



sonic6
Members
-
Joined
-
Last visited
Everything posted by sonic6
-
Hi, it there a place to report a "bug" with wireguard? if i add a IP to "Peer allowed IPs", it won't be shown in the downloadable config:
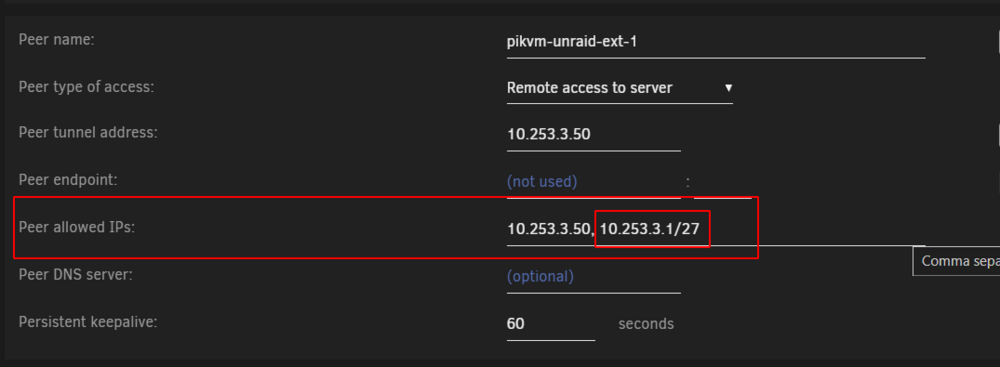
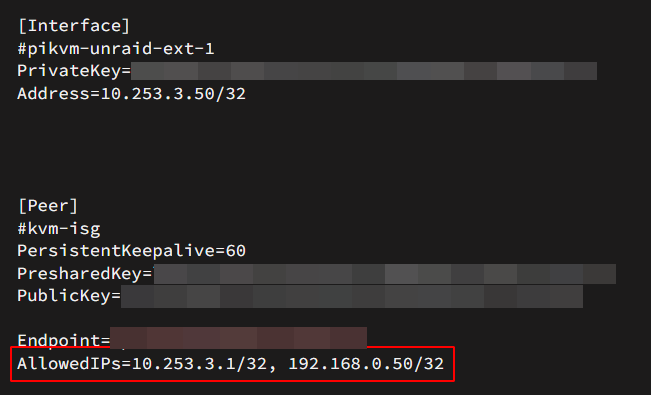
-
Moin @MarkSt ich bin leider nicht der Entwickler, sondern habe nur das Template erzeugt. Aber so wie ich das sehe, kann das nicht richtig funktionieren. Du nutzt den Container mit einer eigenen IP (br0), dadurch werden die Ports, welche im Template angegeben werden obsolete. Der Effekt in der Praxis ist, dass dein Backend auf Port auf 80 läuft, jedoch im Template von Frontend Port 7301 angegeben ist. Ich erinnere mich, dass ich selbst Probleme hatte, daher steht in der Container Beschreibung folgendes: Bitte ersteinmal an diese Vorgabe halten. Und auch bitte einmal Cookies und Cache vom Browser leeren (STRG+F5)
-
damn, totaly missed that plugin in my mind but good that you are also the dev of this plugin ahh okay. it is gone. thank you!
