Leaderboard


Popular Content
Showing content with the highest reputation on 02/24/20 in all areas
-
I'm running a new Ryzen 3000 series system on Unraid 6.8.0 and can not query the systems temperature sensors using the Dynamix - System Temp plugin. After a little digging, I found users Skitals and Leoyzen made kernels forking 6.8.0-RC5 to support this features (as well as others). I'd like to see the Linux kernel patches for the k10temp and nct6775 make it into the next Unraid RC build to support users of this platform and CPU architecture. Note, my Realtek R8125 on my ASUS ROG Strix x570-E seems to be working with the out-of-tree drivers and I don't seem to have the VFIO bug that is referenced in the 2nd thread on my 6.8.0-stable system. References: Thank You! -JesterEE2 points
-
Would love to spin up virtual raspberry pi's for development. Should be relatively straightforward to add with qemu already having ARM support available. Would love to be able to use the webgui to create virtual pis that mount and boot from standard pi image files.1 point
-
I feel like the following things would greatly enhance the docker tab in the WebUI. Container Groups (for commands): I know personally that it would be hugely beneficial to be able to select a group of containers and run a command (push the button) on just that group of containers. For anyone who has more than 10 containers, the Start/Stop/Restart/Pause/Resume/Update buttons are pretty much useless because that's essentially the same thing as disabling docker all together. The same thing goes for checking selecting/unselecting Autostart. Right now we don't even have the option to change that for more than one at a time. Having to click on say 30 of 50 different containers individually to manage them so that certain other containers get left alone is a huge burden. Container Groups (for organization): To piggy back off the previous request; those of us who have a lot of containers, it begins to just look like a wall of text after a certain point. This really makes it hard to manage what is where. So being able to visually group containers together with separators would be great. And even better would be the ability select those groups (with a checkbox) and then run commands on them.1 point
-
If you read the GUI built-in help you will see that setting only applies to drives that are 2TB or less in size and all drives larger than that are partitioned using GPT.1 point
-
Yes. Unraid will partition automatically, and apply whichever format type (XFS or BTRFS) that you have set for that cache slot. XFS is only available if the number of cache slots available is set to exactly 1.1 point
-
And we are all very grateful for this, thank you.1 point
-
Maybe I'm just being simplistic but I would just rather be able to go over the 30 drive limit (unlimited hahaha). I love unraid and the ease of use and the fact that it lets you use random hard drives but the 30 drive limit is a bit of a bummer.1 point
-
https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=7816011 point
-
Probably could do either if all the files are on the cache drive, but using the /mnt/user variant will also backup any files belonging to that share that might for some reason be on an array drive.1 point
-
Hi ! I would recommend this read : https://khronokernel-3.gitbook.io/catalina-gpu-buyers-guide/1 point
-
You never need to do this. In the case of a failed install, just go to Apps, Previous apps and it'll be there1 point
-
No probs, see pic. attached.
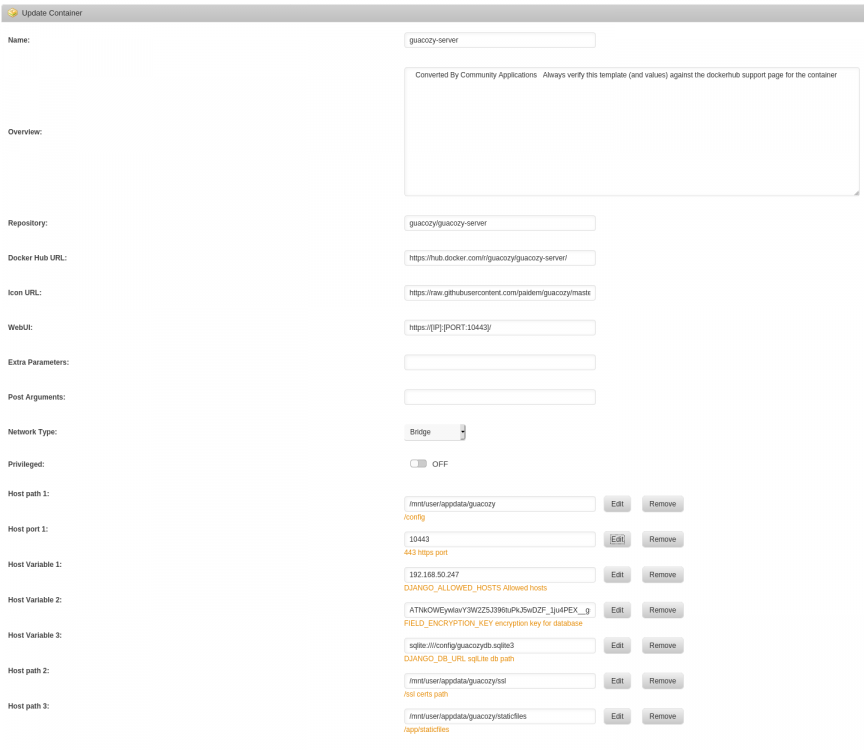 1 point
1 point -
