Leaderboard



Popular Content
Showing content with the highest reputation on 11/26/20 in all areas
-
I come here to see what's new in development and find that there is a big uproar. Hate to say it, but I've been here a long time and community developers come and go and that's just the way it is. This unRAID product opens the door to personalizations, both private and shared. Community developers do leave because they feel that unRAID isn't going in the direction they want it to go or that the unRAID developers aren't listening to them even though there is no obligation to do so. Some leave in a bigger fuss than others. The unRAID developers do the best they can at trying to create a product that will do what the users want. They also do their best to support the product and the community development. The product is strong and the community support is strong and new people willing to put in time supporting it will continue to appear. Maybe some hint of what was coming might have eased tensions, but I just can't get behind users taking their ball and going home because unRAID development included something they used to personally support. That evolution has happened many times over the years, both incrementally and in large steps. That's the nature of this unRAID appliance type OS as it gets developed. There is no place for lingering bad feelings and continuing resentful posts. Hopefully, the people upset can realize that the unRAID developers are simply trying to create a better product, that they let you update for free, without any intent to purposely stomp on community developers.9 points
-
Wie kann ich eine Testlizenz erwerben, wie lange ist sie gültig und welchen Funktionsumfang bietet sie? Testlizenzen werden direkt in Unraid OS erworben (gehe dazu auf Extras > Registrierung) Die Testlizenz ist 30-Tage gültig und sie kann bis zu 2x um 15 Tage verlängert werden Testlizenzen bieten dir zeitlich begrenzten Zugriff auf Unraid OS in vollem Funktionsumfang und ohne Beschränkung auf angeschlossene Speichergeräte. Ist für Unraid eine aktive Internetverbindung erforderlich? Für dein Lizenztyp Basic/Plus/Basic: Nein Für Testlizenzen ist eine aktive Internetverbindung beim Serverstart erforderlich um die Probelizenz zu überprüfen. Welche Einschränkungen gibt es zwischen den Lizenztypen Basic/Plus/Pro? Basic: Bis zu 6 angeschlossene Speichergeräte Plus: Bis zu 12 angeschlossene Speichergeräte Pro: Keine Limitierung an angeschlossenen Speichergeräten Es gibt keine weiteren Einschränkungen der Software unabhängig vom Lizenztyp. Wieviele Speichergeräte kann ich im Array bzw. Cache verwenden? Unraid OS Pro unterstützt bis zu 30 Speichergeräte im Paritätsgeschütztem Array (28 Datenträger und 2 Paritätsdatenträger) und bis zu 24 Datenträger im Cache-Pool. Zusätzliche Speichergeräte können weiterhin direkt mit anderen Unraid-Funktionen wie VM's oder dem Plugin "Unassigned Devices" genutzt werden. Geräte die keine Datenträger sind wie GPU's zählen nicht zum Limit der angeschlossenen Speichergeräten. Das USB Bootgerät zählt nicht zu den angeschlossenen Speichergeräten. Wie lauten die Mindesthardwareanforderungen von Unraid OS? Ein 64-Bit-fähiger Prozessor mit 1GHz oder besser Mindestens 2GB RAM Linux-Hardwaretreiber für Speicher-, Ethernet, und USB-Controller Zwei Festplatten - um den Schutz deiner Dateien mit einer Paritätsfestplatte zu gewährleisten Je nach Anwendungstyp und installierten Apps und VM's können die Hardwareanforderungen dementsprechend höher sein. Sind Updates von Unraid OS Kostenpflichtig? Alle Lizenzschlüssel Basic/Plus/Pro enthalten kostenlose Updates auf neue Versionen von Unraid OS. Ist die Lizenz Hardwaregebunden? Die Lizenz ist an die GUID (Eindeutige ID) vom USB Startgerät gebunden somit kann bei einem Hardwaredefekt das USB Startgerät einfach an anderer Hardware angeschlossen werden und Unraid OS gestartet werden. Was passiert wenn mein USB Startgerät defekt ist? Sollte dein USB-Stick defekt sein, kannst du deinen Lizenzschlüssel einmal pro Jahr auf einen neuen USB-Stick übertragen. Wie kann ich eine Frage für diese Liste vorschlagen oder verbessern? Beteilige dich in dieser Diskussion.2 points
-
@S3ppo please try deactivating the subtitles2 points
-
Hey guys. We had a Corona virus scare over here (been super sick), so we've been dealing with that. I was hoping to have this out by tonight, but I am still working on it. I have the code written and the JSON is independently completed, but I have yet to integrate it into the UUD. And the the largest task of all is documentation and release notes (and that takes a LONG time). I've been going back and forth debating whether or not to release this independently as the Ultimate Plex Dashboard (UPD), or just integrate it into the UUD as version 1.5. I've decided to incorporate it into UUD, but for those of you who want a dedicated Plex Dashboard, I can release a standalone version of this as well, if there is enough demand. I'll post updates next week on a potential release date. I hope you all have a fantastic Thanksgiving!2 points
