Leaderboard


Popular Content
Showing content with the highest reputation on 01/19/21 in all areas
-
Wer es noch nicht wusste: Bald können wir für jeden Kleinkram zum Zoll laufen und Gebühren zahlen. Ab dem 01.07. ist es soweit. Ich glaube ich bestelle ab dann jeden Tag einen 1 Cent Artikel und hole ihn nicht ab. Das nennt man dann DoS Attacke ^^2 points
-
You can make a folder called "custom-cont-init.d" in the /config folder location and put a script in there. It gets executed during start/restart of the container. This applies to Linuxserver containers only, that I know of. Read more here, under "Custom Scripts".2 points
-
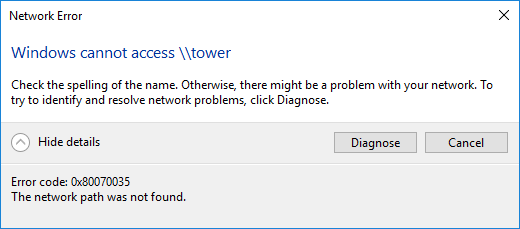
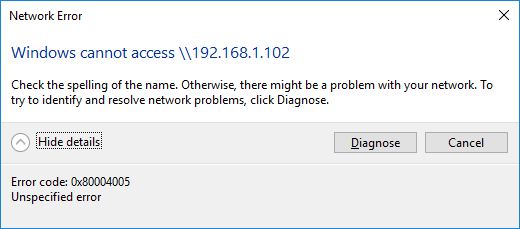
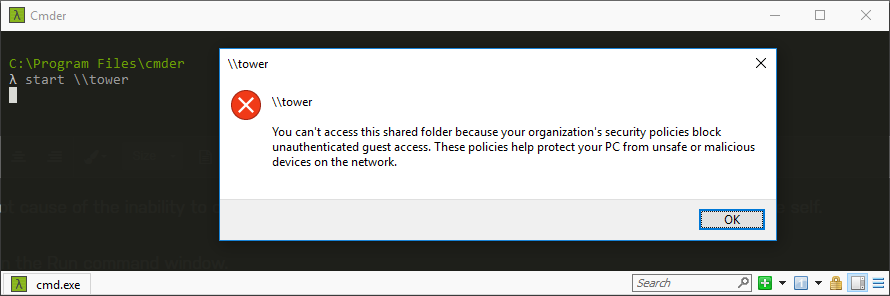
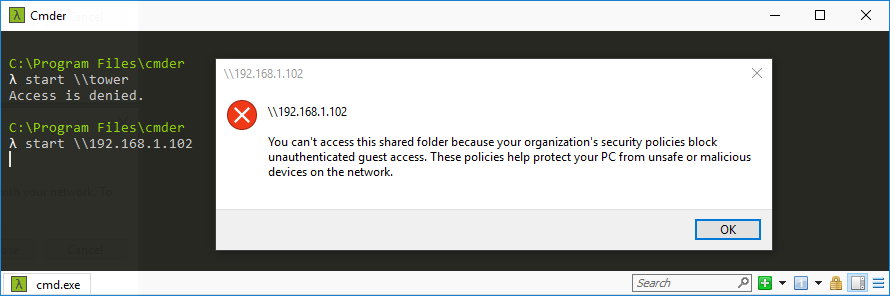
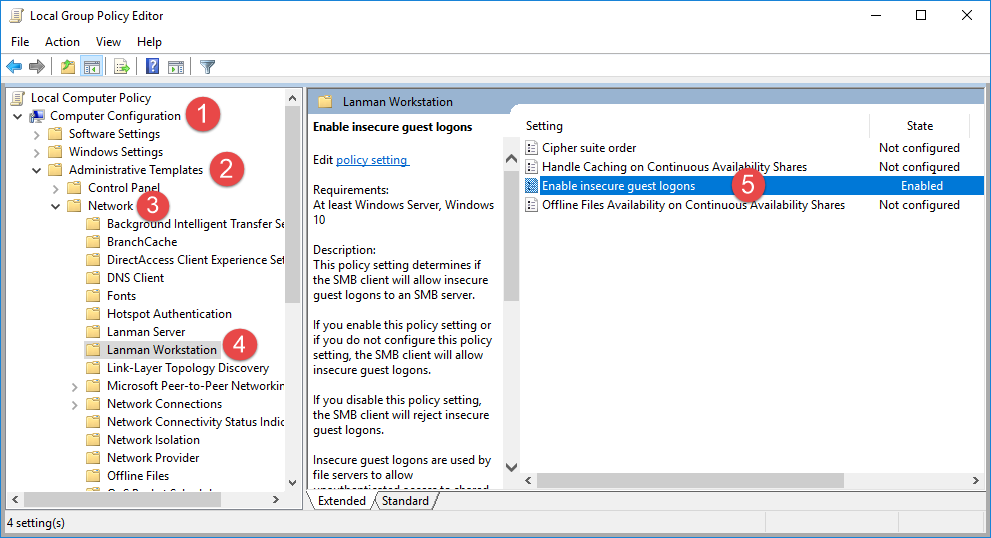
Tons of posts related to Windows 10 and SMB as the root cause of the inability to connect to unRaid that were fruitless so I'm recording this easy fix for my future self. If you cannot access your unRaid shares via DNS name ( \\tower ) and/or via ip address ( \\192.168.x.y ) then try this. These steps do NOT require you to enable SMB 1.0; which is insecure. Directions: Press the Windows key + R shortcut to open the Run command window. Type in gpedit.msc and press OK. Select Computer Configuration -> Administrative Templates -> Network -> Lanman Workstation and double click Enable insecure guest logons and set it to Enabled. Now attempt to access \\tower Related Errors: Windows cannot access \\tower Windows cannot access \\192.168.1.102 You can't access this shared folder because your organization's security policies block unauthenticated guest access. These policies help protect your PC from unsafe or malicious devices on the network.