-
Is it possible, that your plugin spammed my syslog with something like this: Apr 15 07:01:16 Unraid-1 lldpd[9825]: unable to bind to raw socket for interface veth052f133: No such device Apr 15 07:01:16 Unraid-1 lldpd[9827]: unable to initialize veth052f133 Apr 15 07:01:16 Unraid-1 lldpd[9825]: unable to bind to raw socket for interface vetha376979: No such device Apr 15 07:01:16 Unraid-1 lldpd[9827]: unable to initialize vetha376979 even when the Start DVM service is stopped? i got after i restarted the Docker Service (not the whole server). Also this, after i unistalled the plugin: Apr 15 07:20:44 Unraid-1 nginx: 2024/04/15 07:20:44 [error] 16158#16158: *1736042 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.0.6, server: , request: "GET /plugins/dwdvm/include/dwdvm_report.php?mode=footer HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.0.50:50080", referrer: "http://192.168.0.50:50080/Plugins" Apr 15 07:21:15 Unraid-1 nginx: 2024/04/15 07:21:15 [error] 16158#16158: *1736043 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.0.6, server: , request: "GET /plugins/dwdvm/include/dwdvm_report.php?mode=footer HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.0.50:50080", referrer: "http://192.168.0.50:50080/Plugins" Apr 15 07:22:03 Unraid-1 nginx: 2024/04/15 07:22:03 [error] 16158#16158: *1736043 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.0.6, server: , request: "GET /plugins/dwdvm/include/dwdvm_report.php?mode=footer HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.0.50:50080", referrer: "http://192.168.0.50:50080/Plugins" Apr 15 07:23:03 Unraid-1 nginx: 2024/04/15 07:23:03 [error] 16158#16158: *1736720 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.0.6, server: , request: "GET /plugins/dwdvm/include/dwdvm_report.php?mode=footer HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.0.50:50080", referrer: "http://192.168.0.50:50080/Plugins" Apr 15 07:24:03 Unraid-1 nginx: 2024/04/15 07:24:03 [error] 16158#16158: *1736998 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.0.6, server: , request: "GET /plugins/dwdvm/include/dwdvm_report.php?mode=footer HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.0.50:50080", referrer: "http://192.168.0.50:50080/Plugins" Apr 15 07:24:33 Unraid-1 nginx: 2024/04/15 07:24:33 [error] 16158#16158: *1736998 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.0.6, server: , request: "GET /plugins/dwdvm/include/dwdvm_report.php?mode=footer HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.0.50:50080", referrer: "http://192.168.0.50:50080/Plugins" Diagnostic ist attached unraid-1-diagnostics-20240415-0732.zip
-
looks good for 6.12.10
-
i don't know, why you have connection issues, but IP's will only be showen when you have ports in your template (which are irrelevant, when using br0/eth0).

-
you have to edit the config file on your flash drive: boot/config/plugins/prometheus_fritzbox_exporter/settings.cfg fritz_username=FITZBOX-USER fritz_password=FRITZBOX-USER-PW fritz_additional= -gateway-url="http://YOUR-FRITZBOX-IP:49000" -gateway-luaurl="http://YOUR-FRITZBOX-IP" exporter_address=0.0.0.0:9042 exporter_metrics_file=metrics.json exporter_luametrics_file=metrics-lua.json than it will looks like this: 192.168.0.1 is the IP of my fritzbox.
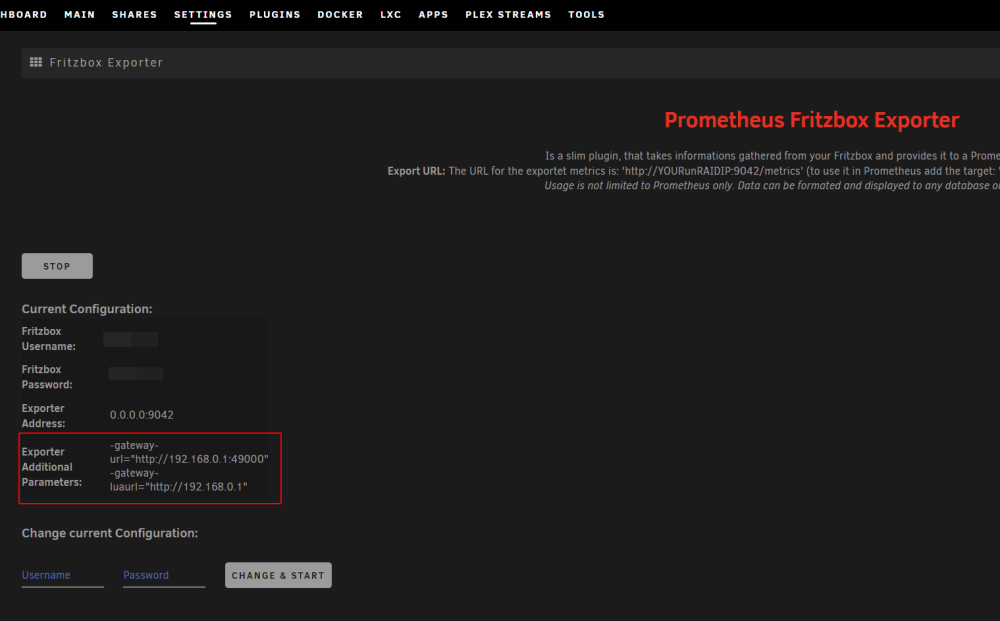
-
kann dir bei deinem Problem leider nicht helfen, aber dir den Tipp geben, dass du im falschen Bereich gepostet hast und du deswegen kaum Hilfe erwarten kannst.