-
Before anyone else beats me to it: Soon™2 points
-
Best to use the DOS or UEFI tools to do any crossflashing and/or other more advanced options, e.g., for some reason erasing the BIOS doesn't work with the Linux version, but if you just need to update firmware it can be easily done with Unraid. Download the MSDOS firmware package form Broadcom's support site (https://www.broadcom.com/support/download-search), for example for the 9300-8i it currently is this one: 9300_8i_Package_P16_IR_IT_FW_BIOS_for_MSDOS_Windows Note: Downloads for SAS2 HBAs like for example the 9211-8i are usually under "Legacy Products" and then "Legacy Host Bus Adapters". Now download the Linux Installer, also from the firmware section, again for the 9300-8i it currently is: Installer_P16_for_Linux From the DOS package we only need the firmware: 9300_8i_Package_P16_IR_IT_FW_BIOS_for_MSDOS_Windows\Firmware\SAS9300_8i_IT\SAS9300_8i_IT.bin Optional: if the HBA has a BIOS installed and we want to updated it also copy the BIOS file: 9300_8i_Package_P16_IR_IT_FW_BIOS_for_MSDOS_Windows\sasbios_rel\mptsas3.rom From the installer package we only need sas3flash (sas2flash for SAS2 models): Installer_P16_for_Linux\sas3flash_linux_x64_rel\sas3flash Copy both files to your Unraid server, you can copy them to flash first but still need to copy them elsewhere since the executable can't be run from the flash drive, we also don't want them in the array since it should be stopped before flashing. For this example I first copied both files to folder called "lsi" in the flash drive then copied them to a temp folder I created called /lsi (this folder will be stored in RAM and gone after a reboot), use the console and type: mkdir /lsi cp /boot/lsi/* /lsi After copying the files navigate to that directory, in this case: cd /lsi We now need to make sas3flash executable with: chmod +x sas3flash Before flashing we can confirm the adapter (or adapters) are being detected and check what is the firmware currently installed: ./sas3flash -listall Avago Technologies SAS3 Flash Utility Version 17.00.00.00 (2018.04.02) Copyright 2008-2018 Avago Technologies. All rights reserved. Adapter Selected is a Avago SAS: SAS3008(C0) Num Ctlr FW Ver NVDATA x86-BIOS PCI Addr ---------------------------------------------------------------------------- 0 SAS3008(C0) 16.00.01.00 0e.01.00.07 08.37.00.00 00:01:00:00 1 SAS3008(C0) 16.00.01.00 0e.01.00.07 08.37.00.00 00:02:00:00 Make sure the array (and any UD devices using the HBA) is stopped and unmounted and now we can proceed with the upgrade, just use the standard sas3flash command, but remember that Linux is case sensitive, e.g.: ./sas3flash -o -f SAS9300_8i_IT.bin Optional: if you also want to flash the BIOS use ./sas3flash -o -f SAS9300_8i_IT.bin -b mptsas3.rom After it's done confirm the new firmware (and bios if also flashed) is installed: ./sas3flash -listall Avago Technologies SAS3 Flash Utility Version 17.00.00.00 (2018.04.02) Copyright 2008-2018 Avago Technologies. All rights reserved. Adapter Selected is a Avago SAS: SAS3008(C0) Num Ctlr FW Ver NVDATA x86-BIOS PCI Addr ---------------------------------------------------------------------------- 0 SAS3008(C0) 16.00.10.00 0e.01.00.07 08.37.00.00 00:01:00:00 1 SAS3008(C0) 16.00.01.00 0e.01.00.07 08.37.00.00 00:02:00:00 If there are multiple adapters like in this case only the first one will be flashed, to flash the other one use -c to specify the adapter#, e.g.: ./sas3flash -c 1 -o -f SAS9300_8i_IT.bin ./sas3flash -listall Avago Technologies SAS3 Flash Utility Version 17.00.00.00 (2018.04.02) Copyright 2008-2018 Avago Technologies. All rights reserved. Adapter Selected is a Avago SAS: SAS3008(C0) Num Ctlr FW Ver NVDATA x86-BIOS PCI Addr ---------------------------------------------------------------------------- 0 SAS3008(C0) 16.00.10.00 0e.01.00.07 08.37.00.00 00:01:00:00 1 SAS3008(C0) 16.00.10.00 0e.01.00.07 08.37.00.00 00:02:00:00 Finished Processing Commands Successfully. Exiting SAS3Flash. Now both are updated. P.S. to see more detailed info from an adapter we can use: ./sas3flash -list Avago Technologies SAS3 Flash Utility Version 17.00.00.00 (2018.04.02) Copyright 2008-2018 Avago Technologies. All rights reserved. Adapter Selected is a Avago SAS: SAS3008(C0) Controller Number : 1 Controller : SAS3008(C0) PCI Address : 00:02:00:00 SAS Address : 500605b-0-0b1c-2d00 NVDATA Version (Default) : 0e.01.00.07 NVDATA Version (Persistent) : 0e.01.00.07 Firmware Product ID : 0x2221 (IT) Firmware Version : 16.00.10.00 NVDATA Vendor : LSI NVDATA Product ID : SAS9300-8i BIOS Version : 08.37.00.00 UEFI BSD Version : 06.00.00.00 FCODE Version : N/A Board Name : SAS9300-8i Board Assembly : H3-25573-00H Board Tracer Number : SP60700521 Finished Processing Commands Successfully. If there's more than one we can again use -c, e.g.: ./sas3flash -c 1 -list1 point
