Leaderboard



Popular Content
Showing content with the highest reputation on 02/16/23 in all areas
-
Neuer bzw. finaler Stand. Es war, wie schon sehr früh von vielen vermutet, das Netzteil. Ich habe am Montag einmal ein altes ausgemustertes von einem Kumpel angeschlossen. Der Server läuft seitdem ohne Probleme so wie vor der ganzen Problematik. Array, Docker und VMs laufen. Ich werde das bisher genutzte zum Händler/Hersteller zur Überprüfung schicken. Solange kann ich das provisorische nutzen. Vielen Dank an alle für die Tipps und Vorschläge! ❤️2 points
-
You know it's a good day when you see a beta drop! 6.12.0-beta15!2 points
-
That talks about backing up other data sources to Unraid, backing up Unraid array data to another Unraid server, etc. Nowhere does it say that the Unraid parity protection is a backup of your array data. I do both of the things mentioned above; backup PCs to Unraid and backup my main server array data to a second Unraid server. I also backup important data to external USB drives and the cloud. Parity only protects against disk failure and can aid in the recovery of a failed disk if all other array disks are readable but it does not contain any data at all and is, therefore, not a backup. No irony at all in this thread as it is talking about something completely different than what you linked.2 points
-
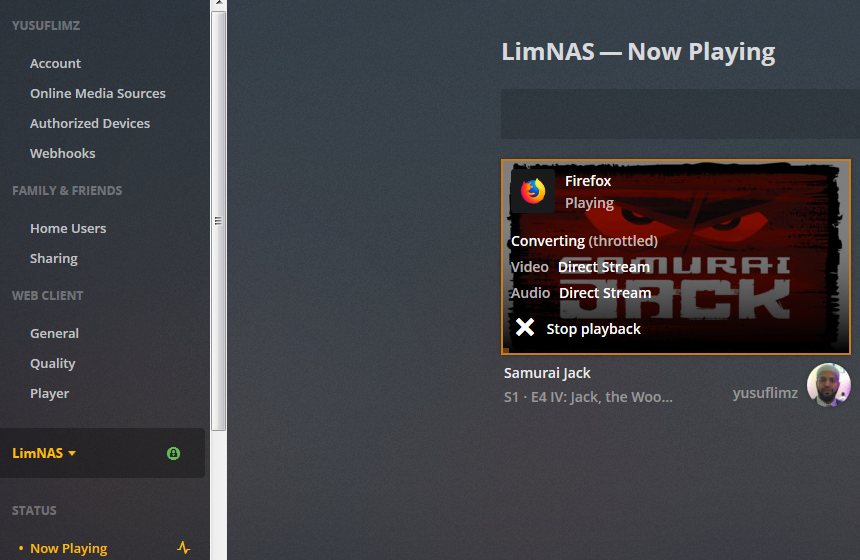
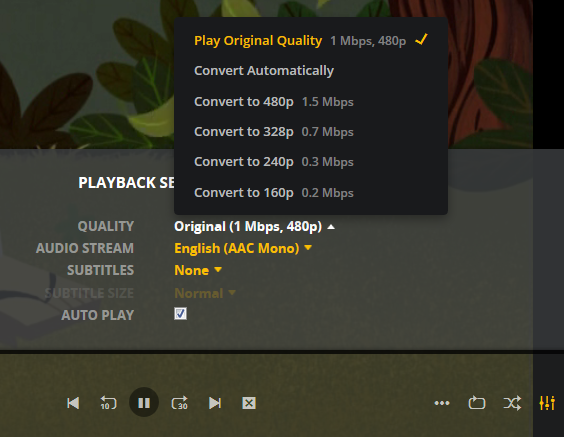
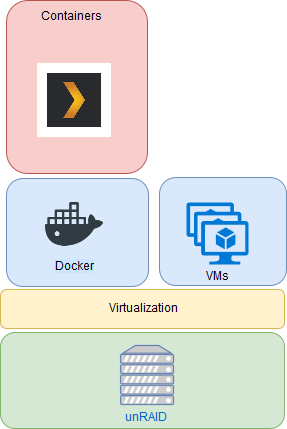
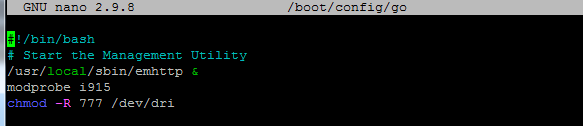
***Update*** : Apologies, it seems like there was an update to the Unraid forums which removed the carriage returns in my code blocks. This was causing people to get errors when typing commands verbatim. I've fixed the code blocks below and all should be Plexing perfectly now Y =========== Granted this has been covered in a few other posts but I just wanted to have it with a little bit of layout and structure. Special thanks to [mention=9167]Hoopster[/mention] whose post(s) I took this from. What is Plex Hardware Acceleration? When streaming media from Plex, a few things are happening. Plex will check against the device trying to play the media: Media is stored in a compatible file container Media is encoded in a compatible bitrate Media is encoded with compatible codecs Media is a compatible resolution Bandwith is sufficient If all of the above is met, Plex will Direct Play or send the media directly to the client without being changed. This is great in most cases as there will be very little if any overhead on your CPU. This should be okay in most cases, but you may be accessing Plex remotely or on a device that is having difficulty with the source media. You could either manually convert each file or get Plex to transcode the file on the fly into another format to be played. A simple example: Your source file is stored in 1080p. You're away from home and you have a crappy internet connection. Playing the file in 1080p is taking up too much bandwith so to get a better experience you can watch your media in glorious 240p without stuttering / buffering on your little mobile device by getting Plex to transcode the file first. This is because a 240p file will require considerably less bandwith compared to a 1080p file. The issue is that depending on which format your transcoding from and to, this can absolutely pin all your CPU cores at 100% which means you're gonna have a bad time. Fortunately Intel CPUs have a little thing called Quick Sync which is their native hardware encoding and decoding core. This can dramatically reduce the CPU overhead required for transcoding and Plex can leverage this using their Hardware Acceleration feature. How Do I Know If I'm Transcoding? You're able to see how media is being served by playing a first something on a device. Log into Plex and go to Settings > Status > Now Playing As you can see this file is being direct played, so there's no transcoding happening. If you see (throttled) it's