 1 point
1 point -
So, another topic on this but there are a few things I want to check with my systems as I think it may just be me So I've followed spaceinvader ones video on getting a vbios for tech power up, modifying it, and using that All went well, passed through the primary gpu from unraid to a vm, did a full windows 10 install and basic setup with the gpu passed through, perfect So I installed the new nvidia drivers for my 750ti, and carried on tinkering. I then decided to reboot the vm so the video drivers could finish installing and it will no longer boot I don't get error 43 like most others. Windows starts to load, showing the loading icon with the uefi splash screen and then the vm pauses This is the vm log from boot up to shutdown 2018-05-02T20:54:30.216302Z qemu-system-x86_64: -device vfio-pci,host=04:00.0,id=hostdev0,bus=pci.4,addr=0x0,romfile=/mnt/cache/VMImages/GPURoms/msi-750ti.rom: Failed to mmap 0000:04:00.0 BAR 3. Performance may be slow 2018-05-02T20:57:26.776428Z qemu-system-x86_64: vfio_region_write(0000:04:00.0:region3+0x1088, 0x7ffe11,8) failed: Device or resource busy KVM internal error. Suberror: 1 emulation failure RAX=ffffab7e37c11000 RBX=ffffab7e37c11000 RCX=ffffab7e37c11000 RDX=0000000000000000 RSI=ffffac04d77445c0 RDI=ffffac04d6055000 RBP=ffffac04d7f12000 RSP=ffff80890cd8d8f8 R8 =0000000000001000 R9 =0101010101010101 R10=fffff80fc1dcc4ac R11=ffff80890cd8d6b0 R12=ffffac04d3a75910 R13=ffffac04d77441e0 R14=0000000000000000 R15=0000000000100000 RIP=fffff80fc204b038 RFL=00010216 [----AP-] CPL=0 II=0 A20=1 SMM=0 HLT=0 ES =002b 0000000000000000 ffffffff 00c0f300 DPL=3 DS [-WA] CS =0010 0000000000000000 00000000 00209b00 DPL=0 CS64 [-RA] SS =0018 0000000000000000 00000000 00409300 DPL=0 DS [-WA] DS =002b 0000000000000000 ffffffff 00c0f300 DPL=3 DS [-WA] FS =0053 0000000000000000 0000fc00 0040f300 DPL=3 DS [-WA] GS =002b ffff9b8042cb9000 ffffffff 00c0f300 DPL=3 DS [-WA] LDT=0000 0000000000000000 ffffffff 00c00000 TR =0040 ffff9b8042cc8000 00000067 00008b00 DPL=0 TSS64-busy GDT= ffff9b8042cc9fb0 00000057 IDT= ffff9b8042cc7000 00000fff CR0=80050033 CR2=ffffd180f654a000 CR3=0000000268559000 CR4=001506f8 DR0=0000000000000000 DR1=0000000000000000 DR2=0000000000000000 DR3=0000000000000000 DR6=00000000ffff0ff0 DR7=0000000000000400 EFER=0000000000000d01 Code=66 66 66 66 0f 1f 84 00 00 00 00 00 66 48 0f 6e c2 0f 16 c0 <0f> 11 01 4c 03 c1 48 83 c1 10 48 83 e1 f0 4c 2b c1 4d 8b c8 49 c1 e9 07 74 2f 0f 29 01 0f 2018-05-02T20:57:45.189655Z qemu-system-x86_64: terminating on signal 15 from pid 12367 (/usr/sbin/libvirtd) Now I did have unraid booted in gui mode but I'm assuming that as it passed through for setup, this isn't the problem. So I'm a little stuck on exactly what would be causing this error as the error says its in use, but this only occurs after installing the nvidia driver. After so many boots I am able to get into the windows recovery menus which all function fine so it seems to pause the second the drivers initialized I'm on unraid 6.5.1 with the vbios passed through the gui. The vm is ovmf with Hyper-V off on Q35-2.11. I can post the full xml if it would help Any ideas as I am a little stumped? Regards, Jamie ----------- ANSWER -------- For easy reading, this was the answer needed. In the event that you get mmap errors on passing through the rom, or you install the nvidia drivers and get errors like the above, try running the following in command line and try again echo 0 > /sys/class/vtconsole/vtcon0/bind echo 0 > /sys/class/vtconsole/vtcon1/bind echo efi-framebuffer.0 > /sys/bus/platform/drivers/efi-framebuffer/unbind I added these to a user script that triggers on first array boot up. I have now successfully remove a gpu i no longer need from my system and am able to reboot unraid and have the vm auto start on the primary gpu1 point
-
This is the story of how I managed to fry all 12 of my HDDs in moment of stupidity. (5 min read) To start, we should talk about my setup. To simplify, I'll post my old signature to cut to the chase. But in short, it was built up over time. Slowly adding drives as needed to satiate my data hording. Much of it was Plex media but I had setup things like a Pi-Hole, Nextcloud, personal VPN (for when I wanted to use public Wi-Fi on my phone in a safer manner). Much of this I think is pretty common in our community so my server wasn't really that out-of-the-ordinary. Config - Pre-incident Unraid Plus MB: ASRock X370 Taichi | CPU: AMD Ryzen 7 1700 | RAM: 32GB DDR4 | Cooler: Cooler Master MasterLiquid Lite 240 | Case: Thermaltake Core X9 | Cache: CORSAIR FORCE Series MP510 (960GB) | Parity: 2 X WD Red 10TB | Array: 3 X WD Red 8TB, 4 X Seagate 8TB, 2 X WD Red 10TB | GPU: XFX Radeon RX 560 | PSU: EVGA SuperNOVA G2, 80+ GOLD 650W (Side note- never went full enterprise/rack mounted due to some confusion around backplanes and concerns over fan noise) So this all started back when I resolved to add more streaming capability to the plex server. I simply wanted to be able to more comfortably encode/direct-stream more concurrent streams. Toying with the Idea of adding a Nvidia GPU rather than my Radeon which doesn't support hardware acceleration. But thanks to some great advice on the unraid discord, I would only add 3 or so streams, not a meaningful improvement for the cost. So was still debating a full motherboard and CPU upgrade. But one thing was clear, I would likely need to upgrade my power supply to support any major changes, GPU, CPU or otherwise. Christmas came and my wife, the incredible Rockstar that she is, blew passed our gift giving budget (for each other) to buy me a Seasonic 1300 gold. (before anyone says it, platinum or titanium would be nice, but the power savings would be nominal and the return on investment was negligible especially at the premium). Needless to say, I was elated. I planned to turn down the server and and carry