-
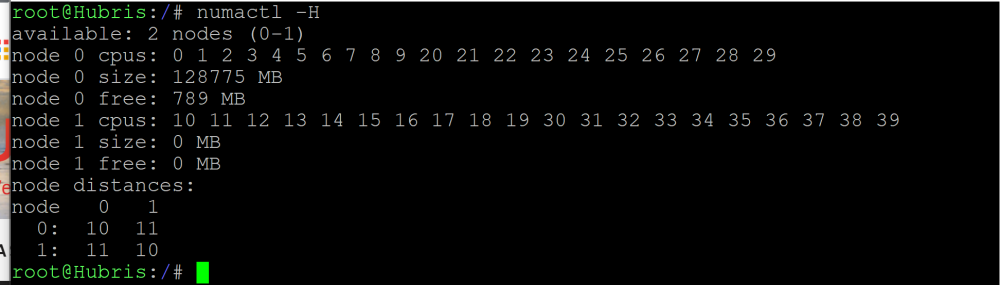
I see questions on Reddit and here on the forums asking about VM performance for Dual(or multi) socket motherboards. So I figured I’d write up a basic tuning guide for NUMA environments. In this guide I will discuss three things, CPU tuning, memory tuning and IO tuning. The three intertwine quite a bit so, while I will try to write them separate, they really should be considered as one complex tuning. Also, if there is one rule I recommend you follow it is this: don’t cross NUMA nodes for performance sensitive VMs unless you have no choice. So for CPU tuning, it is fairly simple to determine, from the command line, what CPUs are connected to which node. Issuing the following command: numactl -H Will give you a readout of which CPUs are connected to which nodes and should look like this: (Yes they are hyperthreaded 10-cores, they are from 2011 and your first warning should be that they are only $25USD a pair on eBay: xeon e7-2870, LGA1567) This shows us that CPUs 0-9 and their hyperthreads 20-29 are on node 0, it also shows us the memory layouts for the system, which will be useful later. With this layout pinning a VM to cores 0-7 and 20-27 would give the VM 8 cores and 8 threads all from one CPU. If you were to pin cores 7-14 and 27-34 your VM would still have 8 cores and 8 threads but now you have a problem for your VM, without tuning the XML, it has no idea that the CPU it was given is really on two CPUs. One other thing that you can do to help with latency is to isolate an entire CPU in the unRAID settings, (Settings>CPU Pinning). That would basically reserve the CPU for that VM and help reduce unnecessary cache misses by the VM. For memory tuning, you will need to add some XML to the VM to force allocation of memory from the correct node. That XML will look something like: <numatune> <memory mode='strict' nodeset='0' /> </numatune> For this snippet of XML mode=”strict” means that if there isn’t enough memory for the VM to allocate it all to this node then it will fail to start, you can change this to “preferred” if you would like it to start anyway with some of its memory allocated on another NUMA node. Lastly, IO tuning is a bit different from the last two. Before we were choosing CPUs and memory to assign to the VM based on their node, but for IO tuning the device you want to pass-through, (be it PCI or USB) the node is fixed and you may not have the same kind of resource(a graphics card) on the other node. This means that ultimately the IO devices you want to pass-through will, in most cases, actually determine which node your VM should prefer to be assigned to. To determine which node a PCI device is connected to you will first need that devices bus address, which should look like this: 0000:0e:00.0. To find the devices address in the unRAID webGUI go to Tools>System Devices then serach for your devices in the PCI Devices and IOMMU Groups box. Then open a terminal and issue the following commands: cd /sys/bus/pci/devices/[PCI bus address] cat numa_node The output should look like this: For my example here you can see that my device is assigned to NUMA node 0. I will point out that if you are passing multiple devices, (GPU, USB controller, NVMe drive) that they all might not be on the same node, in that case i would prioritize which node you ultimately assign your VM to based on the use of that VM. For gaming i would prioritize the GPU being on the same node personally but YMMV. Other thing that you can do to help with latency is to isolate an entire CPU for the a VM if it is for something like Gaming. That would basically reserve the CPU for that VM and help reduce unnecessary cache misses by the VM It can be easy to visualize NUMA nodes as their own computers. Each node may have its own CPU, RAM and even IO devices. The nodes are interconnected through high-speed interconnects but if one node wants memory or IO from a device on another node, it has to ask the other node for it, rather than address it directly. This request causes latency and costs performance. In the CPU section of this guide we issued the command “numactl -H” and this command also shows us the distance from one node to another, abstractly, with the nodes laid out in a grid showing distance from one node to another. The farther the distance, the longer the turnaround time for cross-node requests and the higher the latency. Advanced tuning: It is possible, if you have need of it, to craft the XML for a VM in such a way as to make the VM NUMA aware so that the VM is able to properly use two or more socketed CPUs. This can be done by changing both the <cputune> and <vcpu> tags. This is outside the scope of a basic tuning guide and I will just include a link to https://libvirt.org/formatdomain.html which included the entire specification for libvirt Domain XML, which the unraid VMs are written in.