ive seen this myself first hand!, so in my case i precleared two identical drives, both in their enclosures (WD My Books), one of the drives i disconnected fairly swiftly after preclear and it was fine, no additional clearing required., the other i left for 24 hours before i had chance to disconnect it, its this second drive that then required clearing again by unraid. i believe what is happening is something (dunno what) is writing to the newly cleared drive, and as soon as ANYTHING (be it 1 bit or 1TB of data) is written to the disk its instantly invalidated from being cleared, thus requiring clearing again by unraid. so what i could try is to issue a command to put the drive into a read only state at the end of the preclear (needs testing but it should be back to normal operation on disconnect and reconnect), this should then hopefully prevent the drive from being invalidated by writes. fyi - util is blockdev, link to man page:- https://linux.die.net/man/8/blockdev1 point
-
Stop the array, click on disk8 and change filesystem from auto to xfs, that should do it, if it doesn't report back and I'll post instructions to run it from the CLI.1 point
-
Yep, but if there are vdisks they should be copied with the --sparse=always flag to remain sparse, especially when copying back to cache.1 point
-
You can use the cache disk slot to format to XFS as long as you set the cache slots to display only 1 slot. That way it doesn't disturb the parity array and still sets up the drive correctly. If you currently are using a cache drive just disable the VM and Docker services in settings while you do the unassign current cache, assign temp drive, format, unassign, reassign all current cache drives.1 point
-
Since the filesystem has gone read-only those errors are normal, just make sure everything important was copied to the array, the pool will need to be re-formatted.1 point
-
GPT support was added on late 4.x releases, all v5 and v6 support it.1 point
-
These look like a connection/power issue, see if those disks share a power cable/splitter, or if possible try with a different PSU.1 point
-
It won't, you'll need to run a filesystem check, remove -n or nothing will be done and if it asks for -L use it.1 point
-
Yes, midnight commander won't keep them sparse, you can use cp: cp --sparse=always /path/to/source/vdisk.img /path/to/dest/vdisk.img1 point
-
the only saving grace for smaller drives is the quicker rebuild times.1 point
-
Seems like you probably already know this, but just in case someone else sees this thread. The usual cause of filling docker image is an application configured to write to a path that isn't mapped. Using a different upper/lower case from the mappings, or using a relative path (doesn't begin with /) are often the culprit.1 point
-
HDD failure is a probabilistic. The more drives you have, the more likely you will soon have a failed drive. And then, based on Backblaze stats, older small capacity drives are less reliable than newer large capacity ones. So if I were you, I would rather spend some money on 4x16TB and save myself for meaningful things instead having to constantly worry at the back of my head that one of the 24x2TB is going to fail imminently. Linus gets paid to have those storinators and he has people working for him who know how to deal with failed drives (poor Anthony).1 point
-
For the "play" part, if you are after gaming in a VM, Intel is still king (caveat: ONLY with Intel single-die chips). The CCX-CCD design of AMD Ryzen adds latency that (a) requires a lot of tweaks to minimise and (b) even with all the tweaks are still not as low as Intel Intel single-core clock is still the highest on the market and most games aren't optimised that well for many-core. For the "nice" part, I don't think there's any show-stopper kind of stability issues any more as the necessary tweaks are known. There are just bits and bobs that you might need to pay extra care for e.g. BIOS version for Ryzen (some versions are known to break things) and pin issues with Threadripper (simply because of the ridiculous number of pins required and the delicate mounting mechanism). You can search the forum for people's post about 3950X config to have an idea of how things are playing out. Most of the issues I have seen are GPU pass through but they are not CPU specific. I don't think you can generalise your issue as being 2950X specific. Something isn't right with your hardware. If I have to guess from the kernel panics, you might want to check your motherboard pins and CPU mounting. It has been known to cause weird inexplicable problems such as kernel panics. Btw, 3x Titan X on a 2950X is highly inefficient for the simple fact that the 2950X only has 2 dies. At least 1 of the 3 Titan will have to compromise (most likely 2 of the 3 since 2 of them need to share the same die).1 point
