Leaderboard



Popular Content
Showing content with the highest reputation on 09/09/21 in all areas
-
Too much information3 points
-
THAT is beautiful, i would def wear that ALL the time, even in the bath with plenty of bubble bath and a glass of 'cristal' champagne in my hand of course to finish off the look 🙂3 points
-
Do you have Turbo Mode / Recontruct Write activated ? or Squid's Auto Turbo Write Mode plugin ? It might explain why all drive spin up ?2 points
-
I figured others might be interested in how to get a Bluetooth keyboard and mouse connected to their unRAID server so i wrote this short guide as my introductory post to the unRAID forums. I realize there’s probably limited use for this, but in my case I have a multi device keyboard and mouse and I can switch between them easily which is why I am using this on unRAID, it’s convenient for me. System Requirements You need to be running at least 6.7 as this includes the Bluetooth kernel drivers, you also need to install NerdPack and select the bluez package. Getting it all Working Once you’ve satisfied the system requirements, open a terminal on unRAID and execute: /etc/rc.d/rc.bluetooth start bluetoothctl You should see Agent Registered and be at the Bluetooth prompt: Put your device in pairing mode and execute: scan on You should see the device appear in the list as it scans, note the <address> then execute: pair <address> Note: After the pair you might get promoted to do something like enter a passcode in the case of a keyboard, enter the displayed number and press return. Repeat the pairing process for any other devices. Once pairing is confirmed on screen, execute: trust <address> connect <address> Type “exit” to quit. Now we need to make this configuration persistent across boots, so execute: cd /var/lib tar -czvf /boot/config/bluetooth.tgz bluetooth Note: This saves the paired devices to an archive, you will need to repeat this step if you pair other devices in the future. Edit the go.cfg config file so it restores the Bluetooth configuration and start the Bluetooth daemon from the go file on boot. cd /boot/config nano go Before the line that starts emhttp add the following lines: tar xvzf /boot/config/bluetooth.tgz -C /var/lib /etc/rc.d/rc.bluetooth start hciconfig hci0 up Hit ctrl-x and then press y to save the modified go file. That’s it, upon reboot the Bluetooth configuration will be restored before the service is started.1 point
-
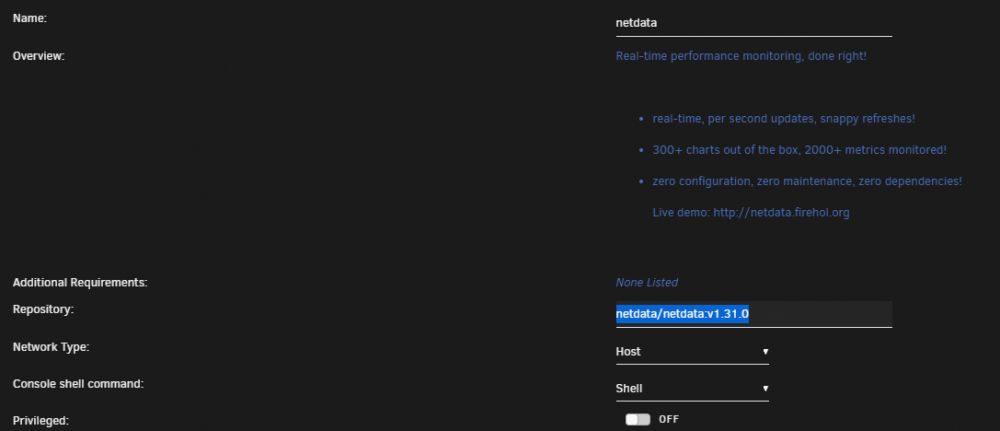
i had the same issue. after the latest update netdata didnt work. everyone who has the same issue just go back go the version before. netdata/netdata:v1.31.0
 1 point
1 point -
Although I can see why such a message might be output I am not seeing it on my system Exactly which version of Unraid are you running? EDIT: Reverted the system to 6.9.1 (it was on 6.10.0 rc1) and now see the error you mention which will help with resolving. I need to see if it also occurs on 6.9.2 It looks as if I might have broken something that affects the display of Settings->Scheduler page on 6.8.3 so that is definitely going to need fixing. As I can reproduce your symptom I will make sure that is fixed as well.1 point
-
Hey, although I have an AMD build, what you've listed is essentially what I've been doing with my setup. I've had great results, everything is listed in my signature below.1 point
-
hab mal schnell geschaut ... so einfach sieht das nicht aus da selbst die custom:br0 Anzeigen auch keine Logik haben wie in meinem Beispiel ... das ist weder eine Echtabfrage noch was im template hinterlegt ist noch was als expose hinterlegt ist im dockerfile an sich. Da muss ich jetzt doch passen und andere haben da vielleicht eher eine Idee die "Echtabfrage" zu gestalten der docker zugehörigen listen ports1 point
-
So my buddy and I tried his server again this morning.. and now his is working. He swears he changed nothing. Wasn't working now it is.. maybe mine just needs to cook for a bit longer. At this point just consider me a lunatic.. because I have no idea what is going on with this.1 point
-