-
Was wäre denn das SVG Problem, wenn ich nochmal fragen darf?
-
@FlamongOle i see many reports about you last update... but no one uploaded a Diagnostic file. Here is one: unraid-1-diagnostics-20240306-0638.zip
-
Hier vielleicht mal die detaillierte Anzeige nutzen, wie im initialen Post. Interessanter wäre mal den Gesamtverbrauch über einen Tag (oder Woche/Monat) beide Sensoren nebeneinander zu legen. Daran könnte man dann erkennen, ob die Sensoren zumindest "Intern" ihre Verbräuche genau/ungenau erfassen und weiter geben, so wie @MPC561 schon erwähnte. Den Momentanverbrauch "genau" dazustellen, das auch noch per Funk über was-weiß-ich über wieviele Dienste/Container/Bridge/Backende/Webend, ist halt kaum möglich. Die Gründe dafür wurden auch von @MPC561 eingangs technisch erläutert.
-
looks like it worked with Fritzbox 7950 AX ------------------------------------------------------------------------------- LLDP neighbors: ------------------------------------------------------------------------------- Interface: eth0, via: LLDP, RID: 1, Time: 0 day, 00:01:09 Chassis: ChassisID: mac xxxxxxxxxxxxx SysName: fritzbux SysDescr: AVM FRITZ!Box 7590 AX 259.07.80 MgmtIP: 192.168.0.1 MgmtIface: 7 Capability: Bridge, on Capability: Router, on Capability: Wlan, on Port: PortID: mac xxxxxxxxxxxx PortDescr: LAN:1 TTL: 60 -------------------------------------------------------------------------------
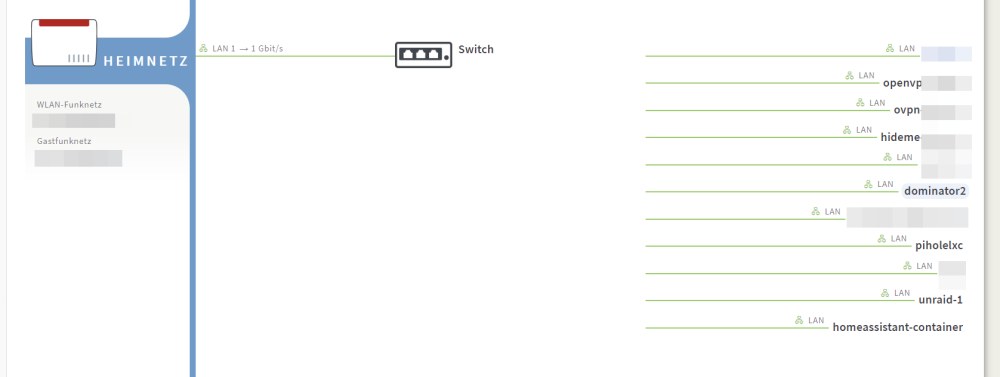
-
Leude... lest doch einfach die Patchnotes.
-
an dieser Stelle danke ich dir ersteinmal für deine Zeit und dein Know-How. Dies und meine oben aufgeführten Punkte werde ich die nächsten Tage/Woche noch gegenprüfen, habe da aber wenig Hoffnung. Der Aufwand steht dann nicht mehr im Verhältnis zum Ergebnis, dann werde ich halt einen USB Tuner nutzen. Zerstören möchte ich den Adapter auch nicht, da geben ich ihn lieber einem Freund, bei dem er funktioniert.