out the upgrade in one day. If you have ever upgraded a PSU, its not that big a deal usually. For anyone who doesn't know. Power supply units convert my American 120v AC power into DC and deliver multiple voltages to the various components. The connectors on the PSU side of the power cables are often keyed or shaped in a unique manner to ensure that they only fit/plug into the correct voltage ports. Square peg, round hole type of thing. Skilled hardware builders out there, you know what's coming. I checked the preexisting power cables. The motherboard and GPU cables didn't fit. Easy enough, new unit has cables. I swapped those out. I double checked my work, plugged it all in, flipped the switch to turn on and the PSU clicked. A Common sign of a power fault or fault protection. Something was wrong. Perhaps something wasn't fully connected or maybe a new cable was faulty. After all, even Seasonic for all their track record, isn't infallible. But nothing looks wrong and I don't NEED the new PSU today, so I'll reinstall the old unit PSU and have the new PSU exchanged as faulty and try again in a week or two. No big. Old PSU reinstalled, turned on, BIOS shows no SATA disks....started trouble shooting and checking. Pulled HDD and attempted to connect directly to a windows machine to just see if the device is detected.... nothing. None of them. If you didn't connect the dots to what has transpired. Though a square peg doesn't fit into a round hole, many other shapes do fit into a square. Including the wrong voltages being unintentionally sent to my disks, frying the circuitry to all 12 disks including the parity drives, not that 2 of those could repair this level of dumassary. I can only explain the emotion I felt as mourning the loss of a loved one. I mean, you must understand, this was my biggest hobby and pleasure. Learning the endless capabilities of what I could do with Unraid. I did check with well known data recovery services but with the sheer volume of data... the quote was $9,000-21,000 dollars. Though they did say that if no data was recovered, It would cost me zero. A testament to the undoubtable quality of work they would be able to offer. But this isn't enterprise data. the financial risk to me was nil. For more reasons that the obvious, this was not a viable path forward. I resolved to rebuild. The sweet spot for storage size, cost, and physical drive slots for me was going with 7 new 14tb drives. It would yield only 70tb of usable storage (rather than my previous 86tb) but with drives of this size, I was definitely going to need/want 2 parity disks again. Also that would help with the prior issue I had of only being able to fit 12 disks in my case. Now I would have 5 more slots to grow into. All in all the new disks would cost me nearly $1900 (pardon the dramatic title but its nearly 2K and the same goes for my 86tb of usable space out of the 100tb worth of drives). Plus with the advent of things like Unmaniac, I will be able to reduce my storage needs considerably, re-encoding as I regrow my data. Shout out to the great Youtube creators teaching me. Linus tech tips, Spaceinvador One, the OGs. The new ones too, Capt. Chaz, The Mysticle, WhiteWitch Craft. I suppose I even owe a bit of thanks to bite my bits, garage escapades and all. The lesson learned that I must have forgotten since my computer building classes in high school... Swap the power cables when swapping the PSU unless you're more than certain they are the same. So that's where I am today. Preclearing the new 7 disks and soon I'll start installing dockers and seeing what I can get going. I tried to tell the story as best I could but feel free to ask anything you like that I may have left out.




 1 point
1 point -
Sounds like the package I put in UD+ was not the right one. Slackware packages are a bit hard to find. Let me do some research.1 point
-
However..... That post is gone, deleted, no more. It's an ex - post. I'm guessing the search index is still lagging a little.

 1 point
1 point -
No duplicated topics, stars on threads I've posted in, and the search seems to have caught up with some stuff that was posted and not showing as unread before, as I was caught up less than 5 hours ago with nothing showing unread, now I have a day old post showing unread. This is a good thing, because I know for a fact I didn't see that old post even though it wasn't listed this morning as new.
 1 point
1 point -
🤬 Submitting a ticket.1 point
-
Looks like you've made a few steps in the right direction. Now for the bad news, I see an issue right away with that screenshot. The php warning at the top (Warning: parse_ini_file.........) seems to indicate that your flash drive dropped offline again. Either one of two things come to mind: 1. you should use a USB2 port for the flash drive. 2. when you passed through the USB device for blue iris in your windows VM, you passed through an entire USB controller that the flash drive is one, or the drive itself, on accident. If you just need a single USB device, then you should be able to pass through JUST the USB device by itself to the VM. This works well for mice/ keyboards. If you need more control of the USB functionality or want the entire USB controller to appear in the VM, then yes, you pass the controller through - but anything that is connected to that controller will not be available to unraid (i.e. the flash drive). If that is the case, then you need to find a USB controller on it's own IOMMU group AND not attached to the unraid flash drive. Now, to answer your original question - it depends on how you want to utilize that flash drive in your VM(s). You can just store all of your VM disks on that nvme and just point the disks to that. Or you could pass the nvme to windows and let it use it directly. The latter means that ONLY that windows VM will see and be able to use it.1 point