@GuildDarts Apologies if this isn't really a suitable place for this, but thought I'd ask - As a feature request, what about the possibility of adding simple folder functionality to the User Scripts page as well (plugin from @Squid)? I was helping a friend with their unpaid server last night, having him walk me through the steps he'd taken to recreate an issue, and in the course of this saw his user scripts page... It had something like 40+ scripts that he'd accumulated, of which around half of them were manual activation only and used infrequently (though I confirmed he *does* actually still use them). It was a mess of scrolling lol. I mostly just use cron, so I'd not really experienced this, but I'd imagine there are others who'd similarly benefit from some organization ability in the user scripts space. The reason I came to ask here was that we've already got the great folder functionality for docker and VMs in the plugin, and thought to check if this kind of thing was in line with the spirit of the plugins purpose; I could foresee having folders/buttons for each of the options (daily/weekly/monthly/etc), then selecting one of them to drop-down the contents of each and display them as they would normally. If this doesn't really jive with the existing plugin's purpose/design (and I'd understand for sure, as these are static displays that don't really need 'monitoring', and that monitoring is one of the huge values of this plugin), no worries at all, and I'll hit up @Squid's plugin's support page. Thanks for taking the time!1 point
-
Or go 10G there as well...30m is a bit tight over cat5e...you could try and maybe still end up with a 2.5G or even 5G link. When you move to cat6// do use these: https://www.fs.com/de/products/87588.html ...they're specified for 80m...technology moves on Not sure if these offer fallback to 2.5G/5G or are only 1/10G. 10m a bit beyond standard...I would not dare to go above 7m with these. ....looks like a plan. Good luck!1 point
-
I don't recommend high sierra if you care about security. Latest oses which are receiving security updates are Mojave, Catalina, and Big Sur (support for Mojave will end when Monterey will come out). And usually it's better to have the latest os, so for the time being, I would recommend Big Sur. Moreover, I don't know if Catalina/Mojave are affected by the same issue (patch VMM to XXX not working), as this thing could have been introduced with latest security updates for all supported oses.1 point
-
👍 Those bar colors hurt my eyes1 point
-
Hi, there's no solution at the time of writing for recent version of big sur (>=11.3), so applying the mentioned patch to the kernel is not enough. Apple in recent os checks for some other and that's why we are still unable to enable content cache. It's far from my knowledge on how to write a new patch, because it could require the coding of a lilu plugin. Apple is also changing a lot of things with monterey and ota delta updates: we are aware of what's causing this, but changes to bootloader are in standby, and they will be probably pushed in a pr when monterey release will be out.1 point
-
Technically yes, I think...but will it "fit" into your rooom setup? I just ordered a pair of these: https://www.amazon.de/gp/product/B091F3RZDF/ref=ppx_yo_dt_b_asin_title_o03_s01?ie=UTF8&th=1 ... they work well with the MT CSS610 and CRS326. A length of 0.5m of a fiber wire/DAC is really short...mind you that you cannot bend them like the copper counterparts....this length is only good for two ports that quite near. Also 5m of cable between server room and office room.....mind you, you could still wind up some exxecc-slopes on either end...you can cover 300m Do you wnat to replace the core switch with the CRS309 or just add the CRS309 to your setup? see above. What exactly are the numbers? The CRS309 has one 1G port already, besides the 8x10G. You could use this to link to your existing core switch....then add 1G modules as you suggest (if at alle necessary). If you do not need the extra ports, you don't need the CSS in the server room....you can add it later anyway. see above...I am more worried about the 5m fiber ... rather go for 10m...for anything below real 7m, you could use a DAC as well. Welcome to the club. What I do in such cases is, draw a diagramm and make one for each variant. -> https://app.diagrams.net/ My opinion is, that an extra CSS610 will proof more flexible in the future.1 point
-
Ich habe das so verstanden, dass er keinen tag nutzt = latest und die ganze Zeit die Meldung für ein Update bewusst ignoriert, damit er bei der alten Version bleibt. Daher schlug ich ja vor, dass er einen tag setzt, damit er auf die Art die alte Version des Containers erzwingt.1 point
-
