Leaderboard



Popular Content
Showing content with the highest reputation on 04/11/21 in Posts
-
It's a bug, mover isn't working for shares with a space in the name, you should create a bug report. As a workaround you can rename the share, using for example an underscore.2 points
-
If you did a format then that would create an empty file system and update parity to reflect this. When you try and format you get a big warning telling you that format is not part of a rebuild. if you still have the old disk intact it should be possible to mount it using UD and then copy the files back to the array.1 point
-
Unraid does not automatically format a drive. If the drive came up as unmountable either prior to or after the rebuild process, a popup would have showed up that stated that "Formatting is never part of a rebuild process". Did you tell Unraid to format the drive? This is what caused the problem. By changing the format of the drive, it basically would've had to format the drive. (But still would have prompted you) What you want to do is take a note of all the current drive assignments, do a Tools - New Config, and then reassign the drives and substitute the original data drive back in in lieu of the replacement. If anything comes up as unmountable, STOP and then post your diagnostics and wait for a response. Let parity rebuild and then do the substitution. After that, to change the format of the drive, you first have to copy all of the files off of that drive and then once it's empty format it.1 point
-
Hatte ich damals bei meiner macOS-VM auch. Lag bei mir am falschen Model des virtuellen Adapters. Meine funktionierende Config dazu sieht so aus: <interface type='bridge'> <mac address='XX:XX:XX:XX:XX:XX'/> <source bridge='br0'/> <model type='e1000-82545em'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </interface>1 point
-
PM is a Miner for GPUs -see https://phoenixminer.org/ I would recomend to read about cryptos first. But basically it is possible to mine ETH with a CPU but very much not recomended. Have a look at monero for that purpose. came to this thread to point out that you have to install and start the docker first w/o the extra parameter for nvidia. than the docker will start but give you an error. Edit the docker and add the nvidia parameter => starts up fine. my 1070 does around 28MH/s which can be tweaked by some overclocking & undervolting (to around 30-32) which I have no idea how to do in unRaid.1 point
-
Stop the array but don't shut down or reboot. After it finishes stopping the array (or if it doesn't) post diagnostics. See here for how "unclean shutdown" works:1 point
-
1 point
-
You probably filled it up See this recent thread for a fairly detailed discussion on settings that help keep you from filling disks:1 point
-
I think the issues are due to changes at ookla (could be wrong though). Either way, I'm having CA mark 2018.02.11 as being incompatible as it doesn't work at all.1 point
-
I never passed thru USB controllers just used USB mapping in VMs. But no issues. There are plugins to allow dynamic mapping , including one of my own(usbip-gui beta) which has expanded past just USBIP, currently changing to name to USB_Manager and making the USBIP optional. Do you have any devices of the same Vendor/model you want to passthru? The disk port to the HBA will run at 6Gps if the drive supports it. The PCIe Connections are 1 PCI-E 3.0 x8 (in x16 slot), 1 PCI-E 3.0 x8 1 PCI-E 2.0 x4 (in x8 slot) The last one will only provide 2Gbps from the card to the CPU. Which is the same for my MB. I can't say I noticed any impact when running with Disks, but there is a potential for a bottleneck.