-
Thanks for the help. Looks like I did everything right the first time, except I need to run 6.9 Beta to get the right drivers for the Realtek RTL8125 according to some other other forum inquires. Not sure if this is why they wont talk to each other, but will test it out. Edit: After update to 6.9 all is working. The Realtek RTL8125 didn't seem to like Unraid 6.8. So for those of you who are also trying this SpaceInvaderOne's video "10Gb Home Network (P2) - Peer to Peer" is really all you need to watch. The setup portion starts at 8:10 assuming you already know how to install new hardware. If you get issues with DHCP on boot you can manually set your ip (if you got a monitor hooked up) with ifconfig eth# the.ip.you.want. eth# being the eth card you want to set be it eth0 or eth1. You can check with ethtool eth#.1 point
-
I'm still on the 6.8 series but the 6.9 seems to have what you need. Autostarting the VM is always a risky proposition as you could run into problems as you've seen. My personal preference is that unless it's running some kind of critical task (such as pfsense) then I don't see any reason to autostart. Again, that is just my personal preference. Last I looked at your logs (and in the screenshot), it looked like the audio device is already split into it's own group. I would probably make sure the VM is set to manually start. Then install the nvme (do not adjust the pcie stub yet). With the new hardware how you want it, then adjust the pcie stub on the iommu group and reboot for those to take effect. Then you can configure the VMs to passthrough those stubbed components. Remember, to repeat the process with any new hardware you've added - in my case, I had forgotten what I had done so it took me by surprise. No problem! Sounds like you have a good grasp on how this all works now.1 point
-
Done, please force an update of the container and you can now change the port like I described in the post for the Ferdi-Client Container:1 point
-
No worries, you may not need the ACS overide, unless you need that for other reasons. Glad you got it working, I didnt know about the unsafe_ints as don't need it on my system but will remember in case I need in future, thanks for posting your find/resolution.1 point
-
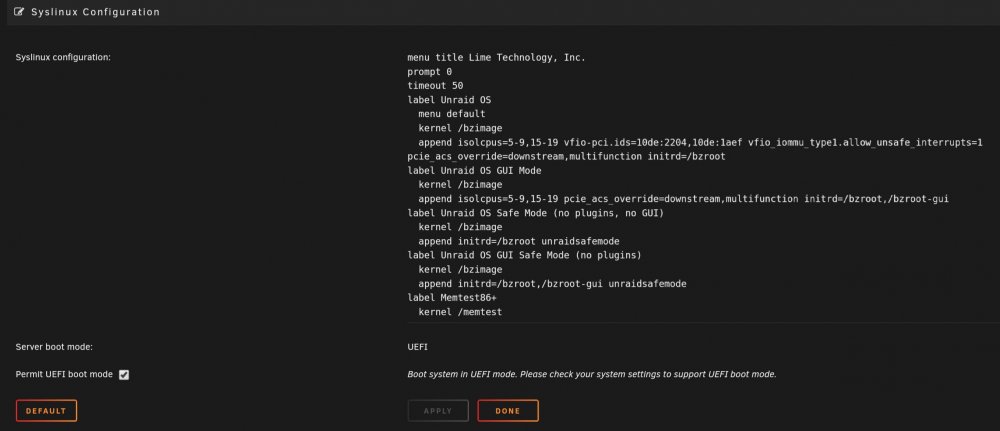
After a bit more searching, the above worked for me. I edited my syslinux.cfg file and added the following line; vfio_iommu_type1.allow_unsafe_interrupts=1 Thank you @SimonF @1812 @runamuk @Maor for your assistance.
 1 point
1 point -
@binhexYou are awesome! Working perfectly now thanks1 point
-
You probably do not want to leave that setting on once you are happy that the problem is solved: It can generate a LOT of log output You may not want that information in posted diagnostics as by its very nature it cannot be anonymized. It is normally recommended that appdata is kept on the cache for performance reasons and to stop array disks spinning up unnecessarily. At the moment appdata is spread across disks 1, 2, 3 and has no files on the cache. If you want appdata on the cache (and have the space on the cache) then you would need to change the Use Cache setting for appdata to "Prefer" to tell mover that the files should be transferred from array to cache.1 point
-
I have pushed a new version that fixes the csrf issue on the plugin's Settings page on my servers and means the Apply button works again - I would like confirmation it has done it for others. The only change I made was to make the names of some variables recently added to the code less generic (and sure to be unique to my code) so it looks like the problem was that I had inadvertently used a name used elsewhere in existing Unraid code where it had a different meaning. I suspect that this is a coding trap other developers could fall into if they use short variable names.1 point
-
Hi @Cassidy and @Dyon, as you suggested I changed the subnet to 192.168.0.0/16 and now it works! Thank you so much for your help, I’m really glad that it is running now! 😄1 point
-
You have the option to flash the H710 you currently have yourself: https://fohdeesha.com/docs/H710-D1/ I was able to follow these instructions and flash the one that came with my R720xd1 point
-
It is with great regret, and some slight deja vu, that I have to report that my "solution" didn't in fact, work. It turns out that the same underlying problem remains - you only get valid data after you unplug/plug in the UPS and run the daemon, or apctest, >once<. After that, it's buggered. My current suspicion is that the UPS becomes out of sync with the port / hid status and considers itself still communicating with it. So any subsequent "Hi, I'm apctest, let's start from scratch and get to know each other" is met by the UPS with, "...the other day, and so Sally then said,...". In other words, something needs to tell the ups "HEY, STOP. Now start like you've never met me before".1 point
-
I used the standard iso. The vm image only worked for me on esxi1 point
-
Have a similar issue, a few suggestions made by others in my bug report that are worth checking out.1 point
-
Yes I do. Just make sure you pass through two physical NICs, Untangle requires this in setup. I couldn't find any help on this either but I'm on my 3rd year of running this in my home. I like it better than pfSense. Untangle is based on Debian. Machine type, and BIOS is important or it won't boot. I stumbled across your post only because I was looking for an answer of why one of my host processor cores is floored at 100% and the guest is not. I have rebooted everthing and tried re-pinning cpus, adding and subtracting cpus. Good, Luck, if you need more help I hope this forum notifies me. Or you can direct message me for my email.
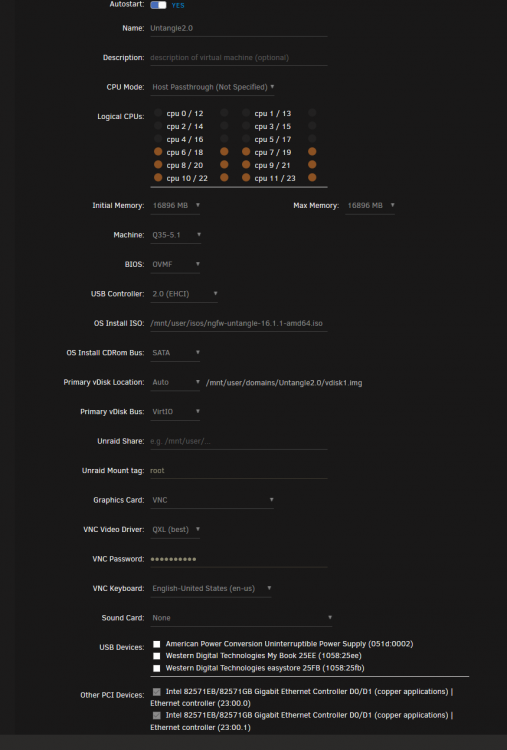
 1 point
1 point -
@SpencerJ @limetech UUD Version 1.6 Sneak Peek! I'm freaking excited! Are you...?