Mission accomplished. The Inateck arrived half an hour ago, and everything went smooth as silk: Install->Bind to VFIO->Select in VM->Soundsticks playing perfectly. Update: Avoid installing the genuine Inateck drivers for Windows with this device in a VM. It will interfere with the PCIe device reset and cause error 127. The generic Microsoft driver works fine.1 point
-
Das hier ist "in der Regel" die selbe Nummer wie die SATA Buchse auf dem Mainboard / in der Anleitung / im BIOS bezeichnet wird: Muss aber nicht zwangsläufig so sein.
 1 point
1 point -
For those suffering issues during restart/shutdown, I can share what worked for me. In config.plist, under NVRAM > boot-args, add vti=12 (in reality, you can pick any number you want) VTI is a multiplier the macOS kernel uses to extend the allowable timeout when waiting for cores to synchronise, when running in a virtual machine (this is an oversimplification, but conveys the idea). This isn't needed when running on bare metal, as the kernel can reasonably expect all cores to behave (relatively) predictably. As our VMs are sharing CPU resources with the host, this assumption doesn't hold, so we can extend the allowable time before the macOS kernel panics. Nice that it's built in, too. The number you choose represents the number of times to multiply the default by two (binary left-shifts). Don't set the number too large (<<32), or it will eventually overflow (and cause the effective value to be zero – worse than the default). See here for where I found this solution originally, with more technical details: https://www.nicksherlock.com/2020/08/solving-macos-vm-kernel-panics-on-heavily-loaded-proxmox-qemu-kvm-servers/ This resolved all of my occasional panics both during use of the VM day-to-day, and during shutdown/restart of the VM. I think that on my machine, these panics were causing my PCIe devices (GPU [RX580] & USB [ASM3142]) to be left in some undefined state – in turn causing crashes of the Unraid host. Very occasionally, the hardware would detect this (PCIe bus error warnings from iDrac) allowing Unraid to keep working, but would require a full restart to reset the devices and restore the bus. Good luck!1 point
-
Auch die Nummerierung in den Devices ist im Linux Kernel "willkürlich", kann sich also von Version zu Version und MB zu MB unterscheiden. Wenn Du das herausfinden willst, einfach mal testen (eine bekannte DIsk an- / abstöpseln und vergleichen...dann kommmt man auf die aktuelle gültige Systematik. Aber wir @ich777 schon sagte....für unraid Nutzung ist das unerheblich.1 point
-
Buenos días, Me parece genial la idea que habéis llevado a cabo. Estoy probando Unraid a ver si puedo darle una "patada" a Xpenology y hay muchas cosas que tengo que aprender. Hay muchos recursos en internet pero muy poco en español, quitando vuestros canales de telegram (en los que estoy metido), pero el canal de telegram puede ser un poco caótico para gente como yo, que estamos empezando y que tenemos muchas lagunas, por eso vuestra iniciativa de la web me parece del todo acertada. No os entretengo más. Muchas gracias por vuestro trabajo y dedicación. Un saludo y gracias de nuevo.1 point
-
Done. Just rebooted into safe mode now and manually spun the array down. Ill just leave it alone now. I can get a good 5 hours of safe mode in before the family sit down for the night and wan their media server back.1 point
-
@Saiba Samurai Sorry to hear you are having issues getting ARK servers up and running. Just out of curiosity what kind of router are you using for your port forwarding and are you using stock firmware on the router or a third party firmware. Not that it should make any difference for port forwarding but just wanted to ask in case someone else has had similar issues with the same router/firmware. Also, when setting up your custom network to run your servers on is the IP Address within the same network subnet mask as your main network? I saw in your screenshot that your custom network you tried using is 192.168.20.117. Is your router IP set at 192.168.20.1?1 point
-
The rule is no data drive can be larger than parity. An 8TB drive will work just fine since you don't have any data drives larger than that. It's true you can't ever rebuild a data drive to a smaller one, but that doesn't apply here. Just remove the failed drive, assign the 8TB to the parity slot, and start the array to build parity.1 point
-
UPDATE: The above steps fixed my original issue. Thanks, @alturismo!1 point
-
Is gold plated ok? Congratulations @binhex!
