Leaderboard




Popular Content
Showing content with the highest reputation on 04/12/21 in all areas
-
Just a friendly reminder everyone, discussing how to circumvent other vendors licensing will get content removed / banned from this forum. Tread lightly here3 points
-
Please provide the instructions for doing this in the Official Unraid Manual (the one you get to by clicking lower right-hand corner of the GUI) and not just in the release notes of the version number when the changes are introduced. Remember that many folks are two or three releases behind and then when they do upgrade they can never seem to locate the instructions which results in unneeded queries that the folks who provide most of the support for Unraid have to deal with. Having an updated manual section that deals with these changes makes pointing these folks to find what they will have to change a much similar task... EDIT: I would actually prefer that you link directly to the manual sections in the change notes. That way the information will be available in the manual when the changes are released!2 points
-
This release contains bug fixes and minor improvements. To upgrade: First create a backup of your USB flash boot device: Main/Flash/Flash Backup If you are running any 6.4 or later release, click 'Check for Updates' on the Tools/Update OS page. If you are running a pre-6.4 release, click 'Check for Updates' on the Plugins page. If the above doesn't work, navigate to Plugins/Install Plugin, select/copy/paste this plugin URL and click Install: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg Bugs: If you discover a bug or other issue in this release, please open a Stable Releases Bug Report. Thank you to all Moderators, Community Developers and Community Members for reporting bugs, providing information and posting workarounds. Please remember to make a flash backup! Edit: FYI - we included some code to further limit brute-force login attempts; however, fundamental changes to certain default settings will be made starting with 6.10 release. Unraid OS has come a long way since originally conceived as a simple home NAS on a trusted LAN. It used to be that all protocols/shares/etc were by default "open" or "enabled" or "public" and if someone was interested in locking things down they would go do so on case-by-case basis. In addition, it wasn't so hard to tell users what to do because there wasn't that many things that had to be done. Let's call this approach convenience over security. Now, we are a more sophisticated NAS, application and VM platform. I think it's obvious we need to take the opposite approach: security over convenience. What we have to do is lock everything down by default, and then instruct users how to unlock things. For example: Force user to define a root password upon first webGUI access. Make all shares not exported by default. Disable SMBv1, ssh, telnet, ftp, nfs by default (some are already disabled by default). Provide UI for ssh that lets them upload a public key and checkbox to enable keyboard password authentication. etc. We have already begun the 6.10 cycle and should have a -beta1 available soon early next week (hopefully).1 point
-