a good sign. It just means is that your Plex Media Server is able to perform the transcode faster than is necessary. To initiate some transcoding, go to where your media is playing. Click on Settings > Quality > Show All > Choose a Quality that isn't the Default one If you head back to the Now Playing section in Plex you will see that the stream is now being Transcoded. I have Quick Sync enabled hence the "(hw)" which stands for, you guessed it, Hardware. "(hw)" will not be shown if Quick Sync isn't being used in transcoding. PreRequisites 1. A Plex Pass - If you require Plex Hardware Acceleration Test to see if your system is capable before buying a Plex Pass. 2. Intel CPU that has Quick Sync Capability - Search for your CPU using Intel ARK 3. Compatible Motherboard You will need to enable iGPU on your motherboard BIOS In some cases this may require you to have the HDMI output plugged in and connected to a monitor in order for it to be active. If you find that this is the case on your setup you can buy a dummy HDMI doo-dad that tricks your unRAID box into thinking that something is plugged in. Some machines like the HP MicroServer Gen8 have iLO / IPMI which allows the server to be monitored / managed remotely. Unfortunately this means that the server has 2 GPUs and ALL GPU output from the server passed through the ancient Matrox GPU. So as far as any OS is concerned even though the Intel CPU supports Quick Sync, the Matrox one doesn't. =/ you'd have better luck using the new unRAID Nvidia Plugin. Check Your Setup If your config meets all of the above requirements, give these commands a shot, you should know straight away if you can use Hardware Acceleration. Login to your unRAID box using the GUI and open a terminal window. Or SSH into your box if that's your thing. Type: cd /dev/dri ls If you see an output like the one above your unRAID box has its Quick Sync enabled. The two items were interested in specifically are card0 and renderD128. If you can't see it not to worry type this: modprobe i915 There should be no return or errors in the output. Now again run: cd /dev/dri ls You should see the expected items ie. card0 and renderD128 Give your Container Access Lastly we need to give our container access to the Quick Sync device. I am going to passively aggressively mention that they are indeed called containers and not dockers. Dockers are manufacturers of boots and pants company and have nothing to do with virtualization or software development, yet. Okay rant over. We need to do this because the Docker host and its underlying containers don't have access to anything on unRAID unless you give it to them. This is done via Paths, Ports, Variables, Labels or in this case Devices. We want to provide our Plex container with access to one of the devices on our unRAID box. We need to change the relevant permissions on our Quick Sync Device which we do by typing into the terminal window: chmod -R 777 /dev/dri Once that's done Head over to the Docker Tab, click on the your Plex container. Scroll to the bottom click on Add another Path, Port, Variable Select Device from the drop down Enter the following: Name: /dev/dri Value: /dev/dri Click Save followed by Apply. Log Back into Plex and navigate to Settings > Transcoder. Click on the button to SHOW ADVANCED Enable "Use hardware acceleration where available". You can now do the same test we did above by playing a stream, changing it's Quality to something that isn't its original format and Checking the Now Playing section to see if Hardware Acceleration is enabled. If you see "(hw)" congrats! You're using Quick Sync and Hardware acceleration [emoji4] Persist your config On Reboot unRAID will not run those commands again unless we put it in our go file. So when ready type into terminal: nano /boot/config/go Add the following lines to the bottom of the go file modprobe i915 chmod -R 777 /dev/dri Press Ctrl X, followed by Y to save your go file. And you should be golden!



