [[ -f "/mnt/user/appdata/other/rclone/remotes/$RcloneUploadRemoteName/upload_running" ]]; do echo "$(date "+%d.%m.%Y %T") INFO: upload is running, sleeping" sleep 15 done fusermount -uz "$MergerfsMountShare/$RcloneRemoteName" fusermount -uz "$RcloneMountShare/$RcloneRemoteName" echo "$(date "+%d.%m.%Y %T") INFO: ***rclone_fusermount script finished ***" exit Essentially what I'm doing, is checking whether mount is currently running and/or upload is currently running. If either of them are, then the script (and stopping the array) is paused for a few seconds and tries again. Once mount and upload has finished, it will proceed to fusermount -uz (both rclone and mergefs), and then the array stops just fine. I've been using this for the past week with no issues and the array stops always. Let me know what you think if you get to use it1 point
-
Has anybody worked out how to update the containers correctly and hide the errors?1 point
-
This has not been reported yet, but i do know about it. When i was writing that part i tried to calculate it but got a bit annoyed so decided to just leave it at MiB Will add it to my todo list, so in the next few days should be fixed1 point
-
Update This small update should hopefully fix the last issue, involving docker.folder not working at all. Sorry if anyone has lost their folders during all this Thanks @GooseGoose for helping find the issue1 point
-
I'll update the plugin when I get a chance with the correct packages. If you use the Snmp plugin or other plugin, it might overwrite the snmp package1 point
-
1 point
-
When i changed to more recent Unraid version it reordered my ethx: ports. The 10 Gb was eth0: and now it became eth1: after unraid update. eth0 is connected to br0 and possibly vibr0 used in dockers and VMs or something. So old settings when dockers and VMs were created don't match (1 and 10 Gb ports are not at same brx, vibrx). My solution was to reorder NICs (eth0, eth1) back in Network settings. If this is your problem (i do not know, just speculating) then my fix is as follows. To change Network Settings you must go to Settings and Disable in VM Engine and Docker first. Then you can edit Netw. Sett. Once you changed MAC numbers in "Interface Rules" so 10 Gb is back on eth0: or whatever you had there you have to apply setting and REBOOT. Only after reboot will they change to what they were set to. I'm not sure this is the cause behind your problems. Just trying to help. If you like me have several NICS (ethernet ports) and your 10 Gb has been reordered in the ehtx: numbering this might fix it. A wild guess is that the new NIC order is an effect of a new linux kernel used in more recent unraid versions. Maybe some linux user problems were fixed for multiple NIC boards by this change, but it messed up old unraid configs when updating unraid version.1 point
-
Man, I feel for you but that's why they have a 30-day trial and this forum. You have an entire month to try things out before you even need to think about purchasing anything (you can even request a longer trial), and you can ask almost anything here on the forum and get a quick answer. The Unraid team puts everything out there for you and gives you the resources to figure out if it's the right OS for you. I'm sorry you rushed into it without doing your homework first.1 point
-
You could have used Unraid for 30 days with the trial license to test it. That was the "right thing" to do. If you actually read PayPal's user agreement, you can easily learn that an item may not be considered Significantly Not as Described if the item was properly described but did not meet your expectations. I'm pretty sure LT will refund you, but not because you are right. LT likes to keep their customers satisfied.1 point
-
FYI I worked with the dev mikenye for a few hours yesterday on the Musicbrainz Picard container, and we now implemented chromium browser in the container, which allows both the ability to sign into your MB account and get your auth code, and also use the browser integration within the container itself. Update it and enjoy.1 point
-
This new one has the web client and management interface built into it and includes the latest version of BIONC. It is also based on a different (and supposedly more efficient) Linux distro. It is an all-in-one package to get you going. The regular BOINC docker (from Boinc) needs a client/management app installed on a client machine. The RDP-Boinc docker container (the one being replaced by this new one) had an older version of BOINC, did have an RDP web client built in but needed a manager. I used this version before switching over to this new LSIO BOINC. I think I got all of that right. Bottom line, this one is better 😀(imho)1 point
-
No issues in 6.7.2. Existing VMs (Server 2016) with hyper-v enabled won't boot after update -> stuck at TianoCore Logo Booting into recovery mode works, booting from a install DVD to load virtio drivers and modifiy the bcd works. Removing "hypervisorlaunchtype auto" from bcd makes the VM boot (but disables hyper-v) How to reproduce: (in my case, I hope its not just me ...) 1) new VM with Server 2016 Template 2) Install Server 2016/2019 3) enable hyper-v and reboot. It should either not reboot, boot into recovery or come back with a non working "VMbus" Device in Device manager. Testet with cpu paththrough (default) and cpu emulation (skylake-client), i440fx (default) and q35. Coreinfo.exe always shows vmx and ept present in windows. (see screenshot)) Tried to add vmx explicitly without any change, but as far as windows goes, its always enabled. <feature policy='require' name='vmx'/> Without kvm_intel active, the unraid-server notices it and says it should be enabled. # lsmod | grep kvm kvm_intel 196608 8 kvm 380928 1 kvm_intel I did not get the chance to test 6.8.0 and could not find a link/archive. I would test 6.8.0 to see if that qemu/libvirt version works. Installing hyper-v creates a "VMbus" device in windows, that is not working if you remove "hypervisorlaunchtype auto" from bcd. I think qemu also uses a "VMbus" device to make Windows VM compatibility easier. Maybe thats part of the "Hyper-V" option in the unraid templates? Have not tried other hypervisors or windows 10 hyper-v. As far as kernel options go, "iommu=pt" is a needed workaround for the cheap marvell controller. I'll try to to install the next server in english for better screenshots unraid-diagnostics-20200301-1112.zip1 point
-
ok, below is the xml of one of your passed through devices. <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x07' slot='0x00' function='0x3'/> </source> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/> </hostdev> the address type is inserted automatically by unraid and its generating a seperate bus for every hostdev. Looking at the error log I assume pfsense does not correctly allocate those. You can try the following which worked for me: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x07' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x07' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x1'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x07' slot='0x00' function='0x2'/> </source> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x2'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x07' slot='0x00' function='0x3'/> </source> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x3'/> </hostdev> I just changed the bus for the following entries to "0x01" (value of the first entry, which I assume is allocated correctly in pfsense) and additionally increased the function value for every entry. Afterwards I reset pfsense from the command line and after rebooting all passed through network cards were available. I hope this helps.1 point
-
BTRFS is stable enough, but it is much more susceptible to corruption if you have dirty shutdowns. I would recommend XFS unless there is some specific feature of BTRFS you need. And if so, make sure you have a UPS that is appropriately configured. But do some story and make sure you understand what BTRFS is and does. Must people here, i'd say 95%+ are on XFS. I would not loose any sleep worrying about bitrot. I'd be much more concerned about disturbed cables after swapping out ageing a disk, a real problem that causes data loss that you can and should proactively avoid by using hot-swap cages.1 point
-
You guys leave me sleepless... The good news: https://raw.githubusercontent.com/bergware/dynamix/master/unRAIDv6/dynamix.bleeding.edge.plg This is version 2016.09.16 and works with unRAID 6.2 stable. Copy & paste the URL above into the install box of plugin manager.1 point





