-
Checking the original diags to refresh my memory on what happened here I just noticed that disk8 failed to mount even before there were read errors during the rebuild: Feb 5 22:47:43 TC-NAS-01 emhttpd: shcmd (184): mount -t xfs -o noatime,nodiratime /dev/md8 /mnt/disk8 Feb 5 22:47:43 TC-NAS-01 kernel: XFS (md8): Mounting V5 Filesystem Feb 5 22:47:43 TC-NAS-01 kernel: XFS (md8): Log inconsistent (didn't find previous header) Feb 5 22:47:43 TC-NAS-01 kernel: XFS (md8): failed to find log head Feb 5 22:47:43 TC-NAS-01 kernel: XFS (md8): log mount/recovery failed: error -5 Feb 5 22:47:43 TC-NAS-01 kernel: XFS (md8): log mount failed Feb 5 22:47:43 TC-NAS-01 root: mount: /mnt/disk8: can't read superblock on /dev/md8. Feb 5 22:47:43 TC-NAS-01 emhttpd: shcmd (184): exit status: 32 Feb 5 22:47:43 TC-NAS-01 emhttpd: /mnt/disk8 mount error: No file system Feb 5 22:47:43 TC-NAS-01 emhttpd: shcmd (185): umount /mnt/disk8 Feb 5 22:47:43 TC-NAS-01 root: umount: /mnt/disk8: not mounted. This suggests there were already filesystem issues, so you can still continue but success depends on how bad that corruption was, but it might be easily fixable by xfs_repair, everything else looks fine for now, the procedure is: -Tools -> New Config -> Retain current configuration: All -> Apply -Check all assignments and assign any missing disk(s) if needed. -Important - After checking the assignments leave the browser on that page, the "Main" page. -Open an SSH session/use the console and type (don't copy/paste directly from the forum, as sometimes it can insert extra characters): mdcmd set invalidslot 8 29 -Back on the GUI and without refreshing the page, just start the array, do not check the "parity is already valid" box (GUI will still show that data on parity disk(s) will be overwritten, this is normal as it doesn't account for the invalid slot command, but they won't be as long as the procedure was correctly done), disk8 will start rebuilding, disk should mount immediately (it likely won't mount in this case) but if it's unmountable don't format, wait for the rebuild to finish and then run a filesystem check1 point
-
I also have the same issue. I'm not sure if this is a problem with NPM or not...1 point
-
6.8.2 is current But definitely read this thread Although you won't be able to install Fix Common Problems as it's not compatible < 6.7 anymore1 point
-
Start with this post and read the the rest of the thread: https://forums.unraid.net/topic/69018-sata-controller-replacement-question-and-advice/?tab=comments#comment-6300971 point
-
This may be elementary but did you try to remove the new hardware and revert to the prior "working" configuration?1 point
-
when i used the external official onlyoffice doc server docker with lsio nextcloud i added those 2 variables from the readme
 1 point
1 point -
An installer that works with USB 3 and more USB thumb drives.1 point
-
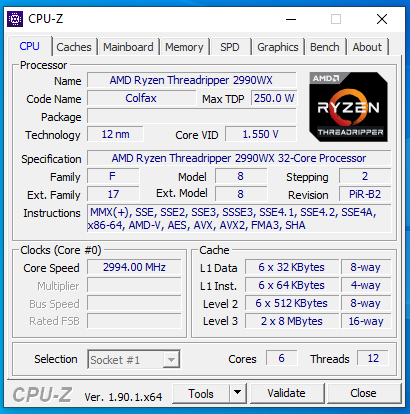
@bonienl The VM GUI editor is hard coded to set the thread count to 1 if it detects an AMD processor in libvirt.php // detect if the processor is AMD, and if so, force single threaded $strCPUInfo = file_get_contents('/proc/cpuinfo'); if (strpos($strCPUInfo, 'AuthenticAMD') !