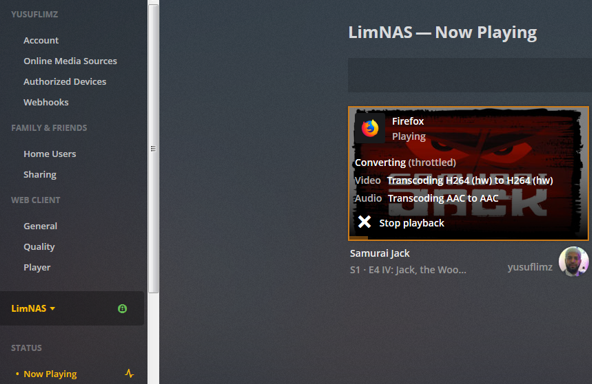
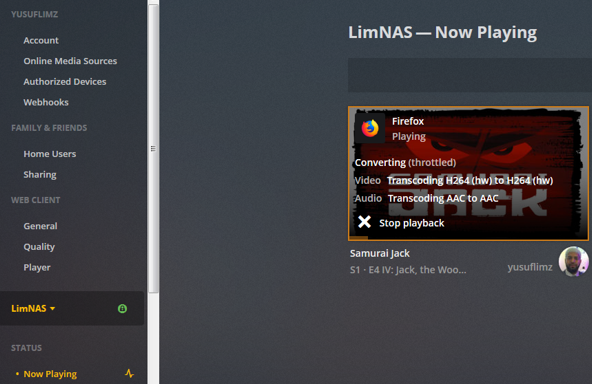 1 point
1 point -
In a new post in the thread/topic, upload the diagnostics file. Then setup the syslog server. Instructions are here: https://forums.unraid.net/topic/46802-faq-for-unraid-v6/page/2/?tab=comments#comment-781601 Next time, server goes offline, upload the syslog file--- again in a new post with any additional information that you may feel might help in figuring what is going on. IF you think it might be several days before the problem happens , you could run a memtst from the boot-up menu if you have non-ECC memory. (ECC will require that you download the program directly from the vendor.) Recommended time for the test is 24 hours and zero failures are the only acceptable result.1 point
-
Es zeigt Raid1 an, ja, dann ist es Raid 1.1 point
-
naja, lass mal 3 Tage laufen, wenn ok, wechsel nochmal mit und teste dann ... wenn es dann wieder nach 1 - 2 Tagen Probleme gibt wäre es ja offensichtlich.1 point
-
I'm into OTA and antennas big time and there is another really good use for the HDHomeRun, aiming your antenna with extreme precision. In most cases, all you need in addition to an HDHomeRun is this app (Signal GH): https://apps.apple.com/us/app/signal-gh/id289580769 The app provides MUCH more detail on the signal quality you are receiving than what you get built into your TV or DVR. You can also sit up on your roof or in your attic with just your cell phone and perfectly align your antenna. Also, if you are in an area of high signal strength, but a lot of multipath (city), you can use an attenuator between the antenna and HDHomeRun with the app to reduce your signal strength and get great data on just the quality of the signal. A 2-tuner HDHomeRun and the Signal GH app can do nearly as good a job as a dedicated ATSC analyzer, and those cost megabucks!1 point
-
Main problem is this Feb 14 07:09:39 Tower kernel: x86/PAT: ipmi-sensors:18442 map pfn expected mapping type uncached-minus for [mem 0xacd8b000-0xacd8bfff], got write-back No clue what to make of it, but uninstalling the ipmi plugin would definitely fix it.1 point
-
It should just be Settings->Management Access1 point
-
It USED to be 2GB RAM as the minimum requirement for Unraid v6 but as the functionality has increased so has the RAM requirement. Unraid runs from RAM so every bit of functionality added incurs a RAM cost.1 point
-
Den Fall habe ich auch. Dazu kann man Bitlocker aus Windows auch unter LInux einbinden. Das mache ich aber nicht für mein Unraid Backup, sondern das ist für unsere "normale" portable USB für den täglichen Gebrauch. https://it-learner.de/auch-unter-linux-laesst-sich-auf-einen-mit-bitlocker-verschluesselten-datentraeger-zugreifen/ Für meine Backup bleibe ich bei Linux eigener Luks verschlüsselung. Diese ist muss ja nicht für Windows errichbar sein, und ist in Unraid integriert. Die Passphrase lässt sich auch für unassigend Devices über die WebUi speichern, so dass auch ein automount möglich ist. So steht dem Backup Script von Mgutt nichts im Wege und ich kann problemlos meine zwei Platten im wöchentlichen Wechsel betreiben.1 point
-
1 point
-
I have gotten it sucessfully installed. thank you.. I will keep you posted!1 point
-
Make sure this is done and if yes enable the syslog server and post that after a crash.1 point
-
In general, you can always Acknowledge a SMART warning on the Dashboard page by clicking on it ( 👎) and it will warn again if it increases. Some are more important than others. An occasional CRC I usually just acknowledge, and maybe just check and reseat the connection next time I need to open the case. More frequent CRC needs to be taken care of. The screenshot you posted earlier with the checkboxes shows which Attributes get monitored. You can set these for all disks in Disk Settings, and override those settings for an individual disk in its settings. A disk has some sectors reserved to replace bad sectors. That is what reallocation is about. A few reallocated is usually OK as long as it isn't increasing. Pending sectors are sectors that will be reallocated when they are written again. These are a little more worrisome because it means the data at that sector can't be reliably read. You can insure these get written by rebuilding the disk. You can add to the list of SMART attributes for monitoring in Disk Settings or in the settings for an individual disk. Some disk manufacturers use the attributes a little differently. It is recommended that you add attributes 1 and 200 for WD disks.1 point