 1 point
1 point -
1 point
-
Die Fehlermeldung geht auch nicht weg, die besteht bis in alle Ewigkeit. WICHTIG ist zu gucken ob sich die Fehleranzahl erhöht. Nur wenn die sich ändert/erhört existiert das Problem weiterhin. Bleibt die gleich, ist das nur eine Info, dass es mal einen Fehler gab. Und UDMA_CRC_Error hat halt seltenst etwas mit der HDD/SSD zu tun. Kabel, Stecker, Buchsen und ganz eventuell noch die Controller (sowohl auf dem Board als auch auf der HDD/SSD). Auch ungefähr in der Reihenfolge - das sind die Übeltäter.1 point
-
No, this is not the case with every Docker template but game servers are not normal Containers in terms of port forwarding. Take Valheim for example, the default game port for example is 2456 (game port) then there is the port 2457 (query port) and the port 2458 (I don't know what it's exactly for but if you close it you cannot connect to the server). When you try to actually connect to the game, the game tries to connect to the default query port to get all necessary information on port 2457 and the query port actually responds with a message to the game that the game port is on 2456 and then a connection is established. Now imagine what's happening when you only forward the ports from 2456, 2457, 2458 to lets say +10 (2466, 2467, 2468) if you type in the Steam Server Browser for example YOURSERVERIP:2467 you will actually see the game but if you click on it and the game fires up and it get's the answer from the query port that the game actually runs on port 2456 and not on the forwarded port 2466 like in this example and a connection can not be established. For a normal web server that don't rely on a query port (or at least nothing that's relying on a port that actually tells it back, "Hi, I'm on port 2466") you can forward or better speaking change them in the template. Also Steam Ports 27015-27030 really don't like to be translated from on to another port because they actually tell the game: "Hi, I'm running on port 27015" and if you translate that again to let's say for example to 27016, you can see the game possibly in the server list because it's broadcasting that it's running but if you try to actually connect the port or the application tells the client to connect on port 27015 and 27016. But as said above that applies not to every game! Hope that makes sense to you. That's up to you, I would also add these settings, like you did, to the Startup Parameters, since it's basically the same as if you change it in the config file.1 point
-
Both no problem.1 point
-
Is the Card already flashed to IT Mode? If not you should re-flash. https://flemmingss.com/how-to-flash-it-mode-firmware-to-hp-lsi-sas-9212-4i-controller-card/1 point
-
Thank you for your help. I would have ran into the same issue with cloning the share. Problem should be solved with renaming.1 point
-
Note it's only not moving from array to pool, it still does from pool to array, even with a space in the name.1 point
-
Share doesn't yet exist on that disk, once it does space will be correct.1 point
-
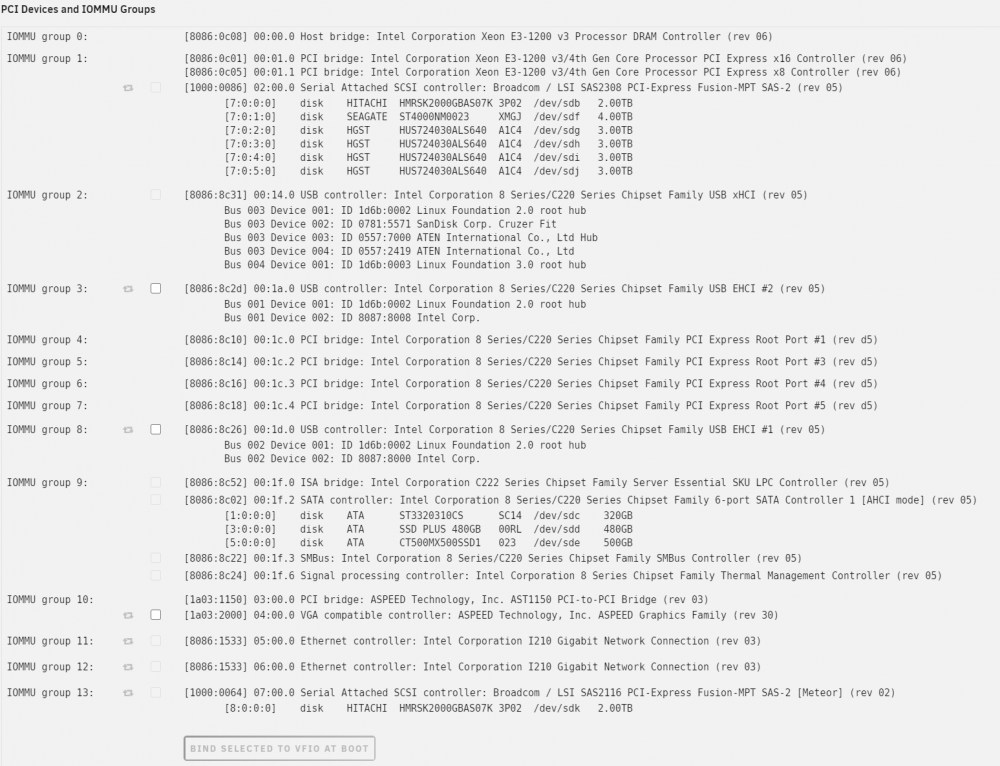
Hi, I have a X10SL7-F which is similar with a built in SAS HBA and one less slots. The HBA will connect multiple devices and will support SAS and SATA drives. Normally they tend to have a couple of ports and you will need a fan out cable to connect to the drives. This is now my test box so dont have a GPU installed and using passthru, but did have a GT710 when it was my prod server and passed it thru to a WIn10 VM. And used the IPMI for console which uses the ASPEED VGA Screen so dont need to have a monitor connected. Also I have an 16 port HBA with external connections at the bottom.