-
After updating 6.12.8 i did an container update to paperless-ngx. the container won't create because of: docker: invalid spec: :/usr/src/paperless/export:rw: empty section between colons. this wasn't a problem on 6.12.6. here a complete log: docker run -d --name='paperless-ngx' --net='bridge' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Unraid-1" -e HOST_CONTAINERNAME="paperless-ngx" -e 'PAPERLESS_REDIS'='redis://192.168.0.50:6379' -e 'PAPERLESS_OCR_LANGUAGE'='deu+eng' -e 'PAPERLESS_OCR_LANGUAGES'='' -e 'PAPERLESS_FILENAME_FORMAT'='{created_year}/{correspondent}/{created_year}{created_month}{created_day}-{correspondent}-{document_type}' -e 'PAPERLESS_TIME_ZONE'='Europe/Berlin' -e 'PAPERLESS_TIKA_ENABLED'='1' -e 'PAPERLESS_TIKA_ENDPOINT'='http://192.168.0.50:9998' -e 'PAPERLESS_TIKA_GOTENBERG_ENDPOINT'='http://192.168.0.50:3000' -e 'PAPERLESS_IGNORE_DATES'='' -e 'PAPERLESS_CONSUMER_POLLING'='0' -e 'PAPERLESS_SECRET_KEY'='lülülülülülülül' -e 'USERMAP_UID'='99' -e 'USERMAP_GID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8000]' -l net.unraid.docker.icon='https://raw.githubusercontent.com/selfhosters/unRAID-CA-templates/master/templates/img/paperless.png' -p '8000:8000/tcp' -v '/mnt/cache0_vm/appdata/paperless-ngx/data':'/usr/src/paperless/data':'rw' -v '/mnt/user/Dokumente/':'/usr/src/paperless/media':'rw' -v '/mnt/user/temp/paperpess_import/':'/usr/src/paperless/consume':'rw' -v '':'/usr/src/paperless/export':'rw' --hostname paperless-ngx --no-healthcheck 'ghcr.io/paperless-ngx/paperless-ngx' docker: invalid spec: :/usr/src/paperless/export:rw: empty section between colons. See 'docker run --help'. The command failed. Removing the "Export" Path, helped temporarily. Diagnostic is attaced. Thanks unraid-1-diagnostics-20240216-1729.zip
-
habe ich heute mal getestet, leider ohne erfolg. habe leider keinen gefunden. VIELLEICHT kann ich irgendwo sowas auf der arbeit mopsen. (zum testen natürlich.) Im BIOS habe ich nur eine Option die "WAN" heißt, welche damit zusammen hänge könnte. Damit aktiviere ich WIFI/BT, habs an und aus gemacht, beides keinen unterschied. auch hier muss ich einmal schauen wo ich etwas "aktuelles" finde um das gegen zu prüfen.
-
Zumindest bei SWAG geht das auch per eth0 oder cloudflared tunnel. aber das ist ein anderes thema.
-
Da habe ich Durchgang. Zu den 3.3V vom Floppy Stecker habe ich tatsächlich keinen Durchgang zum PCIe. Vom 3.3V Floppy zum M.2 habe ich KEINEN Durchgang. Vom PCIe-B10 habe ich Durchgang zum M.2-TP6. Hier habe ich Durchgang von M.2-P53 auf Ground und TP7 und an PCIe-B12 Ich habe also den Fall 2) und 4), kann das sein? Okay, das war zu einfach, da hätte ich selbst drauf kommen können, danke für die Erklärung! Die Angabe von der Herstellerhomepage war für mich nicht Eindeutig auf PCIe zurück zu führen.
-
Das werde ich wohl morgen erst machen können, da derzeitig Zugriffe auf den Server gibt. Sollte ich ASPM tatsächlich deaktivieren müssen, werde ich wohl auf einen USB Tuner zurückgreifen, da die Ersparnisse von ASPM schon relevant sind. Ich werde es aber vorher sicherlich testen. Zufällig komme ich aus dem Elektrogewerbe Gut, zum Messen werde ich den Adapter morgen mit auf die Arbeit nehmen, da werde ich das alles Prüfen. ich habe nochmal neue gemacht: Ich hoffe diese sind besser und danke nochmal.