-
In many cases the overall Passed status is meaningless. It only changes if one of the attributes has a “Failing Now” status. The one that is the best indication of drive health is the Extended SMART test. If this cannot complete without error then you should be replacing the drive.1 point
-
Hier wirst Du Meinungen "von-bis" hören. Meine, wie folgt: Wenn kein Raid nötig, dann XFS. Wenn Raid nötig, dann BTRFS. Mein Szenario: Array: XFS Cache-Pool 1 > 2x 1TB SSD: BTRFS Cache-Pool 2 > 1x 500GB NVMe: XFS1 point
-
Ob du alles verschlüsseln solltest oder nicht, kannst nur du entscheiden, da wir deinen Bedrohungsgrad ja nicht kennen. Ich selber verschlüssel bei meinem privaten Server keine Festplatten. Da reicht in meinem Bedrohungscenario ein ordentlich abgesicherter Zugang zum Server. Wer keinen Zugriff darauf haben soll erhält auch keinen. Einzig meine Backup-Platte, die nicht im eigenen Haushalt verweilt ist dann natürlich verschlüsselt. Zum Dateisystem: Es wird hier immer noch vermehrt zu XFS geraten. BTRFS wird halt fürs Raid im Pool benötigt. Ich habe bewusst zu BTRFS gegriffen. Alle meine Laufwerke arbeiten damit. Es ist ein neueres Dateisystem, dass bei mir bisher auch wie zu erwarten einwandfrei läuft. Wenn du also meine Meinung hören willst. Greif ruhig zu BTRFS.1 point
-
I've run "New Permissions" not too long ago and everything matches what the help docs have for those Shares. Looking at this code, I'm reading it that if the "user.scandate" attr is empty then using -R should remove the three extra attrs but it doesn't seem to...Not sure where my setup is going wrong. if [[ -z $userdate || $((userdate/86400)) -le $epoch ]]; then ((count++)) setfattr -x user.$hash "$file" 2>/dev/null [[ $cmd == R ]] && setfattr -x user.scandate "$file" 2>/dev/null [[ $cmd == R ]] && setfattr -x user.filedate "$file" 2>/dev/null [[ $cmd == R ]] && setfattr -x user.filesize "$file" 2>/dev/null EDIT: Yeah, not seeing anything wrong in the code. Even if the user.scandate was 0 it still should respect the flags...What's going on with my system then. Cannot get this to kick off at all anymore.1 point
-
E.g. you create the /mnt/user/media/Sync/Daniel folder on unraid, you give /mnt/user/media/Sync as the map to /media in the template, and then in give select /media/Daniel as location for the sync.1 point
-
I've made 3 tokens that only have the DNS Edit, one for each zone:
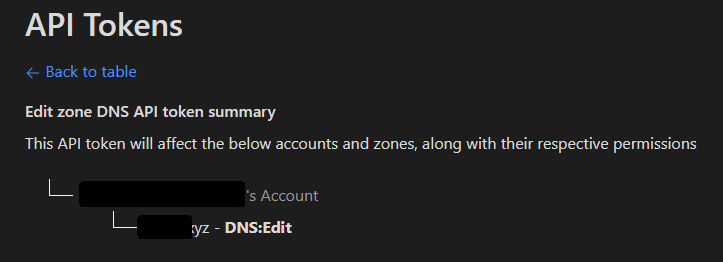 1 point
1 point -
Wie @alturismo bereits anklingen lies, ist es ein Problem des GPU-GUI-PlugIn's. Schau mal im entsprechenden Thread. Wenn Du Dir auf der Konsole die Aktivität der GPU anzeigen lässt (Befehl gerade nicht zur Hand), läuft es wie gewünscht.1 point
-
In fact there are 2 devices for each drive: one /dev/srX and one /dev/srY. Both usually need to be mapped. You can use the container log to see if you have correctly mapped the drives: [cont-init ] 54-check-optical-drive.sh: looking for usable optical drives... [cont-init ] 54-check-optical-drive.sh: found optical drive [/dev/sr0, /dev/sg3], but it is not usable because: [cont-init ] 54-check-optical-drive.sh: --> the host device /dev/sg3 is not exposed to the container. [cont-init ] 54-check-optical-drive.sh: found optical drive [/dev/sr1, /dev/sg4], group 19. [cont-init ] 54-check-optical-drive.sh: WARNING: for best performance, the host device /dev/sr1 needs to be exposed to the container. So in you case, one container should have: /dev/sr0 /dev/sg3 And the other should have: /dev/sr1 /dev/sg4 The new image is already available1 point
-