 1 point
1 point -
Also this help me out because I have a super ultrawide monitor; when passing though a lower end dvi dummy. (This can break Windows it if you mess up) https://www.monitortests.com/forum/Thread-Custom-Resolution-Utility-CRU @hundsboog Drink any extra one for me buddy. @Zentachi I just wana know how you snagged that 3070.1 point
-
That was it! Thank you very much for you help!1 point
-
So it looks like we've found the root cause of the problem. By any chance did you start a VM in those diagnostics? What it looks like to me in this snippet is that something took control of the USB controller on 0000:09:00.3, which appears to be where your unraid flash drive is located: Jan 18 19:57:21 PCServer kernel: xhci_hcd 0000:09:00.3: remove, state 1 Jan 18 19:57:21 PCServer kernel: usb usb6: USB disconnect, device number 1 Jan 18 19:57:21 PCServer kernel: usb 6-4: USB disconnect, device number 2 Jan 18 19:57:21 PCServer kernel: sd 1:0:0:0: [sdb] Synchronizing SCSI cache Jan 18 19:57:21 PCServer kernel: sd 1:0:0:0: [sdb] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=0x00 Jan 18 19:57:21 PCServer kernel: xhci_hcd 0000:09:00.3: USB bus 6 deregistered Jan 18 19:57:21 PCServer kernel: xhci_hcd 0000:09:00.3: remove, state 1 Jan 18 19:57:21 PCServer kernel: usb usb5: USB disconnect, device number 1 So what happens, is that when you added the nvme to your system, it interfaces to your PCIe bus, which changed the prior assignments. It inserted itself here: 01:00.0 Non-Volatile memory controller [0108]: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981/PM983 [144d:a808] Subsystem: Samsung Electronics Co Ltd Device [144d:a801] Kernel driver in use: nvme Kernel modules: nvme which caused everything to move down and thus: 09:00.3 USB controller [0c03]: Advanced Micro Devices, Inc. [AMD] Zeppelin USB 3.0 Host controller [1022:145f] Subsystem: ASUSTeK Computer Inc. Device [1043:8747] Kernel driver in use: vfio-pci 0a:00.0 Non-Essential Instrumentation [1300]: Advanced Micro Devices, Inc. [AMD] Zeppelin/Renoir PCIe Dummy Function [1022:1455] Subsystem: ASUSTeK Computer Inc. Device [1043:8747] 0a:00.2 SATA controller [0106]: Advanced Micro Devices, Inc. [AMD] FCH SATA Controller [AHCI mode] [1022:7901] (rev 51) Subsystem: ASUSTeK Computer Inc. FCH SATA Controller [AHCI mode] [1043:8747] Kernel driver in use: ahci Kernel modules: ahci 0a:00.3 Audio device [0403]: Advanced Micro Devices, Inc. [AMD] Family 17h (Models 00h-0fh) HD Audio Controller [1022:1457] Subsystem: ASUSTeK Computer Inc. Device [1043:8797] 09:00.3 now became the USB controller and 0a:00.3 is now your Audio Device (which you were trying to pass to the VM). Basically, when you started the VM, it tried to take control of the device on the PCIe bus at 09:00.3 - which is your USB controller - not the audio device which it previously was. And since the unraid flash is on that USB controller, your system loses connection to it. So to fix this, edit the Windows VM XML to pass through the correct device (audio device) at the correct address (0a:00.3). Repeat this for anything else that is passed through to other VMs. Finally, it would be best to stub those devices first - which prepares them for use in a VM by assigning a "dummy" driver and prevents unraid from using them. I believe there is a VFIO-PCI plugin in CA which would let you select what to stub (issolate for VM use). This would be the easiest route - then assign those respectively to the VM.1 point
-
Thanks Jorge This solved it for me Thanks a lot! //Jan1 point
-
Glad this post helped you fix your issue as well. As for the beer, just the thought is enough for me. Go grab one yourself and lets enjoy them playing with our unraid servers🍻1 point
-
I added a package that should allow mounting of APFS. Update UD+ and see if you can mount an APFS disk. I do not have any way of testing.1 point
-
I can confirm this bug, here's a screenshot on a Big Sur clean install.
 1 point
1 point -
[I just spent 3 hours documenting the step by step work I'd been doing on this for logging in this thread. I have the same UPS and the same errors and the same problems. I don't use unRAID though but I'm sure it's nothing to do with unRaid. I've spent several nights attacking this problem from a low level USB /HID driver problem. Then, 5 minutes ago, I tried something different. And it fixed it. What... the... No guarantees, but here's what I did: # usb_modeswitch -v 0x051d -p 0x0003 --reset-usb (Check lsusb output to find out your vendor and product IDs) That's it. apctest works. apcaccess now reports ALL data.] Background: UPS: APC smc1500-2UC (same as the smc1500 but rack-mount. ) bios: 1.41, modbus enabled via front panel. ubuntu 20.04 apcupsd 3.14.14 apcupsd.conf: UPSCABLE usb UPSTYPE modbus DEVICE Unplug the usb cable then plug it back in. lsusb reports the device with the incremented port: root@sophie:/etc/apcupsd# lsusb Bus 001 Device 022: ID 051d:0003 American Power Conversion UPS dmesg shows: [Sun Jan 17 21:31:31 2021] usb 1-6.4: USB disconnect, device number 21 [Sun Jan 17 21:31:36 2021] usb 1-6.4: new full-speed USB device number 22 using xhci_hcd [Sun Jan 17 21:31:36 2021] usb 1-6.4: New USB device found, idVendor=051d, idProduct=0003, bcdDevice= 0.01 [Sun Jan 17 21:31:36 2021] usb 1-6.4: New USB device strings: Mfr=1, Product=2, SerialNumber=3 [Sun Jan 17 21:31:36 2021] usb 1-6.4: Product: Smart-UPS_1500 FW:UPS 04.1 / ID=1018 [Sun Jan 17 21:31:36 2021] usb 1-6.4: Manufacturer: American Power Conversion [Sun Jan 17 21:31:36 2021] usb 1-6.4: SerialNumber: 3S2012X12122 [Sun Jan 17 21:31:36 2021] hid-generic 0003:051D:0003.001C: hiddev1,hidraw5: USB HID v1.11 Device [American Power Conversion Smart-UPS_1500 FW:UPS 04.1 / ID=1018] on usb-0000:00:14.0-6.4/input0 Making sure that apcupsd is not running, I can run apctest but get the following: root@sophie:/etc/apcupsd# apctest 2021-01-17 21:15:44 apctest 3.14.14 (31 May 2016) debian Checking configuration ... sharenet.type = Network & ShareUPS Disabled cable.type = USB Cable mode.type = MODBUS UPS Driver Setting up the port ... 0.837 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT Doing prep_device() ... 