 1 point
1 point -
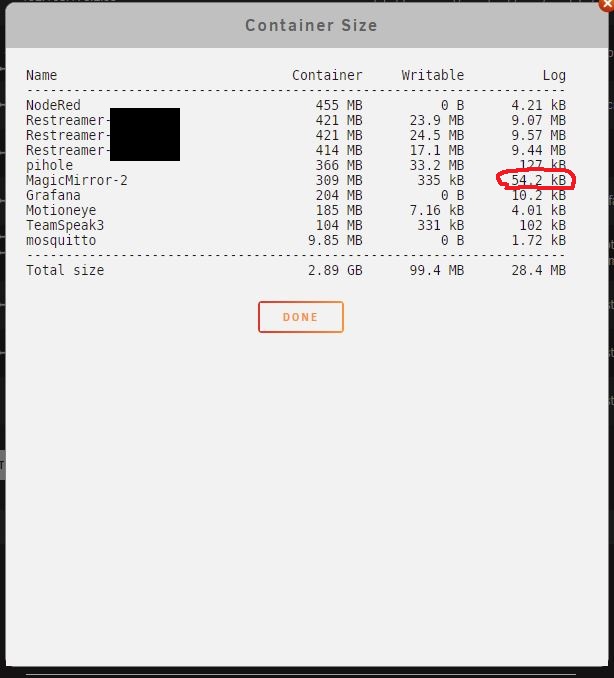
Mh did nothing other then restart the MagicMirror2 Docker. Now the Log is no longer 18GB in size. The Logfiles of MM did grow over the last weeks. I restarted unraid and the docker multible times. feels like the docker knew i would open a helpthread and deleted it it self. sorry for your time.
 1 point
1 point -
Due to overwhelming demand (3 people 😂), I've just released a new version works with both AMD and likely Nvidia GPUs as well. You'll need to re-add the container from CA and use the repository to lnxd/xmrig:latest-root to use the new features; it'll probably get picked up some time within the next 2 hours. I haven't got an Nvidia GPU to test it with so if someone gets it working with one, please let me know. But be patient, it takes around 10 mins to install Cuda for me before it gets to the mining stage, I'm gonna work on reducing that when I get a chance. It now includes XMRig 6.11.1 binaries made as part of the docker build process rather than separately, and it's 26mb smaller than before even with the optional CUDA library layer, probably because I got better at writing Dockerfiles? Not sure 😅 In case anyone is worried about bloat, the container doesn't contain the drivers by default. If you want to use them you need to select a version and it will install them. PS. Sorry, I hate to double post rather than just edit. But I thought people monitoring this thread might be interested to see without getting an annoying alert. Except @Steace1 point
-
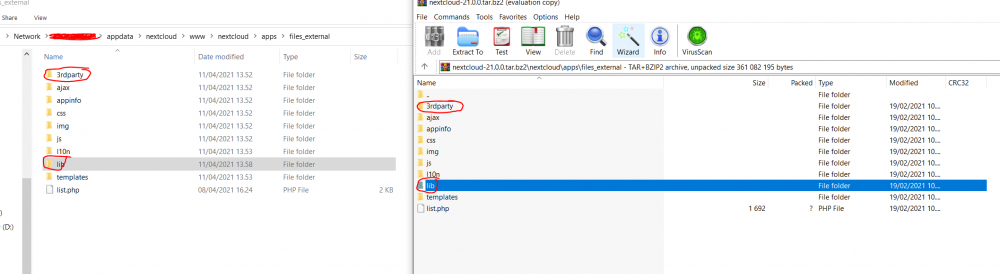
I got the same error when I updated to 21.0.1, and for me, it turned out to be the "external storage" application (which I'm using to get access to SMB shares in the Nextcloud app) I got this fixed by simply removing the "files_external" folder found in: \\YourServer\appdata\nextcloud\www\nextcloud\apps\ However, now I can't see the External Storages- application within the appstore of NC, so I'm trying to figure out how to re-install said app in order to access the SMB shares once again. EDIT! Haven't done a-lot of testing yet, but I think I got everything to work now! Ok so, I downloaded the tar/zip file for NextCloud 21.0.0 from their website: https://nextcloud.com/changelog/#latest20 I then manually moved two folders into the NextCloud installation folder. So, in your Unraid server, navigate to: \\YourServer\appdata\nextcloud\www\nextcloud\apps\files_external\ 1. You see a folder named "lib" in there, remove it. 2. Open your tar/zip file you just downloaded, navigate to the same folder, and move the "lib" folder from the tar/zip file to replace your removed "lib" folder. 3. Do the same to the "3rdparty\icewind" folder. And that seemed to do the trick for me! Sorry for the bad explanation, I'm just getting a bit tired at this point, hah!
 1 point
1 point -
Damn, my post was delayed by the stupid forum reboot and I am late to the party !1 point
-
CRC errors are a known issue with some Samsung SSDs and those AMD chipsets, other issue looks like a hardware problem, like a bad PSU, CPU, board, etc.1 point