I'm going to summarize where we are and suggest ways to proceed in case anyone else wants to get involved. Multiple disk problems during parity rebuild. Since then, parity and disk4 have many pending sectors. Disks 1, 2 seem OK. Disk4 currently disabled, disk3 missing and presumed dead. I am thinking about trying to get the array to emulate disk3 instead of currently disabled disk4 using the usual trick of New Config/Trust parity to get all disks into the array including a spare disk3, then disable disk3. I would expect emulated disk3 to be unmountable at that point, and usually we would repair filesystem before rebuilding. But since we aren't rebuilding on top of the original, and the whole array is pretty shaky anyway, maybe do the repair after rebuild (if we can even get that far). Other things that might be considered is cloning parity and disk4 before doing anything else, but that would mean even more spare disks. I'm going to ping some of the usual suspects @JonathanM @itimpi and of course @JorgeB Way past bedtime in that part of the world so probably be some hours before any response1 point
-
After 10 minutes of waiting, it completed. It shows a stacktrace: Lucee 5.3.10.97 Error (application) Message Error invoking external process Stacktrace The Error Occurred in /var/www/OnRequestEnd.cfm: line 3 1: <!--- Reset all file permissions ---> 2: <cfexecute name="/bin/chmod" arguments="766 /var/www/SetPerms.sh" timeout="10" /> 3: <cfexecute name="/var/www/SetPerms.sh" timeout="0" /> 4: <!--- Dump all variables ---> 5: <CFSET StructClear(variables)> Java Stacktrace lucee.runtime.exp.ApplicationException: Error invoking external process at lucee.runtime.tag.Execute.doEndTag(Execute.java:266) at onrequestend_cfm$cf.call(/OnRequestEnd.cfm:3) at lucee.runtime.PageContextImpl._doInclude(PageContextImpl.java:1056) at lucee.runtime.PageContextImpl._doInclude(PageContextImpl.java:948) at lucee.runtime.listener.ClassicAppListener._onRequest(ClassicAppListener.java:84) at lucee.runtime.listener.MixedAppListener.onRequest(MixedAppListener.java:45) at lucee.runtime.PageContextImpl.execute(PageContextImpl.java:2493) at lucee.runtime.PageContextImpl._execute(PageContextImpl.java:2478) at lucee.runtime.PageContextImpl.executeCFML(PageContextImpl.java:2449) at lucee.runtime.engine.Request.exe(Request.java:45) at lucee.runtime.engine.CFMLEngineImpl._service(CFMLEngineImpl.java:1216) at lucee.runtime.engine.CFMLEngineImpl.serviceCFML(CFMLEngineImpl.java:1162) at lucee.loader.engine.CFMLEngineWrapper.serviceCFML(CFMLEngineWrapper.java:97) at lucee.loader.servlet.CFMLServlet.service(CFMLServlet.java:51) at javax.servlet.http.HttpServlet.service(HttpServlet.java:764) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:197) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:541) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:135) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) at org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:687) at org.apache.catalina.valves.RemoteIpValve.invoke(RemoteIpValve.java:769) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:360) at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:399) at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:890) at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1789) at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1191) at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.base/java.lang.Thread.run(Thread.java:829) Timestamp 2/15/23 6:23:28 PM EST1 point
-
I probably would have chosen xfs for the array disks, but supposedly btrfs has some benefits. Just be sure you don't fill them too full. Default Highwater allocation will work just as well or better than Fillup for most purposes. Most Free is the least efficient. In any case, be sure to set Minimum Free for each of your User Shares to larger than the largest file you will write to the share, so Unraid will choose another disk when a disk gets too full.1 point
-
Keep this in mind... files are written as a whole on a single drive(while also having the parity drive) so if you lost 2 disks... you would still have access to the files on the remaining disks... A suggestion that I tell everyone. When looking at your shares and what write method to use... I suggest using the 'fill-up' choice... Files will be written on disk 1 till it's full then it will go to the next... decreases wear on the other disks and you dont have to wait for 3 disks to spin up...1 point
-
I snipped the 3.3V wire between the PSU and the first SATA power plug. AFAIK it doesn't serve any useful purpose and if really needed to I could reconnect. Saves all the hassle with tape. Under technical data you can check compaible accesories > Power Cables Compatible Cables and seems that one CS-6740 is compatible1 point
-