 1 point
1 point -
Yes, the calculations for parity2 includes the drive slot number as one of the input variables while that for parity1 does not.1 point
-
Oh, and forgot to mention. Ensure that any and all variables, elements etc are 100% unique and not a generic naming so as to not interfere with any thing else now or in the future, or with any random plugin installed1 point
-
No, it doesn't.1 point
-
Docker runs fine for me, I've actually got two running simultaneously and they're both fine. I also get that warning in my logs but the docker works fine even with that warning: 0030:fixme:msvcp:_Locinfo__Locinfo_ctor_cat_cstr (00000000010CF4E0 1 C) semi-stub I had the exact same behaviour until I correctly port forwarded. I could see my lobby but couldn't connect to it: How many cores have you assigned to the ACC Server docker? If you left it all night and it finally got past that point, it sounds like you haven't got much power and it's taking a while to run. I had to assign more cores to the docker as mine all default to 1 core. Post a screenshot of your docker edit page (advanced mode) and share your ACC config files here and I'll double check them @hackspy6791 point
-
If you have a "settings" .page file, then you need to create another .page that'll inject the code Menu='Buttons' Link='nav-user' --- <? . . . ?> <script> . . . </script>1 point
-
Dalek Banner Size: 1920x90 Dynamix color theme: Black Unraid Version: 6.9.0 This is the preview

 1 point
1 point -
Look for used server pulls on ebay, those are much cheaper, avoid cheap new ones from China, could be fakes. Yep. Cache best to use onboard ports for trim, assuming SSDs, parity won't matter.1 point
-
One LSI with 16 ports is enough (plus the other 8 onboard ports), e.g., 9201-16i or 9300-16i, other option and probably cheaper would be two 9211-8i/9300-8i or similar.1 point
-
Works perfect anyway my apologies in misleading1 point
-
I can confirm that in my mobo, upgrading from 6.8.3 everything is working flawlessly, the cpu governor and performance in general is better than ever and bluestacks is finally working in my VMs. Hardware: X470 GAMING PRO CARBON (MS-7B78) | AMD Ryzen 9 3900x NO OC | Corsair Vengeance RGB Pro (4x16GB) DDR4 DRAM 2400MHz C16 | Geforce GTX 1060 3 GB, Intel 82576 Dual NIC Storage: Intel 660P NVME 1TB x 2 RAID-0 Cache | Seagate Barracuda 4 TB, 8 TB | Seagate IronWolf 4 TB Dockers: swag, Plex, Tautulli, NodeRed, MQTT, Wekan, Pydio, SageMath, Psono, ELK Stack, Sonarr, Radarr, Bazzar, TIG Stack VMs: Windows 10, Windows Server 2019, MacOS Catalina, Ubuntu 20.0.4, pfSense1 point
-
Fingers crossed as also getting realy tired when i have to reboot my whole server if i have a small change on my OSX VM with an 5700xt in an otherwise perfect unraid system.1 point
-
Das ist wirklich nur als Hilfe gemeint: Wenn du Chrome nutzt, kannst du mit nem Rechts-Klick recht einfach ganze Seiten ins deutsche Übersetzten. Ist manchmal echt Hilfreich, auch bei anderen Sprachen.1 point
-
Doh... sorry and thanks...1 point
-
Start here: https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=8191731 point
-
The settings you mention on apply to where Unraid attempts to place new files - it does not affect the placement of existing files. there are a number of choices for manually moving files: use the linux command line if you are familiar with Linux commands use the ‘mc’ command from the Linux command line for an easier to use interface install and use a docker container such a Krusader if you want a graphical interface enable disk shares under Settings->Global Share settings and use your preferred file manager on Windows/MacOS to do it over the network. This can be more convenient but will be slower than doing internally within the Unraid server. one thing to be aware of whatever option you use is to make sure all operations are either disk-to-disk or share-to-share. You should never mix disk and shares in the same command (I.e. disk-to-share or share-to-disk) as this can lead to data loss.1 point
-
@methanoid / @phat_cow - I can test is with a PCIEx extender cable that only transfer at 1x but it is a moderate effort, it is not that simple to do (my rig is watercooled, extra effort to move things between slots). What I think I can do without much effort is to convert the slot that is connected to my USB card to 1x using a BIOS option (I remember that I saw some cool PCIEx options in my Supermicro BIOS). I will give it a try but it will be a "soft" test, not a hard test. Wait for news.1 point
-
Vielen Dank, ich777, you made my day... dann werde ich gleich mal die plus Version angehen, damit das nicht nochmal passiert. Die deutsche Seite kannte ich auch noch nicht, und englisch ist nicht so mein Ding, wir hatten damals noch kein englisch in der Volksschule Vielen Dank für deine Hilfe, die Frage ist damit beantwortet, und ich bin wieder wunschlos glücklich:) LG Walter1 point
-