 1 point
1 point -
Yes, but I'm actually from Austria and I speak German and I use the German version from the container. Please update the container by turning on the Advanced View on the Docker page and click, should be fixed now. Seems like this was language specific...
 1 point
1 point -
Yes - but is done in real time as the data is copied. It is the overhead of simultaneously updating the parity as described here that causes write speeds to the array to be relatively slow.1 point
-
A ‘correcting’ check means that if a mismatch is found between the array drives and the parity disk then Unraid should automatically assume the data disks are correct and it is the parity disk that is wrong and alter the parity disk so it again matches the data disks. In the normal scheduled (monthly?) check one should expect 0 errors being reported and as long as then in that case it makes no difference whether the check was a correcting one or not. It is only if you get a non-zero value that you want to look into why.1 point
-
Since you apparently had scheduled checks running too frequently, changing the schedule might be the fix for all the parity checks you were getting, but... Do you know why you had an unclean shutdown?1 point
-
It means scheduled parity checks will be correcting checks. Not recommended for reasons already given.1 point
-
I've done all performance improving steps I could find (from that thread and many elsewhere), but I'm pretty sure I've narrowed it down to being a network issue. I had this problem when I first upgraded on release, and quickly reverted. I didn't realize until recently that it's the same problem so I'll revive my previous thread I started at that time. I appreciate your help regardless, though!1 point
-
It is normally recommended that the option to Write Corrections as part of a scheduled test set to No. the rationale is that if you have a disk that is playing up and you have not realised it you do not want to allow it to corrupt parity thus potentially prejudicing good recovery of any other disk that might have problems. I always suggest to not write corrections to parity until you have rectified (and hopefully fixed) whatever caused the problem in the first place.1 point
-
Never tried anything other than a monthly parity check on a fixed date, so I can be mistaking. Your setting look a lot like Parity check runs : every day of every week for January, May and September And since we are in September ... Maybe try to pick a day and a week ?1 point
-
worth a shot at these instructions, works for me and im on a fairly newish board (Asus ROG Strix x470-f Gaming):- https://forums.unraid.net/topic/34889-dynamix-v6-plugins/page/102/?tab=comments#comment-7896061 point
-
Ah - misunderstood your problem. I was assuming either a reboot or a shutdown/restart. As far as I know the only way to automatically start a parity check while running is via what is set under Settings->Scheduler so you might check those. The contents of /etc/cron.d/root might also be worth posting as a check.1 point
-