Thank you @JorgeB. My array is encrypted so clicking the button result in a "Missing encryption key" error, as no field is available to enter the passphrase. I rebooted the server once again and the START/STOP buttons are now showing, along with the passphrase field. Very weird indeed I wish you a good day. OP1 point
-
Or install the docker patch plugin from the apps tab.1 point
-
Hardware wise you are 100% correct. However. the number of times the tech community has had to deal with AMD systems not working well with anything not Microsoft Windows based is a long and tortured list. I'm not saying intel is perfect with linux, but AMD has a far worse reputation.1 point
-
Dang y'all getting twisted when there is nothing here but harmless fun. Let's see if we can get this thread back on the fun side before we lose it all together. Who is ready for beta 14?! As someone who has been on the beta train with 6.12 for awhile now, I haven't had to submit a bug report for anything in beta 13 so things are looking bright! Just remember guys, while we all know unRAID is a business and we all want to be keyboard warriors, for some people this is the only place they get to relax and have a good time; let's not try to sour the experience for everyone if you personally don't like the content, it's easy enough to just click away or start your own thread for more organized thoughts in a manner structured in your own way.1 point
-
I have to agree with @Lolight. Thanks.1 point
-
Il y a peut être eu un crash du WebGUI... Parfois il suffit de redémarrer tout ca : /etc/rc.d/rc.nginx restart /etc/rc.d/rc.nginx reload /etc/rc.d/rc.php-fpm restart /etc/rc.d/rc.php-fpm reload Le plus rapide, oui, c'est de redémarrer le serveur. Ca m'est arrivé une fois. Vérifie les RAM au cas où avec l'outil unRAID...1 point
-
You could create a linux live USB, boot from that, connect an external drive, and run the imaging from the internal drive to a file on the external.1 point
-
Following up to close this thread. I jumped over to another support thread, where ich777, our master of all things display related, helped me out. I had tried this earlier, but it didn't seem to work. Turned out it *does* work perfectly, from a power off start. There is some other issue going on, where a Reboot does display on the AMD iGPU but in a strange 640x960 resolution (output is long and squished). So at least a partial solution, and one which I can work around, now that I know what I know now.1 point
-
Our plan is to release a public beta soon(tm) which includes OpenZFS support and changes which Plugin authors need to be aware of. Posting this now as a sneak peak, more detail will follow. That said.... ZFS support: this will let you create a named pool similar to how you can create named btrfs pools today. You will have choice of various zfs topologies depending on how many devices are in the pool. We will support single 2, 3, and 4-way mirrors, as well as groups of such mirrors (a.k.a., raid10). We will also support groups of raidz1/raidz2/raidz3. We will also support expansion of pools by adding additional vdev of same type and width to existing pool. Also will support raid0. It's looking like first release we will support replacing only single devices of a pool at a time even if the redundancy would support replacing 2 or 3 at time - that support will come later. Initially we'll also have a semi-manual way of limiting ARC memory usage. Finally, a future release will permit adding hot spares and special vdev's such as L2ARC, LOG, etc. and draid support. webGUI change: there are several new features but the main change for Plugin authors to note is that we have upgraded to PHP v8.2 and will be turning on all error, warning, and notices. This may result in some plugins not operating correctly and/or spewing a bunch of warning text. More on this later... By "public release" we mean that it will appear on the 'next' branch but with a '-beta' suffix. This means only run on test servers since there may be data integrity issues and config tweaks, though not anticipating any. Once any initial issues have been sorted, we'll release -rc1.1 point
-