I am confused - Unraid will not automatically move files between array disks - this is a manual operation. Have I misunderstood what you actually did? Maybe posting your system’s diagnostics zip file (obtained via Tools -> Diagnostics might help with. working out. What. Is actually happening.1 point
-
Don't see much point, though just to confirm you can start one and stop as soon as there are errors. Yep, no need.1 point
-
You can do that, or just clone disk2 to a new disk then rebuild parity with that one, note that either way some data corruption is expected.1 point
-
I followed the guide here and was able to get a GTX 1650 Super I bought today up and running pretty easily. My i5-10400 struggled to transcode 4K HDR content to 1080p in Plex for remote streams (pegging the CPU), but now with this set up it's all offloaded to the GPU and working great. Nice work!1 point
-
Also If possible before rebooting and preferably with the array started Go to Tools - Diagnostics and attach the complete Diagnostics ZIP file to your NEXT post in this thread.1 point
-
1 point
-
JPs - Take alook at this post... https://forums.unraid.net/topic/61408-where-does-disk-encryption-stand/?do=findComment&comment=6378351 point
-
hmm thats interesting!, but sadly right now i dont have the time to investigate it, novnc in my opinion works quite well, even over a slow remote link so for now i am satisfied that novnc is still an acceptable connection method, but i may come back and take a look at Projector in the future.1 point
-
Yeah for the variables I tried that. What's persistent is the settings.json not the changes you do in the GUI. Remember I had to set the seed ratio in the Json directly. I rather have the variables instead of modifying a file from CLI Sent from my Pixel 2 XL using Tapatalk1 point
-
Checking to see if the VM is already running before issuing the VM start is NOT what I meant. You need some way of keeping the VM from trying to start automatically, for troubleshooting purposes. Consider the case where starting the VM immediately hangs the host, for whatever reason. You would be stuck in a loop of bouncing the host, and attempting to get access to kill the startup script before it initiates the VM and immediately hangs the host. You need an out of some sort to allow you to stop the auto start process cleanly. That conditional check, where something external is evaluated before starting the VM, is what I was referring to when I said not to blindly start the VM. It could be as simple as a script in the VM itself modifying a file on the host when it shuts down properly to signal it's OK to restart when needed. That way if the VM crashes for whatever reason, it's not blindly restarted.1 point
-
Next release of 6.9 will be on Linux 5.9 kernel, hopefully that will be it before we can go to 'stable' (because Linux 5.8 kernel was recently marked EOL).1 point
-
No problem, appreciate you looking into it anyway! If I can test at all, do let me know.1 point
-
Spoke to soon... Can't test or do anything if I don't own the game, eventually there is some sale in the next month or so...1 point
-
Found it and it verified the driver is working. You da man!!1 point
-
I've have been following this and the other thread with very mixed feelings and I feel the community is unjustly hard towards @limetech. Sure some things could have been handled better, yet I keep the feelings that the bigger injustice is not actually committed by him. In order to understand things better and to see things from a different perspective I personally like to make analogies. Sometimes it gives different insights into situations. And I cam up with the following for this one: We have 3 parties here, The parent (@limetech), the uncle (@CHBMB and the like) and the kid (the community). Now the situation is that the kid is asking the parent for this shiny new toy, but for whatever reason the parent is not buying the kid the toy. Maybe it is to expensive, maybe he is waiting for the birthday, whatever.. However, the uncle who hears the kid decided to get the kid this new toy, because he loved the kid and wants to please the kid. Fast forward and the parents sees that the kid really loved the toy but unfortunately the toy has some sharp edges and the parent is afraid the kid might hurt himself hence the parent decided to order a better and safer version of the toy. However, when the parent tells the kid it ordered this new toy the uncle hears the parent and flies into a rage because the parent did not tell the uncle that he/she was going to buy the new toy and the uncle thinks the parents is ungrateful because he/she did not even thank the uncle. In his rage therefore the uncle takes the toy away from the kid even before the new toy arrived (it is after all still in beta). Not only that but takes away the other toys he got the kid as well and says he is never going to give the kid any more toys. All this to punish the parent. Now with this analogy, ask