-
That’s right. I remember the ipmi2json not being quite smooth had to do some manual switches to get it to work. Once the board.json is configured the ipmifan will just work fine now 👌🏼 Glad to see it working1 point
-
Thank you @cakes044! I got It working on my X570D4U-2L2T. ipmi2json worked when I switched all the fans to manual mode in the BMC. Think $manual_cmd wasn't doing it for me for some reason. Didn't look too hard since there's a workaround. I also had to adjust the fan positions in the board.json as they were bumped down by one. ipmifan does work great as-is though! Thanks again.1 point
-
@ChatNoir - I didn't. I will be once I recover. @JorgeB - I think the PCI-E slot on my X399 motherboard failed or something. I spent the last 4 hours migrating my i7700K board, memory and CPU to my UNRAID system, managed to get all drives assigned (except my cache pool), checked parity valid and started the array. It looks like everything is being seen and there is at least data on each of the drives now. I am running the parity check now, I did notice that it found quite a few errors already (perhaps its fixing the replacement drive that's blank). Looking at the "MAIN page" no errors yet. I think at this point last time there was a ton. We might be on the right track! Once this is done, I suppose I have to troubleshoot the cache pool so that the dockers and such start running properly. I appreciate all the help so far everyone. The community spirit is great

 1 point
1 point -
Is anyone interested in some of the settings to get this working using flux (influxdb v2.0 language / API). Have gotten about half of the queries re-written for it atm.1 point
-
Bingo. That sorted it, thanks. I'd got an old rule blocking port 80 sitting at the bottom of my rules list that I'd missed and forgotten to disable again. I've unblocked it and Letsencrypt can now issue the certificate 😊1 point
-
Ja super!! Ne, bei mir läuft alles.. frag nur interessehalber. Ja, die Soundkarte sollte generell immer mit auf den gleichen bus gesetzt werden, so wie es "original" auch ist. Was die Konfiguration betrifft, ist macOS deutlich "empfindlicher"... Aber wenn richtig konfiguriert, dann stabil, schnell und effizient. Nur mal so btw... Bei idle Betrieb mit aktivem Displayoutput spart macOS gegenüber Windows ca. 20w bei meinem Server...1 point
-
Thanks for the heads up @Squid! A very good call to do this after the recent wave of compromised servers with XMRig running. I'll update OP. And @jonathanm that recommendation made me laugh this morning, it was one of the first things I read when I woke up and it's very true 🤣 Hey @Steace! Yup you sure do. Otherwise it'll be a looooonngg time to payout. Just make sure you note their transaction fee when you're reducing the value. If you slip it into the worker field it should work, eg. Unraid/[email protected]. Then just let it mine for a while before trying to update the payout threshold on the Nanopool website.