Several years ago, my wife got a new laptop. Before she gave the old one away to a friend, she deleted her chrome bookmarks from it. Of course, that propagated throughout chrome on her other devices and so she no longer had chrome bookmarks anywhere. Fortunately, I had our desktop computer imaged to my Unraid server, so I recovered them. Which also illustrates the fact that Unraid can indeed be a backup, just not the only copy of anything important and irreplaceable.1 point
-
It is detected at the usb layer but looks like the ether rtl driver is not picked up. May not be in stock unraid. RTL8156 / RTL8156B(S)(G) is required.1 point
-
Unless you are planning to mostly fill those data drives with the initial data load I would advise not using so many data slots. Each empty drive uses power on hours, and unnecessary risk if you do have a drive failure. All drives, even totally empty filesystems, participate end to end in the parity equation for rebuilding a failed drive. I typically recommend limiting the parity array free space to twice the capacity of your largest drive, and adding space only after you fall below that largest drive's worth of space. So, in your case, I recommend reducing free space down to 36TB at most, and adding back data slots when the free space falls below 18TB free. Excess capacity is better sitting on the shelf waiting to replace the inevitable drive failure instead of sitting in the array and potentially BEING the next drive failure. Even better is limiting the shelf time on your shelf, and using shelf time at the manufacturers end, so when you get the drive you have a longer warranty period and possibly a lower cost per TB. I typically keep 1 spare tested drive equal or larger than the biggest drive in service in any of my Unraid servers, if I have a drive failure I either replace the failed drive, or replace whichever makes sense and use the pulled good drive to replace the failure in another server. My drives migrate down the line from server to server, I have a backup server that still has some ancient 2TB drives that are still running fine. If one of those fails, my primary server gets an upgrade, and the good drive I replaced in the main server goes into the backup server to replace the failed drive. Tech happiness is a well executed backup system.1 point
-
Today I finally got my Unraid storage configured. It took a lot of time shuffling data around to move from my old server but today all finished. Which means I now have things setup as such: 2 x 18TB = Parity 2 x 18TB = Data 7 x 10TB = Data 2 x 2TB WD SN850 NVMe = Cache & VM's 1 x 2TB Samsung 970 EVO Plus = Probably a scratch drive for VM's not sure yet. I'm quite happy with Unraid so far. The array performance has actually been better than I expected. Admittedly I had low expectations and had ran it as a test on some other hardware to really test how it worked and the performance but even so it surpassed what I thought it would do. The 9500-8i HBA I bought has been a really good purchase able to run every disk maxed out without any performance issues which is as expected, I think I've only hit 1/5th of its total available bandwidth so far. That 2TB NVMe drive I've put in the server (Samsung Evo Plus) was originally going to be my disk cache drive but with the SN850's being so cheap I bought two of those and used one as my cache drive. I'm now not really sure what to do with the 2TB Evo Plus but perhaps it'll come in handy as a VM scratch drive or something else in the future.1 point
-
For other people looking for the answer without having to click through. It's 3 failed attempts in a 15 minute interval1 point
-
Nothing wrong with your container but if you use the default path in syncthing itself for adding folders to it will be at '~' AKA '/home/nobody' and will save the data into the container image and fill up the docker.img really quickly. I suggest changing the defaults such that the default path's line up with the mount to the host FS (whether that is making the default be `/home/nobody` instead of `/media` or changing the syncthing config). I in the end not a big deal to someone who knows what they are doing, but did take me some time to figure out as I was hoping defaults would have sane behavior and I wouldn't have to fiddle. Thanks for making this For newbs that are trying to get this to work, run the docker with default settings then change this in syncthing and make sure if you manually specify patsh you use something that starts with `/media`.