4.091 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT You are using a MODBUS cable type, so I'm entering MODBUS test mode Hello, this is the apcupsd Cable Test program. This part of apctest is for testing MODBUS UPSes. Getting UPS capabilities...SUCCESS Please select the function you want to perform. 1) Test kill UPS power 2) Perform self-test 3) Read last self-test result 4) View/Change battery date 5) View manufacturing date 10) Perform battery calibration 11) Test alarm Q) Quit Note that it glitches during initialisation but gets there in the end. Trying a safe function (Perform self-test) works, as does 'Read last self-test result'. However, the moment I exit apctest, the following appears in dmesg: [Sun Jan 17 21:17:27 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd Ok, fine. apctest resets the device. However, if I try to re-run apctest immediately, the following occurs: root@sophie:/etc/apcupsd# apctest 2021-01-17 21:18:31 apctest 3.14.14 (31 May 2016) debian Checking configuration ... sharenet.type = Network & ShareUPS Disabled cable.type = USB Cable mode.type = MODBUS UPS Driver Setting up the port ... 0.289 apcupsd: ModbusUsbComm.cpp:258 WaitIdle: interrupt_read failed: Success 0.849 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT 1.402 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT 1.602 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=7, rx=21) 1.674 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=7, rx=21) 1.962 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=21, rx=7) 2.033 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=21, rx=7) ... followed by many, many more glitchy lines, and eventually the menu. Exiting apctest and trying to start up the apcupsd daemon causes the following to start appearing in the syslogs: [Sun Jan 17 21:19:28 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:19:55 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:19:57 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:24:08 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:25:09 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd Which I assume is happening as a consequence of something "not quite right". Here's the (wrong) output of apcaccess when things aren't working: root@sophie:/etc/apcupsd# systemctl start apcupsd root@sophie:/etc/apcupsd# apcaccess APC : 001,018,0436 DATE : 2021-01-17 21:19:46 -0800 HOSTNAME : sophie VERSION : 3.14.14 (31 May 2016) debian UPSNAME : sophieUPS CABLE : USB Cable DRIVER : MODBUS UPS Driver UPSMODE : Stand Alone STARTTIME: 2021-01-17 21:19:43 -0800 STATUS : MBATTCHG : 5 Percent MINTIMEL : 3 Minutes MAXTIME : 0 Seconds NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A STATFLAG : 0x05000000 END APC : 2021-01-17 21:19:46 -0800 And even when things are sort of working, here's the output of apcacess that still isn't any good: WIthout going into the 3 day jungle safari that has been my digging into learning the apcupcd code and how usb devices work when plugged into linux, suffice to say that I learned much about things I will never have a use for, but eventually worked out that I wanted to be able to disconnect and reconnect the usb device "at will", in the hopes of using the failed workaround documented by @Gnomuz. This led me through HID space and the frustrations of identifying the device path when something is plugged in. But then I discovered that 'mod_switch' has a reset parameter, and you only need to provide it with the Vendor and product IDs reported by 'lsusb'. Thus, the still-unbelievable simplicity of this: root@sophie:/etc/apcupsd# usb_modeswitch -v 0x051d -p 0x0003 --reset-usb Look for default devices ... Found devices in default mode (1) Access device 022 on bus 001 Get the current device configuration ... Current configuration number is 1 Use interface number 0 with class 3 Warning: no switching method given. See documentation Reset USB device . Device was reset -> Run lsusb to note any changes. Bye! Followed pessimistically by root@sophie:/etc/apcupsd# apctest 2021-01-17 22:38:48 apctest 3.14.14 (31 May 2016) debian Checking configuration ... sharenet.type = Network & ShareUPS Disabled cable.type = USB Cable mode.type = MODBUS UPS Driver Setting up the port ... Doing prep_device() ... You are using a MODBUS cable type, so I'm entering MODBUS test mode Hello, this is the apcupsd Cable Test program. This part of apctest is for testing MODBUS UPSes. Getting UPS capabilities...SUCCESS Please select the function you want to perform. 1) Test kill UPS power 2) Perform self-test 3) Read last self-test result 4) View/Change battery date 5) View manufacturing date 10) Perform battery calibration 11) Test alarm Q) Quit Select function number: q Where I noticed that I didn't get any of the glitch messages at all. I then repeatedly ran apctest over and over expecting errors, and got none. Anywhere. Still not believing anything, I started up apcupsd: root@sophie:/etc/apcupsd# systemctl start apcupsd and of course immediately tried the penultimate test, apcaccess. Which now reported this [you're gonna love this]: root@sophie:/etc/apcupsd# apcaccess APC : 001,038,0879 DATE : 2021-01-17 22:39:52 -0800 HOSTNAME : sophie VERSION : 3.14.14 (31 May 2016) debian UPSNAME : SophieUPS CABLE : USB Cable DRIVER : MODBUS UPS Driver UPSMODE : Stand Alone STARTTIME: 2021-01-17 22:39:45 -0800 STATUS : ONLINE LINEV : 118.4 Volts LOADPCT : 34.9 Percent LOADAPNT : 22.6 Percent BCHARGE : 98.4 Percent TIMELEFT : 28.0 Minutes MBATTCHG : 5 Percent MINTIMEL : 3 Minutes MAXTIME : 0 Seconds OUTPUTV : 118.4 Volts DWAKE : 0 Seconds DSHUTD : 180 Seconds ITEMP : 22.6 C BATTV : 26.0 Volts LINEFREQ : 60.0 Hz OUTCURNT : 2.75 Amps NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A SELFTEST : OK STATFLAG : 0x05000008 MANDATE : 2020-03-17 SERIALNO : 3S2012X12122 BATTDATE : 2020-04-14 NOMOUTV : 120 Volts NOMPOWER : 900 Watts NOMAPNT : 1440 VA FIRMWARE : UPS 04.1 / 00.5 END APC : 2021-01-17 22:40:46 -0800 It's all there, and more. My current best guess is that something isn't being initialized properly, or reset properly, within the apcupsd / apctest code. But running usb_modeswitch resets it properly/fully. That'll do me.