 1 point
1 point -
Danke für den Tipp bezüglich der cfg-Files, die benötigte ist die /boot/config/smart-one.cfg [VMware_Virtual_NVMe_Disk_VMWare_NVME-0000] hotTemp="11760" maxTemp="11780" Einen feature request werde ich morgen erstellen, wobei ich kaum glaube, dass die Anfrage auf der road map landet.1 point
-
Er meint PlugIns innerhalb von Magic Mirror...1 point
-
As long as you are on the latest version of the Unraid.net plugin, there isn't anything else you need to do. Once we get the connection issues resolved this logging will stop. Thanks for helping us test!1 point
-
I have a xeon e5-2690v3 and had --asm intel and --randomx-1gb-pages but I could never seem to get the 1gb pages to work. When I removed those two arguements my H/s actually went UP about 200 H/s. I have no idea why. Have you done before/after to see what difference they are making? Also, can you tell in your container log that your actually getting 1gb pages?1 point
-
Constant disk activity Just installed the Paperless-ng and Redis dockers and it works, very nice:) My only issue is that the Redis docker produces a constant disk activity (super steady 144 KB/s write, no read activity) at all times. I removed all documents from Paperless-ng but the disk activity still persists. As soon as I stop the Paperless-ng docker the disk activity of the Redis docker stops, so it definitely has something to do with Paperless-ng. This seems to be a bug, why would Redis need a constant 150KB/s write stream when there is no activity at all in the Redis or Paperless-ng dockers? I checked the free memory in the Redis docker to see if it isn't swap activity but that's not the case. Anybody any idea what is happening? This constant disk useless disk activity is preventing me from using paperless-ng at the moment as it will wear out my cache SSD like this. I am using the Redis docker image from A75G's Repository SOLVED: Switched to another Redis docker image from jj9987's Repository and now no more weird disk activity. New problem: Unraid started giving me warnings that the Docker image was quickly filling up with about 1% per 5 minutes. I looked at the container sizes (bottom unraid docker page) and saw that the paperless-ng container was 7GB big... Looking at the paperless-ng log files I saw a huge amount of documents stuck in the tmp folder. So remapped the tmp folder to the appdata folder solved the problem and the paperless-ng container stayed steady at a size just over 1GB after a clean re-install. But the weird thing is that the tmp folder keeps growing and those files are somehow never deleted by paperless-ng (at least not in the 2 days timeframe I watched it). The folder grew to a whopping 7GB again. Is this a bug?1 point
-
Great, thanks!1 point
-
@xthursdayx It is actually much easier than that. Simply copy the contents of your "/mnt/user/appdata/rutorrent/rtorrent/rtorrent_sess" into the following folder : "/mnt/user/appdata/binhex-rtorrentvpn/rtorrent/session" Everything should be good to go.1 point
-
If your DNS is resolving to cloudflare are you 100% sure the '/config/letsencrypt-acme-challenge' is also forwarded correctly? Letsencrypt needs to contact your server (over http) to verify the signature.1 point
-
Without the diagnostics, assuming that it's very early in the boot process when it's initializing the cores, it's not a problem and safe to ignore.1 point
-
Thanks @bytchslappa for the heads up. Everyone using a User Script for Nvidia GPU Power State just edit the script to: #!/bin/bash nvidia-persistenced fuser -v /dev/nvidia* and leave the schedulle At first Array start only unchanged.1 point
-
Please provide the instructions for doing this in the Official Unraid Manual (the one you get to by clicking lower right-hand corner of the GUI) and not just in the release notes of the version number when the changes are introduced. Remember that many folks are two or three releases behind and then when they do upgrade they can never seem to locate the instructions which results in unneeded queries that the folks who provide most of the support for Unraid have to deal with. Having an updated manual section that deals with these changes makes pointing these folks to find what they will have to change a much similar task... EDIT: I would actually prefer that you link directly to the manual sections in the change notes. That way the information will be available in the manual when the changes are released!1 point