Item 6 is not quite true - the reboot is not necessarily ‘safe’. I t is only ‘safe’ if the timeouts for stopping docker containers, VMs and unmounting disks are not triggered AND the shutdown status can be recorded on the flash drive. It would be ‘safe’ if prior to clicking on Reboot you had first used the ’Stop’ option to stop the array and that had succeeded. I would suggest that you try: clicking the ‘Stop’ option to ensure that the the docker and VM services can be stopped and the disks unmounted, and time how long that takes. If the system sticks on trying to unmount the disks then you will need to investigate what is preventing that from happening and rectify that. Assuming that the Stop completes you can now try the Reboot to confirm the system was able to update the flash drive and the reboot no longer causes an automatic parity check. If that is OK you now have the information you need to adjust the timeouts to get clean reboots in the future.1 point
-
Hey everyone, this issue with repeated lock outs should now be resolved, you should no longer have to manually delete any cookies.1 point
-
****** Please use the Official Template for Photostructure instead of this one ******* You have an offical template now folks - my beta template will be retired.1 point
-
Hello. Folowing mariaDB update hi experienced the same problem. MariaDB was updated while nextcloud was running. i don't know if this is wyse to do it like this, but i wanted to test and see what happenend. and of course it crashed with the same problem. following instructions posted by @whitedwarfi have done the following steps shut down docker nextcloud shut down docker mariaDB edited mariaDB docker and Changed the mariadb docker repository to "linuxserver/mariadb:110.4.21mariabionic-ls31" started the mariaDB docker waited 5mins for cpu utilization to idle on the docker shut down the mariadb docker edited mariaDB docker and Changed the mariadb docker repository to "linuxserver/mariadb:latest" started the mariaDB docker waited 5mins for cpu utilization to idle on the docker started nextcloud docker. Webui for nextcloud up and running again. many thanks to @whitedwarffor the solution. 🙏1 point
-
...I do not buy new stuff at the bay, except part originated from china. For MT in Europe, look at eurodk.de ... at least for Germany, they ship it internally to a distribution centre in Germany and the stuff gets then forwarded via DHL...tracking et al works fine. The are also listed in price-portals but tend to be more expensive there. When buying directly from them, I think their standard policy for returns is, that you'll have to pay postage and packing yourself/upfront (at least for things you just deem unfit after inspection and return them...not for DOA/damaged stuff). ...see above MT is very much open for every brand, I think...they definitely have no vendor lock. Yes they should work, but these are just 1G. I'd not waste a SFP+ port for 1G port on a CRS309...it already has one, btw. For fan-out of more 1G ports, I'd combine the CRS309 with a CSS610: https://www.eurodk.de/de/products/crs/cloud-smart-switch-610-8g-2s-in (or even use a CRS/CSS326) Then use a DAC between them1 point
-
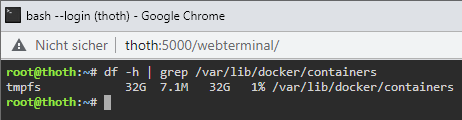