-
@Lemon-Better (nach dem @ + namen musst du einmal auf das dropdown klicken) und @DataCollector erst einmal DANKE vorab für den austausch und die hilfe. Das wäre tatsächlich etwas das ich erst später machen würde, da das WiFi Modul schon in "den weiten meines Keller" verschwunden ist. (bitte keine weiteren rückfragen) Server booted, es wird nur nichts erkannt. Adapter ist ein ADT R5S Ver2.4 Darf ich fragen, wofür "GH" steht? Jau, Adapter ist dabei, hätte sogar einen für Molex über. Die Thematik mit der maximalbelastung über SATA kenne ich, aber echt danke, dass du daran denkst und mich nochmals drauf hinweist. Letztendlich soll da n PCIe DVB-S doppel Tuner dran, das sollte von der Leistung her passen.



-
moin zusammen, danke erstmal an @Lemon-Better für deine arbeit, vielleicht kannst du mir ein wenig unter die arme greifen. ich habe ein AsRock Board, genauer gesagt das H470M-ITX/ac. Da meine m.2 und pcie Slots komplett belegt sind, wollte ich gerne per m.2 key-e um einen PCIe Slot erweitern. Hierzu habe ich mir folgenden Adapter bestellt: ADT-Link M.2 WiFi A.E Key A+E auf PCI-e 4X x4 Riser Extender Adapter Karte Ribbon Gen3.0 Kabel AE Key A E für PCIE 3.0 x1 x4 x16 M2 Karte R52SR 20cm Natürlich funktioniert der Spaß bei meinem Glück nicht out of the Box. Ich habe es auch mit und ohne aktiven CSM probiert, leider ohne Erfolg- Ich muss mir hier nochmal genauer meinen Adapter anschauen und gucken, ob es sich bei diesem genauso verhält. Könntest du nochmal erläutern wo du was miteinander verbunden hast. Hab ein wenig "Angst" mir was zu zerschießen. Vielen Dank schommal.
-
Mal ne super dämliche Frage in der Raum geworfen, da ich aus der SWAG Ecke komme: Nutzt ihr per NPM das nginx Streaming Modul oder wie soll Teamspeak über nen RP laufen? Normalerweise ist doch NPM (oder auch SWAG) nur für http/s Traffic, alles andere läuft über nen gesonderten Port. Außer man nutzt natürlich das nginx steaming?
-
Ich bin auf dein Feedback gespannt.
-
Für eine 1TB Platte würde ich folgenden Werte verwenden:

-
Still the same Problem, also with other USB Devices: Feb 9 14:13:16 Unraid-1 kernel: usb 1-3: new full-speed USB device number 16 using xhci_hcd Feb 9 14:13:16 Unraid-1 kernel: input: PiKVM PiKVM HID as /devices/pci0000:00/0000:00:14.0/usb1/1-3/1-3:1.0/0003:1209:EDA2.0011/input/input20 Feb 9 14:13:16 Unraid-1 kernel: hid-generic 0003:1209:EDA2.0011: input,hidraw0: USB HID v1.11 Keyboard [PiKVM PiKVM HID] on usb-0000:00:14.0-3/input0 Feb 9 14:13:16 Unraid-1 kernel: input: PiKVM PiKVM HID as /devices/pci0000:00/0000:00:14.0/usb1/1-3/1-3:1.1/0003:1209:EDA2.0012/input/input21 Feb 9 14:13:16 Unraid-1 kernel: hid-generic 0003:1209:EDA2.0012: input,hidraw2: USB HID v1.11 Mouse [PiKVM PiKVM HID] on usb-0000:00:14.0-3/input1 Feb 9 14:13:16 Unraid-1 elogind-daemon[1326]: Watching system buttons on /dev/input/event6 (PiKVM PiKVM HID) Feb 9 14:13:16 Unraid-1 kernel: usb 1-3: USB disconnect, device number 16 Feb 9 14:13:16 Unraid-1 acpid: input device has been disconnected, fd 12 unraid-1-diagnostics-20240209-1420.zip