-
Yes that possible, just put multiple IP's to that field separated by a comma.1 point
-
For me, I had to open up the query and then right click on the icon. However, it still is not working for me. I've tried a mix of HTTPS and HTTP to no avail.1 point
-
Right now this link is dead. I'll check it later. here is the new issue i created. If you want you can do a comment there with your steps. and if you have the error still. https://github.com/linuxserver/docker-nextcloud/issues/189 Edit* Check the issue for the solution. TL?DR? Update docker, delete /config/nginx/site-confs/default, restart docker, Go to Settings > Overview, (for chrome) Press F12 and while having dev tools open right click refresh button and click emtpy cache and hard reload.1 point
-
OK guys, multi remote endpoint support is now in for this image please pull down the new image (this change will be rolled out to all my vpn images shortly). What this means is that the image will now loop through the entire list, for example, pia port forward enabled endpoints, all you need to do is edit your ovpn config file and add the remote endpoints at the top and sort into the order you want them to be tried, an example pia ovpn file is below (mine):- remote ca-toronto.privateinternetaccess.com 1198 udp remote ca-montreal.privateinternetaccess.com 1198 udp remote ca-vancouver.privateinternetaccess.com 1198 udp remote de-berlin.privateinternetaccess.com 1198 udp remote de-frankfurt.privateinternetaccess.com 1198 udp remote france.privateinternetaccess.com 1198 udp remote czech.privateinternetaccess.com 1198 udp remote spain.privateinternetaccess.com 1198 udp remote ro.privateinternetaccess.com 1198 udp client dev tun resolv-retry infinite nobind persist-key # -----faster GCM----- cipher aes-128-gcm auth sha256 ncp-disable # -----faster GCM----- tls-client remote-cert-tls server auth-user-pass credentials.conf comp-lzo verb 1 crl-verify crl.rsa.2048.pem ca ca.rsa.2048.crt disable-occ I did look at multi ovpn file support, but this is easier to do and as openvpn supports multi remote lines, it felt like the most logical approach. note:- Due to ns lookup for all remote lines, and potential failure and subsequent try of the next remote line, time to initialisation of the app may take longer. p.s. I dont want to talk about how difficult this was to shoe horn in, i need to lie down in a dark room now and not think about bash for a while :-), any issues let me know!.1 point
-
Is the process still so complex in Oct 2019, for the linux untrained? I want to share my /mnt/user to my NethServer . Can I have a step by step "stupid-proof" guide?1 point
-
I used the plugin "Nerd Tools". Installed "kbd-1.15.3-x86_64-2.txz" (Settings - Nerd Pack) and added this to the go file on flash for Swedish keyboard (qwerty) in terminal etc: # load keyboard layout loadkeys se-latin1 For german (qwertz), you have these: de-latin1-nodeadkeys de-latin1 de-mobii de de_CH-latin1 de_alt_UTF-8 Add and reboot (you can also try it out by running "loadkeys de-latin1-nodeadkeys" in the server terminal without rebooting ofc). You could also download kbd-1.15.3-x86_64-2.txz manually and put it in to flash/extra folder and it will install at boot instead of using Nerd Tools. I hope this helps.1 point
-
Ok so I just added a path in the Krusader container settings (attached), restarted the container, and that seemed to solve the issue.
.png.63ff8d13d4e97ace36c2682f089fdfe3.png) 1 point
1 point -
Read this post and the next half-dozen and see if any one of these situations apply to you: Also, on your Windows computer, go to 'Control Panel' and then 'Credential Manager' to see if Windows is storing any login credentials.1 point









































.png.63ff8d13d4e97ace36c2682f089fdfe3.png)