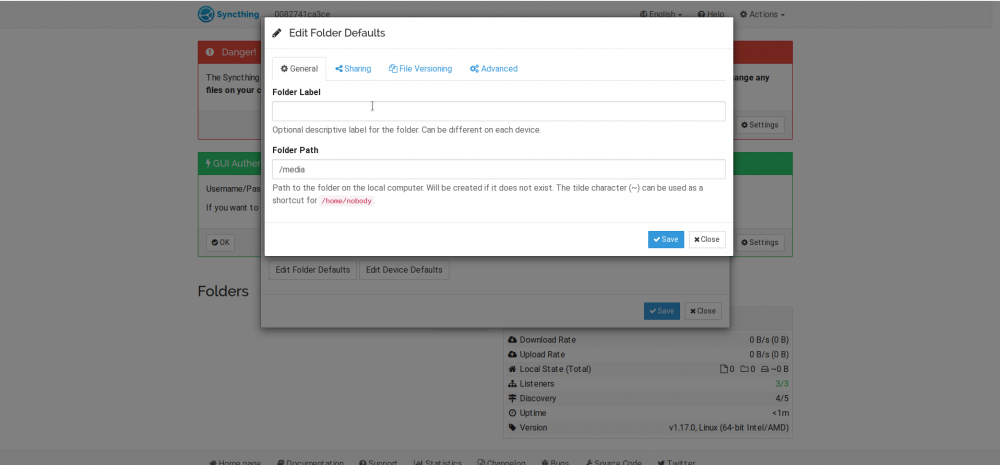 1 point
1 point -
To save some people digging through forum comments, this comment was the solution for me. Hopefully this helps!1 point
-
Do the following network configurations (see Settings -> Network Settings) Eth0 - bond = No, bridge = Yes (single member eth0), static IP address = 10.0.1.122 /24, gateway = 10.X.X.X Eth1 - bond = No, bridge = Yes (single member eth1), IP address = NONE --------------------------------------------------------------------------- Docker configuration (see Settings -> Docker) BR0 - uncheck BR1 - Subnet = 10.0.1.0 /24, gateway = 10.X.X.X, DHCP pool = 10.0.1.128 /25 (assuming this does not conflict with the DHCP range of your router) When you configure the Plex container, choose "Custom br1" as network and give the container the static address 10.0.1.1241 point
-
Check the current active interface cat /sys/class/net/bond0/bonding/active_slave Change the current active interface echo eth0 > /sys/class/net/bond0/bonding/active_slave1 point
-
Ok probably have to do a pkill find as well. Never had to stop the mover before. We'll see about adding some kind of cancel control. Not really recommended though. Why do you want to cancel it?1 point
-
That's useful to know, Tom. Thanks. Trouble is, I'll probably have forgotten it by the time I ever need to use it. A button in the GUI, as Homerr suggests, would be a handy addition.1 point
-
you still need to tell the array you are using a new disk configuration. Type: initconfig or, use the button in the web-interface in the "Utils" tab for a "New Config".1 point






