yourself. Is the reaction of @CHBMB (the uncle) proportionate and justified? Does a parent (@limetech) need to inform the uncle of these kind of things? Sure it is nice, but is it really needed? Do you think it is right for the uncle to punish the kid? Should the parent even be grateful that the uncle presents the kid a toy with sharp edges (I know I wouldn't). The only one the uncle should expect thanks from i.m.o is the kid. The community is and was grateful. Yet @CHBMB is the one who decided to punish the community and take away their toy because of his hurt feelings. Yet the only one who gets shit is @limetech. If I where him I would be more than a little pissed and disappointment and I think it shows in his messages. Please read my analogy again and ask yourself who in the story did anything to hurt the kid? The parent or the uncle? And please also think about the fact that we have no way of knowing if @limetech was not going to thanks @CHBMB for the work in an official release note, which this wasn't. Now I do think the parent should have said something to the uncle. And I also am a bit disappointment to learn that even though UnRaid builds heavy on the community there is no special channel in place to facilitate communication with reliable community develops. Considering how well the development of both UnRaid and the community add-ons go together I kind of assumes something was already in place. However it seems this is something that is considered and worked on now. But in everything that happened, this simple miscommunication seems far the lesser evil here. And I do think it might be good that the community asks itself again who really is to blame for taking away it's shining toy with sharp edges and if it is reasonable to have this reaction. But that's just my 2 cents.1 point
-
@Gnomuz made a quite detailed report of the steps he took over there:1 point
-
This guy is pointing to this github, dont know if there is something to be done or added to the unraid kernel to add it? Im sick of having to reboot the whole server every time I need to reboot macos with the 5700xt and everything is so smooth and nice with every other vm I have with the nvidia card.1 point
-
still no thunderbolt support !1 point
-
Since there is a mylar3 image from linuxserver.io here ; https://fleet.linuxserver.io/image?name=linuxserver/mylar3 Will there be an update so it is in community applications? And will there be a new support thread or will this migrate over? Mylar only receives critical bug updates until end of life is announced. from https://github.com/evilhero/mylar "Note that feature development has stopped as we have moved to Mylar3. This means only critical bug errors will get addressed until such time as we decide not to continue supporting this version. EOL is still to be decided." Thanks in advance, MJ1 point
-
If it is working, then no need to upgrade. My backup server is an N40L which must be ~10 years old and has a 1.5Ghz dual core AMD cpu. This works fine even with a few dockers. Drive decisions really depend on drive health, however as they are ~5yr old risk is increasing. That said, I have some WD RE3 1TB drives I use for testing which are now ~ 12 years old with no errors though these haven't been in continuous service for many years. Dual parity is one option, though single parity with 2 x new 4TB array drives significantly reduces the chance of failure as you have all new drives. The original drives can then be used as additional backup for critical data or to make a raid 1 cache array (depending what you use the cache for) If these 'redundant' drives can be externalised, you can store the data somewhere away from the server. Good luck1 point
-
actualy i manage the bandwich prio per ip over my router.. this works so far.. but a global unraid setting would be a nice to have thing1 point
-
so I just switched over to the mylar3 docker by hotio, and its awesome. Much has been improved in mylar3 and seems to be working with no issues some tips from my experience... 1. I added path for my comics 2. I added the PUID = 99 and PGID = 100 variables 3. I had to move old mylar files from appdata/mylar/mylar to appdata/mylar/app, apparently hotio has that "app" subfolder hard coded in there. 4. start up mylar 3 and all was well Shout out and thanks to hotio!!1 point
-
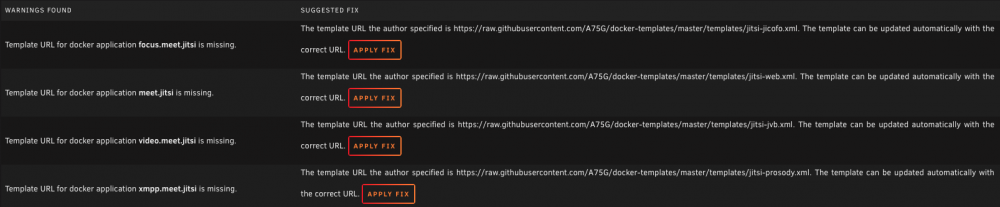
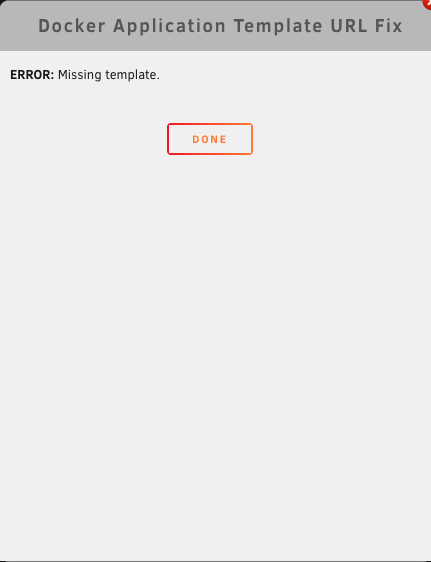
Hello, just installed Jitsi server and i'm getting this warning on CA Fix Problems. I tried to click Apply Fix and gave me an Error: Missing Template. Any thoughts? I tried installing the Jitsi server with encryption but failed so I had to install it without encryption. If that information help. Though if you do know how to install it with working encryption, please let me know as well. I followed Spaceinvader one's video to the tee minus Let's Encrypt as I used Nginx Proxy Manager instead. Thank you in advance for any help!