== false) { $intCPUThreadsPerCore = 1; } This was due to AMD reporting no support for hyperthreadding in a VM. With UNRAID 6.8.1 RC1, hyperthreadding is supported with CPU passthrough as is (and CPU cache) if the CPU feature topoext is enabled. Previously, the CPU had to be forced to report as an EPYC to get it to support hyperthreadding. <cpu mode='host-passthrough' check='none'> <topology sockets='1' cores='6' threads='2'/> <cache mode='passthrough'/> <feature policy='require' name='topoext'/> </cpu> Microsoft's CoreInfo returns Coreinfo v3.31 - Dump information on system CPU and memory topology Copyright (C) 2008-2014 Mark Russinovich Sysinternals - www.sysinternals.com Logical to Physical Processor Map: **---------- Physical Processor 0 (Hyperthreaded) --**-------- Physical Processor 1 (Hyperthreaded) ----**------ Physical Processor 2 (Hyperthreaded) ------**---- Physical Processor 3 (Hyperthreaded) --------**-- Physical Processor 4 (Hyperthreaded) ----------** Physical Processor 5 (Hyperthreaded) Note that changes to the CPU layout may not be detected in the VM until the VM is rebooted from inside the VM itself (for example: Start > Power > Restart) Prior to 6.8.1 RC1, I could not get CPU-Z to run, it would always hang at the 10%/Processors on load. It still takes a bit but does return now.
 1 point
1 point -
Disk looks healthy, so the problem was most likely cause by the controller, SAS2LP are not recommend for a long time, you should replace them with LSI controllers, then we can try try re-enabling disk4 to rebuild disk8 again, or if you want we can try again with current controllers.1 point
-
Mainstreaming the nvidia build Snapshots1 point
-
Yeah I'm excited for the improved monitoring for temps and stuff.1 point
-
there is not a single cheap drive out there I can back all my critical data up with I currently use three unraid servers for various tasks the shear amount of data i want to back up is over 100TB the absolutely must not lose is approximately half of that (bussines data for home based business) the other half is stuff i could easily download again if I needed too. Also not all data would fry since my main server is also connected to an external Disk Shelf where i plan to add my array pool to about 24 then start stacking my cache pool in a decent raid mode that is supported by BTFRS and unRAID. I have a total of 36 Bays available (12 in the server and 24 in the disk shelf) for the one server the servers are using server grade cases and PSU's not some cheap off the shelf PSU and power is managed by the servers backplane so i would probably lose the backplane before the drives I am totally aware i need an off site solution and very very slowly getting all my data to G Suite but the 7MB/sec speed capp to not go over the 750GB/day upload is going to take a while to get the 76TB in one server and 18 in the other and 7 or so in the last server all uploaded1 point
-
You can use one cable for single link and two cables for dual link. On the main server you need one SAS HBA with external ports (or with internal ports and one SFF-8087 to SFF-8088 adapter). On the DAS side (besides the normal hardware): -SFF-8087 to SFF-8088 adapter -SAS expander, I use the Intel RES2SV240 -SFF-8088 to SFF-8088 cable to connect DAS to server, because of the expander it can be up to 10 meters long even with SATA disks, but use one as small as possible (expander to SATA disks cables need to be 1 meter max ).1 point
-
The corruption occurred as a result of failing a read-ahead I/O operation with "BLK_STS_IOERR" status. In the Linux block layer each READ or WRITE can have various modifier bits set. In the case of a read-ahead you get READ|REQ_RAHEAD which tells I/O driver this is a read-ahead. In this case, if there are insufficient resources at the time this request is received, the driver is permitted to terminate the operation with BLK_STS_IOERR status. Here is an example in Linux md/raid5 driver. In case of Unraid it can definitely happen under heavy load that a read-ahead comes along and there are no 'stripe buffers' immediately available. In this case, instead of making calling process wait, it terminated the I/O. This has worked this way for years. When this problem first happened there were conflicting reports of the config in which it happened. My first thought was an issue in user share file system. Eventually ruled that out and next thought was cache vs. array. Some reports