DEVELOPER UPDATE: 😂 But for real guys, I'm going to be stepping away from the UUD for the foreseeable future. I have a lot going on in my personal life (divorce among other stuff) and I just need a break. This thing is getting too large to support by myself. And it is getting BIG. Maybe too big for one dash. I have plenty of ideas for 1.7, but not even sure if you guys will want/use them. Not to mention the updates that would be required to support InfluxDB 2.X. At this point, it is big enough to have most of what people need, but adaptable enough for people to create custom panels to add (mods). Maybe I'll revisit this in a few weeks/months and see where my head is at. It has been an enjoyable ride and I appreciate ALL of your support/contributions since September of 2020. That being said @LTM and I (mostly him LOL) were working on a FULL Documentation website. Hey man, please feel free to host/release/introduce that effort here on the official forum. I give you my full blessing to take on the "support documentation/Wiki" mantel, if you still want it. I appreciate your efforts in this area. If LTM is still down, you guys are going to be impressed! I wanted to say a huge THANK YOU to @GilbN for his original dash which 1.0-1.2 was based on and ALL of his help/guidance/assistance over the last few months. It has truly been a great and pleasurable experience working with you man! Finally, I want to say a huge thanks to the UNRAID community and its leadership @SpencerJ @limetech. You guys supported and shared my work with the masses, and I am forever grateful! I am an UNRAIDer 4 LIFE! THANKS EVERYONE!1 point
-
Honestly this is pretty cool and I'm going to use it myself, thank you 😁 Just as a warning to anyone who decides to use this it's definitely worth taking note of above: This script also assumes your Default VM storage path is /mnt/user/domains/, if it's not, it will create a share called domains unless you update the references to this path. Also note that VM Manager needs to be started before you run the script if you are using the default Libvirt storage location which is a disk image that gets mounted when you start VM Manager. Otherwise when it gets started /mnt/user/domains/save will be bound to a location that no longer exists, and you'll possibly either get errors when pausing a VM or the local location won't have any data saved in it. So if you accidentally run the script with VM Manager stopped, you need to need to run the script again after starting it, or specifically the line: mount --bind /mnt/user/domains/save /var/lib/libvirt/qemu/save Also to revert to the original option I'm pretty sure you can just restart; or make sure no VMs are paused and run: sed -i -e "s/domain_save/domain_suspend/" /usr/local/emhttp/plugins/dynamix.vm.manager/include/VMajax.php You can then safely delete /mnt/user/domains/save which will likely be empty. I'm not going to include the code for deletion here in case someone makes a typo and deletes the contents of their array. Also there is a possibility that this will get broken / possibly become slightly dangerous in a new release, to be clear this is tested as working on versions 6.8.3 - 6.9.2. If anyone is really interested in making the change permanent; it appears relatively un-breaking and straight-forward to implement so like @bonienl said, best to make a feature request. This mount option has the benefit of not wasting space in libvirt.img, so if someone makes a feature request definitely reference @uek2wooF's script, because it's awesome.1 point
-
And just to be clear, the opposite of this kind of pause is "start". And yes the gui pause and start will work for this after running the userscript. And yes run the userscript at array start. The save file is removed after unpausing ("start"ing).1 point
-
That was the plan and it seems to work. It should be the default save since the others aren't really useful for much. Sorry for the delayed response, I don't get email notifications for some reason.1 point
-
Tu peux tester sur n'importe quelle version 6.9 d'Unraid1 point
-
I will change my github nickname to reflect my name, but before i must finish the whole translation and then make a .zip and test it on my system before, i must install 6.9.2 to test it or i can read all theses messages by using v6.9.1 ?1 point