 1 point
1 point -
just need add to <features> , and add to <cpu mode='host-passthrough' check='none'>.1 point
-
drop the comma Rule: 10.0.0.100(sec=sys,rw) 10.0.0.101(sec=sys,rw)1 point
-
I got some motivation from the scripts posted here to add some monitoring to my UNRAID installation as well. I figured it was a bit less resource intensive to do it directly from bash but I'm totally guessing on that. I also wrote scripts for my DD-WRT router and windows PCs (powershell) but I figured for now I'd share the unraid scripts I wrote in case they are useful to anyone. I'm not that experienced with bash scripting so if there is anything I could do better I'd appreciate the corrections. All I ask is if you make improvements please share it back to me and the community. I actually created 3 scripts for different intervals. 1, 5 and 30 mins. Cron Jobs # # InfluxDB Stats 1 Minute (Delay from reading CPU when all the other PCs in my network report in) # * * * * * sleep 10; /boot/custom/influxdb/influxStats_1m.sh > /dev/null 2>&1 # # InfluxDB Stats 5 Minute # 0,10 * * * * /boot/custom/influxdb/influxStats_5m.sh > /dev/null 2>&1 # # InfluxDB Stats 30 Minute # 0,30 * * * * /boot/custom/influxdb/influxStats_30m.sh > /dev/null 2>&1 Basic variables I use in all 3 scripts. # # Set Vars # DBURL=http://192.168.254.3:8086 DBNAME=statistics DEVICE="UNRAID" CURDATE=`date +%s` CPU Records CPU metrics - Load averages and CPU time # Had to increase to 10 samples because I was getting a spike each time I read it. This seems to smooth it out more top -b -n 10 -d.2 | grep "Cpu" | tail -n 1 | awk '{print $2,$4,$6,$8,$10,$12,$14,$16}' | while read CPUusr CPUsys CPUnic CPUidle CPUio CPUirq CPUsirq CPUst do top -bn1 | head -3 | awk '/load average/ {print $12,$13,$14}' | sed 's/,//g' | while read LAVG1 LAVG5 LAVG15 do curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "cpuStats,Device=${DEVICE} CPUusr=${CPUusr},CPUsys=${CPUsys},CPUnic=${CPUnic},CPUidle=${CPUidle},CPUio=${CPUio},CPUirq=${CPUirq},CPUsirq=${CPUsirq},CPUst=${CPUst},CPULoadAvg1m=${LAVG1},CPULoadAvg5m=${LAVG5},CPULoadAvg15m=${LAVG15} ${CURDATE}000000000" >/dev/null 2>&1 done done Memory Usage top -bn1 | head -4 | awk '/Mem/ {print $6,$8,$10}' | while read USED FREE CACHE do curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "memoryStats,Device=${DEVICE} memUsed=${USED},memFree=${FREE},memCache=${CACHE} ${CURDATE}000000000" >/dev/null 2>&1 done Network if [[ -f byteCount.tmp ]] ; then # Read the last values from the tmpfile - Line "eth0" grep "eth0" byteCount.tmp | while read dev lastBytesIn lastBytesOut do cat /proc/net/dev | grep "eth0" | grep -v "veth" | awk '{print $2, $10}' | while read currentBytesIn currentBytesOut do # Write out the current stats to the temp file for the next read echo "eth0" ${currentBytesIn} ${currentBytesOut} > byteCount.tmp totalBytesIn=`expr ${currentBytesIn} - ${lastBytesIn}` totalBytesOut=`expr ${currentBytesOut} - ${lastBytesOut}` # Prevent negative numbers when the counters reset. Could miss data but it should be a marginal amount. if [ ${totalBytesIn} -le 0 ] ; then totalBytesIn=0 fi if [ ${totalBytesOut} -le 0 ] ; then totalBytesOut=0 fi curl -is -XPOST "$DBURL/write?db=$DBNAME&u=$USER&p=$PASSWORD" --data-binary "interfaceStats,Interface=eth0,Device=${DEVICE} bytesIn=${totalBytesIn},bytesOut=${totalBytesOut} ${CURDATE}000000000" >/dev/null 2>&1 done done else # Write out blank file echo "eth0 0 0" > byteCount.tmp fi Hard Disk IO # Gets the stats for disk# # # The /proc/diskstats file displays the I/O statistics # of block devices. Each line contains the following 14 # fields: # 1 - major number # 2 - minor mumber # 3 - device name # 4 - reads completed successfully # 5 - reads merged # 6 - sectors read <--- # 7 - time spent reading (ms) # 8 - writes completed # 9 - writes merged # 10 - sectors written <--- # 11 - time spent writing (ms) # 12 - I/Os currently in progress # 13 - time spent doing I/Os (ms) # 14 - weighted time spent doing I/Os (ms) # # Special Cases # sda = Flash/boot # sdf = Cache # sdd = Parity if [[ -f diskByteCountTest.tmp ]] ; then cat /proc/diskstats | grep -E 'md|sdd|sda|sdf|loop0' | grep -E -v 'sd[a-z]1' |sed 's/md//g' | awk '{print "disk" $3, $6, $10}' | while read DISK currentSectorsRead currentSectorsWrite do # Check if the disk is in the temp file. if grep ${DISK} diskByteCountTest.tmp then grep ${DISK} diskByteCountTest.tmp | while read lDISK lastSectorsRead lastSectorsWrite do # Replace current disk stats with new stats for the next read sed -i "s/^${DISK}.