seemed to indicate it happened with all databases on cache - but I think those reports were mistaken for various reasons. Ultimately decided issue had to be with md/unraid driver. Our big problem was that we could not reproduce the issue but others seemed to be able to reproduce with ease. Honestly, thinking failing read-aheads could be the issue was a "hunch" - it was either that or some logic in scheduler that merged I/O's incorrectly (there were kernel bugs related to this with some pretty extensive patches and I thought maybe developer missed a corner case - this is why I added config setting for which scheduler to use). This resulted in release with those 'md_restrict' flags to determine if one of those was the culprit, and what-do-you-know, not failing read-aheads makes the issue go away. What I suspect is that this is a bug in SQLite - I think SQLite is using direct-I/O (bypassing page cache) and issuing it's own read-aheads and their logic to handle failing read-ahead is broken. But I did not follow that rabbit hole - too many other problems to work on1 point
-
LAN hosts or docker containers/VMs with their own IP address, need a return path back to the WireGuard VPN tunnel which exists on the Unraid server to reach any remote destination. This is achieved by adding the tunnel endpoint subnet to the gateway (router) which provides the regular access to remote destinations. By default Unraid uses the 10.253.x.x/16 subnet for tunnel endpoint assignments. This subnet needs to be added to the router and points to the LAN (eth0) address of the Unraid server. Below is an example of static routes added to a Ubiquiti router (other brands should offer something similar). It is also needed to disable the "Local Server uses NAT" setting (switch on advanced view).
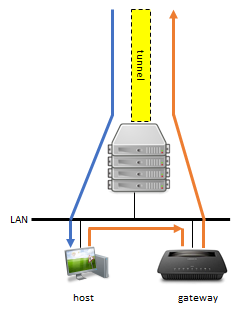
 1 point
1 point -
Thanks for the quick writeup! I was scratching my head for a good 10 minutes until I realized I had to toggle Inactive to Active. Not sure why my mind read that as clicking inactive would inactivate it. Once I properly toggled that setting, my phone immediately connected. I can access my network devices by IP address, but didn't have any luck by local hostname. Not sure if its a config issue on my router (pfsense) or just how it is with Wireguard. No issue with that though when connecting via openvpn on pfsense. This is a great method to get secure access to your server/network without much fuss, and am looking forward to seeing how the implementation progresses! I think it will help a lot of unRAID users!1 point
-
I have 96gb installed 4x8GB and 4x16GB. my issue is similar in that it only shows 32GB in unraid as usable and installed, in Windows 10 everything works PERFECT all 96GB show, but 64GB of the ram is missing in unraid 6.6.6 or 6.7.2 If you read what I posted through this thread, you would have seen where I said... which is exactly what you found. Linux in general is more picky about hardware, or to be more accurate, hardware vendors spend much less time making sure their products are compatible with linux than windows. Something that "just works" in windows may very well have issues in linux. Unraid doesn't author the linux kernel they use, they just package it.1 point
-
Hi Guys i have made a tutorial to help new unraid users who are not familiar with unRAID VMs. It shows what to do first and what settings you must use in your motherboard bios to be able to sucessfully create unRAID VMs. It discusses HVM and IOMMU and how to check IOMMU groups for sucessful hardware passthrough. An introduction to VMs including bios settings, iommu groups1 point
-
Learned alot already - but more to go I love this ZFS - it was exactly what I was looking for to pool my 2 SSDs for docker/vm storage. Couple of bumps and had to rethink and move things around... but I now has a 2 SSD zfspool, and my docker/vm stuff mounted and shared in zfspool/appdisk as /mnt/appdisk and I LOVE IT! Thank you so much for this plugin! Myk1 point


