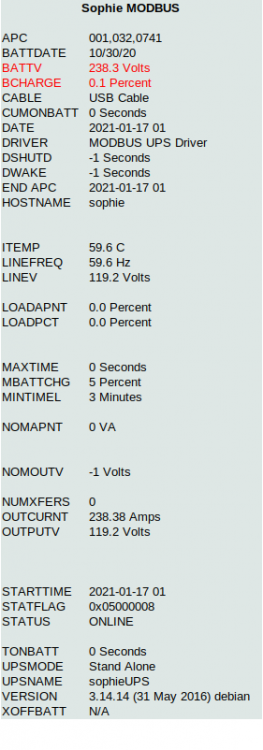 1 point
1 point -
The server you have selected does not support port forwarding. Choose another from the list shown in the log.1 point
-
Seems like a flash drive problem. Put it in your PC and let it checkdisk. While there make a backup. The syslogs from the diagnostics you posted earlier have a lot of messages related to nvidia. Have you tried without nvidia build? You would want to make sure you have a backup of flash if you want to try without that since there isn't any way to reinstall it now that it has been pulled.1 point
-
You can now switch to the new 'feature/audio-reset' of the vendor-reset. Just use @ich777's docker to compile your custom build as you need it. I can boot between Windows 10 20H2, Ubuntu 20.10 and macOS Big Sur 11.1 Afaik @derpuma runs catalina atm and he also reported that everything is working properly. In addition, even the old navi patch could not help him with his powercoler 5700xt. Oh, and he even just fully send it yesterday by force stopping a vm. After starting the vm again he could just go on as if nothing had happend. So this is not just an alternative, but even a possible solution for people having problems with the navi patch.1 point
-
That's actually fairly typical, the video card just renders whatever is in the framebuffer. Until something flushes the buffer or otherwise resets the card, it's just going to show whatever was stuffed into those memory addresses last. If you kill the VM and nothing else takes control of the card, it will just stay at the last state. Normal hardware machines typically take back control of the video card after the OS shuts down.1 point
-
Yes, the signal from the video card that wasn't shutdown1 point
-
Haven't tried this myself but doesn't seem surprising. Force stop is sort of a hard poweroff as far as the VM is concerned but not as far as the hardware is concerned. Does it behave any differently with another release?1 point
-
As always, the typical disclaimer that RAID or Unraid is NOT backup, it's only redundancy, applies. As long as your backup strategy is working ok for you, then you should be fine to go ahead with a double rebuild.1 point
-
Assuming you already have an unRaid server running you have a few options from docker: Nextcloud: i use it only because the android app has a build-in photo backup feature that works very well. But the move to 'Nextcloud Hub' is not my thing. Seafile: very good file server and felt a bit 'faster' then nextcloud in my case but no photo upload in android app. (well, the feature is there but didn't work on my Xiaomi Mi 9T) Pydio: like seafile but i haven't tested it. The new update to 'Pydio Cells' is (again) not my thing. Filebrowser: more basic but works very well. Also less hassle to setup. I like the GUI, clean and simple.1 point
-
Summary OS at time of building: Unraid 6.8.3 CPU: Ryzen 3700 Motherboard: Asus RAM: 32gb DDR 4 Case: generic short depth server Drive Cage(s): None Power Supply: 800w SATA Expansion Card(s): LSI in IT mode, 2 SUB 3.0 cards, 1x Mining riser connection. Cables: spare rear slots taken up with esata connections to link to seperate case containing non-array drives. Fans: 2x40mm, 1x120mm Noctua Parity Drive: 1 14tb WD Data Drives: 5 12tb WD Cache Drive: 1 2tb Total Drive Capacity: Primary Use: NAS and vm Likes: Smaller, quieter, fixed issues with drives. Using the USB to HDMI adapters on the USB hubs saves having to have graphics cards on the Windows 10 vms allowing use with screen or better quality when using RDP. In late October/November my UNRAID server decided to go a little wonky. There were a lot of apparent drive failures and read errors in the array. A lot of data was lost and had to be rebuilt from backups. The culprit was eventually narrowed down to something outside of the array. But rebuilding the server gave me an opportunity to rebuild and change my mind about a few things and alter my server. So in the end my goals were: First change was that I took advantage of Black Friday sale and purchased 5 new 12tb drives and a new 14tb drive to act as parity. These replace the 56tb of 8 tb drives and the 8tb parity drive I had before and allowed for the option that I can upgrade to 14tb in the future when they are less expensive (the 12tb drives were on offer at just over £130 a drive while the 14tb drive was over £250). I upgraded the cache drive to a 2tb SSD while I was at it and kept the three 120gb ssds I had been using as a cache for other things. I kept the motherboard and cpu from the previous build so that is a Ryzen 3700 on an Asus motherboard. The ram remained at 32gb merely because I could not justify upgrading it at this time and I had no other projects that would use it at the moment. The final change was that I decided to swap cases. Until now I had been using a Jou Jye 10 bay case which had proven satisfactory. But with less drives I was able to scale down a bit and settle for a short deptch server case with 8 bays instead. Advantage of this is that as this machine no longer gets used as a daily drvier vm I can put it in the same unit where I keep my media pc away from my desk. I left the 8 port LSI card in the system and that no handles all the parity, data and cache drives for the array. The other drives in the system are connected to the motherboard and the ASMEDIA sata card I had installed. Also since this machine would no longer be serving as my daily pc I removed the 1080ti GPU. I was tempted to fit a passive GPU inside but I didn't want to use up the the space, so instead I took advatange of on of the PCIE x1 slots and an old mining riser to give myself the means to quickly connect up a GPU card without opening the box should I need to troubleshoot and for some reason cannot access it from network. I installed two usb cards on the x1 slots for the purposes of passing through hardware to vms. I currently run 3 Windows vms and two Linux vms. The Windows vms are all Windows 10 each with their own usb controller. All three output their displays to the screen I use with the media PC via a HDMI switch. I don't need to see what they're doing very often but it's quicker than remoting in from another machine. Since I can't output the Linux vms in the same way I just VNC into them when needed, which is even less often. All in all I'm pleased with the results. The Noctua fans keep things cool and quiet, the new drives havemore than enough storage and there is room to expand. The cpu is a little overkill but then I had build a new daily PC with a better cpu so didn't really have a use for it elsewhere. And the change in case means the system takes up a lot less room. I might have cheated a little when dealing with the unassigned drives and remaining ssd drives, but they all reamin available to the server should I require them. I don't thinks its a bad winter project and the best news was that after I checked the culprit behind the whole drive failure I eventually discovered that the drive in question was actually not at fault and the problem was down to sata cable. It just took a while to troubleshoot because the cable in question had nothing to do with the array at the time. Anyway that the end of that project. Next thing will be to improve my offsite backup server.1 point