*/${DISK} ${currentSectorsRead} ${currentSectorsWrite}/" diskByteCountTest.tmp # Need to multiply by 512 to convert from sectors to bytes (( totalBytesRead = 512 * (${currentSectorsRead} - ${lastSectorsRead}) )) (( totalBytesWrite = 512 * (${currentSectorsWrite} - ${lastSectorsWrite}) )) (( totalBytes = totalBytesRead + totalBytesWrite)) # Cases case ${DISK} in "disksda" ) curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStats,Disk=boot,Device=${DEVICE} BytesPersec=${totalBytes},ReadBytesPersec=${totalBytesRead},WriteBytesPersec=${totalBytesWrite} ${CURDATE}000000000" >/dev/null 2>&1 ;; "disksdd" ) curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStats,Disk=parity,Device=${DEVICE} BytesPersec=${totalBytes},ReadBytesPersec=${totalBytesRead},WriteBytesPersec=${totalBytesWrite} ${CURDATE}000000000" >/dev/null 2>&1 ;; "disksdf" ) curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStats,Disk=cache,Device=${DEVICE} BytesPersec=${totalBytes},ReadBytesPersec=${totalBytesRead},WriteBytesPersec=${totalBytesWrite} ${CURDATE}000000000" >/dev/null 2>&1 ;; "diskloop0" ) curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStats,Disk=docker,Device=${DEVICE} BytesPersec=${totalBytes},ReadBytesPersec=${totalBytesRead},WriteBytesPersec=${totalBytesWrite} ${CURDATE}000000000" >/dev/null 2>&1 ;; *) curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStats,Disk=${DISK},Device=${DEVICE} BytesPersec=${totalBytes},ReadBytesPersec=${totalBytesRead},WriteBytesPersec=${totalBytesWrite} ${CURDATE}000000000" >/dev/null 2>&1 ;; done else # If the disk wasn't in the temp file then add it to the end echo ${DISK} ${currentSectorsRead} ${currentSectorsWrite} >> diskByteCountTest.tmp fi done else # Write out a new file cat /proc/diskstats | grep -E 'md|sdd|sda|sdf|loop0' | grep -E -v 'sd[a-z]1' |sed 's/md//g' | awk '{print "disk" $3, $6, $10}' | while read DISK currentSectorsRead currentSectorsWrite do echo ${DISK} ${currentSectorsRead} ${currentSectorsWrite} >> diskByteCountTest.tmp done fi Number of Dockers Running docker info | grep "Running" | awk '{print $2}' | while read NUM do curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "dockersRunning,Device=${DEVICE} Dockers=${NUM} ${CURDATE}000000000" >/dev/null 2>&1 done Hard Disk Temperatures # Current array assignment. # I could pull the automatically from /var/local/emhttp/disks.ini # Parsing it wouldnt be that easy though. DISK_ARRAY=( sdd sdg sde sdi sdc sdb sdh sdf ) DESCRIPTION=( parity disk1 disk2 disk3 disk4 disk5 disk6 cache ) # # Added -n standby to the check so smartctl is not spinning up my drives # i=0 for DISK in "${DISK_ARRAY[@]}" do smartctl -n standby -A /dev/$DISK | grep "Temperature_Celsius" | awk '{print $10}' | while read TEMP do curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "DiskTempStats,DEVICE=${DEVICE},DISK=${DESCRIPTION[$i]} Temperature=${TEMP} ${CURDATE}000000000" >/dev/null 2>&1 done ((i++)) done Hard Disk Spinup Status # Current array assignment. # I could pull the automatically from /var/local/emhttp/disks.ini # Parsing it wouldnt be that easy though. DISK_ARRAY=( sdd sdg sde sdi sdc sdb sdh sdf ) DESCRIPTION=( parity disk1 disk2 disk3 disk4 disk5 disk6 cache ) i=0 for DISK in "${DISK_ARRAY[@]}" do hdparm -C /dev/$DISK | grep 'state' | awk '{print $4}' | while read STATUS do #echo ${DISK} : ${STATUS} : ${DESCRIPTION[$i]} if [ ${STATUS} = "standby" ] then curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStatus,DEVICE=${DEVICE},DISK=${DESCRIPTION[$i]} Active=0 ${CURDATE}000000000" >/dev/null 2>&1 else curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "diskStatus,DEVICE=${DEVICE},DISK=${DESCRIPTION[$i]} Active=1 ${CURDATE}000000000" >/dev/null 2>&1 fi done ((i++)) done Hard Disk Space # Gets the stats for boot, disk#, cache, user # df | grep "mnt/\|/boot\|docker" | grep -v "user0\|containers" | sed 's/\/mnt\///g' | sed 's/%//g' | sed 's/\/var\/lib\///g'| sed 's/\///g' | while read MOUNT TOTAL USED FREE UTILIZATION DISK do if [ "${DISK}" = "user" ]; then DISK="array_total" fi curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "drive_spaceStats,Device=${DEVICE},Drive=${DISK} Free=${FREE},Used=${USED},Utilization=${UTILIZATION} ${CURDATE}000000000" >/dev/null 2>&1 done Uptime UPTIME=`cat /proc/uptime | awk '{print $1}'` curl -is -XPOST "$DBURL/write?db=$DBNAME" --data-binary "uptime,Device=${DEVICE} Uptime=${UPTIME} ${CURDATE}000000000" >/dev/null 2>&1 Disk 4 and 5 just finished their file integrity check. I also have a hole every day at 11:36-12:36 that I haven't yet figured out why. I'll need to investigate that but I dont think its related to these scripts. If anyone wants the grafana json just let me know I can post it as well. Please post any suggestions of other metrics to capture.1 point