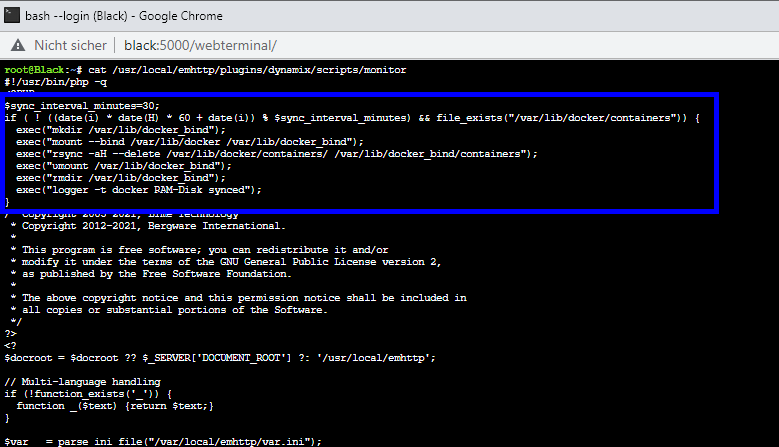
@limetech I solved this issue as follows and successfully tested it in: Unraid 6.9.2 Unraid 6.10.0-rc1 Add this to /boot/config/go (by Config Editor Plugin): Optional: Limit the Docker LOG size to avoid using too much RAM: Reboot server Notes: By this change /var/lib/docker/containers, which contains only status and log files, becomes a RAM-Disk and therefore avoids wearing out your SSD and allows a permanent sleeping SSD (energy efficient) It automatically syncs the RAM-Disk every 30 minutes to your default appdata location (for server crash / power-loss scenarios). If container logs are important to you, feel free to change the value of "$sync_interval_minutes" in the above code to a smaller value to sync the RAM-Disk every x minutes. If you like to update Unraid OS, you should remove the change from the Go File until it's clear that this enhancement is still working/needed! Your Reward: After you enabled the docker service you can check if the RAM-Disk has been created (and its usage): Screenshot of changes in /etc/rc.d/rc.docker and /usr/local/emhttp/plugins/dynamix/scripts/monitor


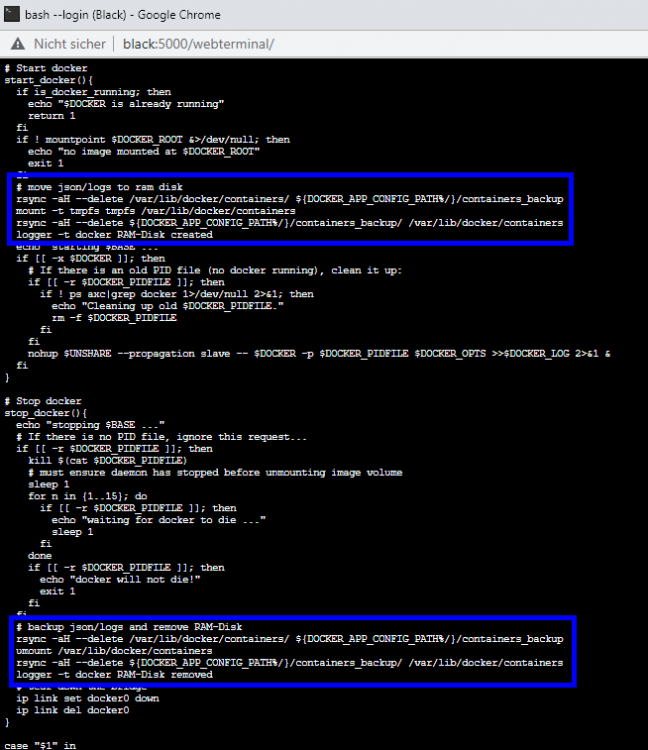 1 point
1 point -
Is anyone else having issues with memory ballooning not working in VMs? I check my linux VMs and they have virtio_ballooning loaded, but their memory won't increase past initial size. I'm using an ASROCK Creator TRX40 w/ Ryzen Threadripper 3970X 64G DDR4. I'm using the rule initial memory is 1core=1G and Max is 1core=2G. I'm doing this on 3 VMs 8core, 8core, and 4core. None of which see their memory balloon while compiling software and they end up crashing with OOM errors. oceans-diagnostics-20210528-1427.zip1 point
-
Yeah not exactly what you asked for, but we do have a Discord notification agent now in 6.9.0 P.S. thanks for the feedback and help with testing!1 point
-
Thanks both denishay & saarg both helped alot to get to right solution Ended up with: shell docker exec -it nextcloud bash cd /config/www/nextcloud/ sudo -u abc php7 occ files:scan --all Its running the filescan now. Thanks both of you! i owe you many hours in saved time on this1 point
-
I never used the script, it may have issues with latest unRAID, you can still do it manually (array will be inaccessible during the clear): 1. If disable enable reconstruct write (aka turbo write): Settings -> Disk Settings -> Tunable (md_write_method) 2. Start array in Maintenance mode. (array will not be accessible during the clearing) 3. Identify which disk you're removing 4. For Unraid <6.12 type in the CLI: dd bs=1M if=/dev/zero of=/dev/mdX status=progress For Unraid 6.12+ type in the CLI: dd bs=1M if=/dev/zero of=/dev/mdXp1 status=progress replace X with the correct disk number 5. Wait, this will take a long time, about 2 to 3 hours per TB. 6. When the command completes, Stop array, go to Tools -> New Config -> Retain current configuration: All -> Apply 7. Go back to Main page, unassign the cleared device. * with dual parity disk order has to be maintained, including empty slot(s) * 8. Click checkbox "Parity is already valid.", and start the array1 point






