-
Although I can't speak for my fellow team members, decisions like these usually aren't taken by a single event, in most cases it's just the final drop...not saying it was like that in this case....but don't start "expecting" stuff in return just because a cheap apology was made. Some new developers trying to get into the Unraid community are belittled and left hanging without a proper response, you don't see them getting an apology.... IMO, the backlash was just too big in this case and that's why you get this nice apology, just simple business damage control at its finest. Don't let that be a reason to guilt others into doing things they maybe want/don't want to do. Enjoy the post while it lasts...1 point
-
After looking for almost a month how to install Face Recognition App on Nextcloud. I had found the install instructions but never was able to complete them. Because apt install wasn't working. But i was too stupid and today realised it was alpine underneath. So.. googled what package manager alpine uses and managed to get Face Rec working (ill have some results in some hours!). For anyone wanna install pdlib and try the Face Rec app, here is what i did to install it. First, DO IT ON TESTING DOCKER NOT ON THE PRODUCTION DOCKER! Have some photos on your nextcloud (not on external storages, it won't work, been there) Now the installation. 1 - Go to Dockers, Open console on your test nextcloud docker Insert the following commands one line at a time. Hopefully you won't have any errors. apk add make cmake gcc g++ php7-dev libx11-dev openblas-dev **RESTART DOCKER AFTER THE PREVIOUS LINE, open console on docker again and continue** git clone https://github.com/davisking/dlib.git cd dlib/dlib mkdir build cd build cmake -DBUILD_SHARED_LIBS=ON .. make sudo make install cd / git clone https://github.com/goodspb/pdlib.git cd pdlib phpize PKG_CONFIG_PATH=/usr/local/lib64/pkgconfig ./configure make sudo make install * Now to go appdata folder /php/phplocal.ini and add on the end [pdlib] extension="pdlib.so" 2 - Restart NC Docker once again. 3 - Go to Apps and install/enable Face Recognition App 4 - Go to NC Docker console again and do "occ face:setup -m 1" 5 - Go to Settings > Face Recognition (on the lower menu) 6 - I don't know if its supposed to start automatically, mine was saying Analysis started but didn't seem to process any photo until i open the docker console again and do "occ face:background_job" EDIT* This command justs forces to start, if you want you can let it start automaticly via cron job 7 - Wait for results ( i'm also waiting. so i can't really tell you how it works yet) *For more info for fine tuning check here https://github.com/matiasdelellis/facerecognition/wiki/Usage *This is all info gathered around, so I can't be sure that i haven't messed any other module of NC while installing those packages. DO IT AT YOUR OWN RISK! PS. As you can see i'm just good at googling! Not an expert. Hehe1 point
-
Like most probably know, all disks being valid, if there are errors on multiple disks, e.g. when there's a controller or power problem, Unraid only disables as many disks are there are parity devices, this is a very good thing, but if for example a user with single parity is rebuilding a disabled disk and a write fails to another one it disables that disk, leaving the user in a precarious situation, maybe there's a reason for this, maybe it's an oversight. If it's the latter I would suggest the behavior should be similar to the described above, so that the user is not left with more invalid disks than parity can handle, also would suggest pausing the rebuild if that happens, so the user can decide if he wants to abort to check the problem and retry rebuilding or proceed knowing that there will be corruption on the rebuilt disk.
 1 point
1 point -
Hello, and thank you for the container. I am having issues however, everything seems to be set up properly. Set a username and password, when i open WebUI it comes up asking for a username and password, i enter what was configured and it's telling me invalid. I have purchased a license, it's not prompting me to enter one though1 point
-
Do you run Unraid in GUI or CMD mode? Clearly you must have missed something. try echo 0 > /sys/class/vtconsole/vtcon0/bind echo 0 > /sys/class/vtconsole/vtcon1/bind echo efi-framebuffer.0 > /sys/bus/platform/drivers/efi-framebuffer/unbind https://forums.unraid.net/topic/56049-video-guide-how-to-easily-passthough-a-nvidia-gpu-as-primary-without-dumping-your-own-vbios/?page=2&tab=comments#comment-6440541 point
-
It's is probably complaining because you're trying to only pass through 1 device from the group when allowing unsafe interrupts (which i won't allow,) and conversely not allowing unsafe interrupts when only passing the single devices which isn't working because you are not using the correct device id's from your specific cards. Try this in your syslinux.cfg: append vfio-pci.ids=XXXX:XXXX,YYYY:YYYY vfio_iommu_type1.allow_unsafe_interrupts=1 initrd=/bzroot XXXX:XXXX is your video card id YYYY:YYYY is your sound card id you can obtain your video/sound card id's by going to tools>system devices, and look under pci device for 09:00.0 and 09.00.1 the device id will be at the end of he description in the brackets. replace the X's and Y's above with those numbers, reboot, and try again. If it doesn't work, then post your server diagnostics and xml for the vm.1 point
-
Found the culprit. I had to change a setting allowing less secure access to my account. While logged into your Gmail account use this link. https://www.google.com/settings/security/lesssecureapps I'm going to personally setup a unRAID email account that forwards to my primary account and use it for notifications.1 point




















