-
Delete the file smart-one.cfg and re-apply the settings.1 point
-
Ah okay zenstates in go isnt necessary for your cpu1 point
-
And it's fixed. Thank you!!!1 point
-
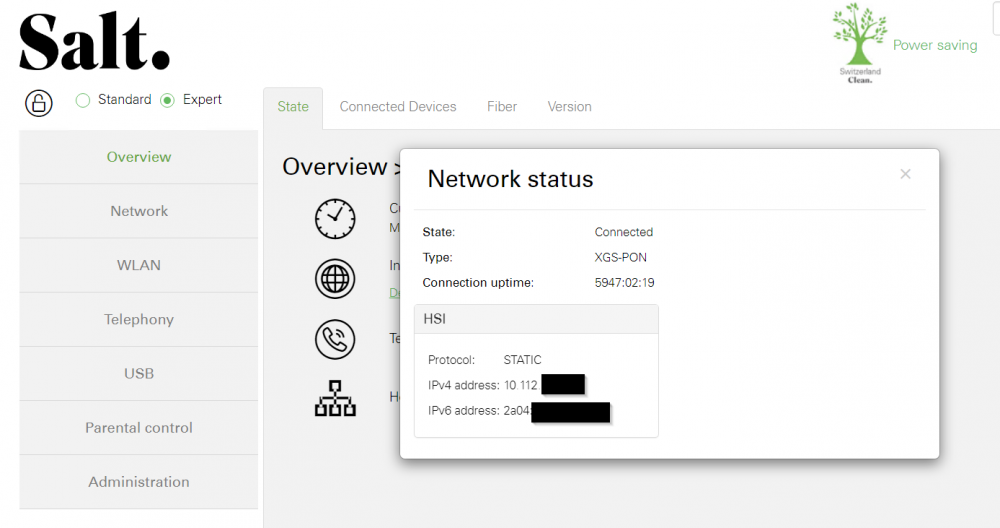
Hallo Also wenn du dich auf der SALT Box einloggst und dann bei Internet auf Details gehst solltest du so was sehen: Hier siehst du das ich keine offentliche IPv4 mehr habe 10.112.xx.xx Dies net man DS Lite, du teilst dir deine IPv4 mit vielen anderen Salt Kunden, ein NAT ist hier nicht möglich. Hier eine gute Seite zu diesem Problem: https://temporaryswiss.ch/salt-fiber-heimnetz-ipv6-dslite/ Ich habe das ungefähr wie in Option 3 beschrieben gelöst, mit einem Server bei Netcup und einem Tunnel zu meiner Firewall. So kann ich jederzeit weitere IPv4 adzukaufen. PS: Was erreichst du für Geschwindigkeiten? Grüsse YB1898
 1 point
1 point -
Howdy SimonF.....anything to help out the team!1 point
-
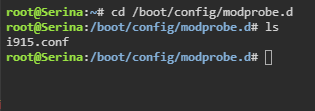
Problem solved. I'm documenting this in case someone runs into the same issue. The last 2 lines had already been removed from the go file. touch /boot/config/modprobe.d/i915.conf worked, and I've rebooted since just to be safe, but the graphics card was still not working with Intel GPU Top nor GPU Statistics. I then noticed that my Windows VM was set to iGPU. I stopped the VM, changed this to VNC and re-started the VM. Boom. Everything is working. So there you go, if you're having a similar problem, make sure your VMs aren't using the iGPU.


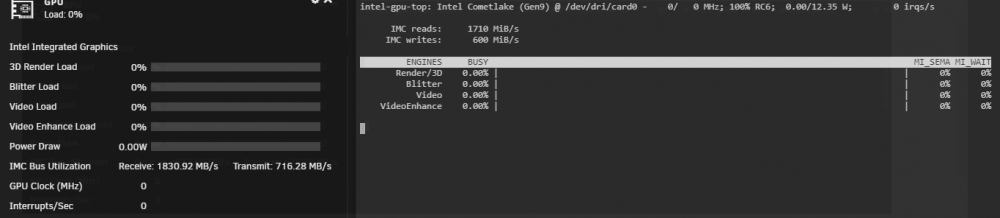 1 point
1 point -
No worries man take your time. You are doing awesome work and I appreciate it.1 point
-
Du kannst die Logs auf den USB Stick schreiben lassen. Das habe ich grundsätzlich aktiv.1 point
-
For those with the startup script errors: I just redownloaded a configuration file from PIA website, deleted the old one, and restarted Deluge and it seems to have fixed it. It looks to me that they renamed it to exclude the "nextgen-" from the file name. I don't know if that matters.1 point
-
Ich habe dir hier geanwortet: https://forums.unraid.net/topic/105609-migrate-synology-docker-to-unraid/?do=findComment&comment=9757821 point
-
Have you tried the default password incase it reset in the update? deluge is the default1 point
-
Reverting back to 6.8.3 If you have a cache disk/pool it will be necessary to either: restore the flash backup you created before upgrading (you did create a backup, right?), or on your flash, copy 'config/disk.cfg.bak' to 'config/disk.cfg' (restore 6.8.3 cache assignment), or manually re-assign storage devices assigned to cache back to cache This is because to support multiple pools, code detects the upgrade to 6.9.0 and moves the 'cache' device settings out of 'config/disk.cfg' and into 'config/pools/cache.cfg'. If you downgrade back to 6.8.3 these settings need to be restored.1 point
-
Server seems fine for his "workload". Within you NIXDESK I would passthrough the 1TB M2 directly to a Win 10 VM. So you are able to use your Win 10 Installation within a VM or if you want to boot directly from it, you can just boot directly from it 🙂 It should then looks like this: With this setting you can use your already installed and setuped Windows within Unraid as VM, and you are still able to boot directly from it. (If you want to). Keep in mind that just one VM at once can be booted up with passthrouged Graphicscards, USB-Controllers and so on... Maybe for the Ubuntu VM it is enough when you just use VNC as Graphicscard and emulated USBs
 1 point
1 point -
Which bonding mode? Do the ports show as up? i.e. have you tested with just one port no bonding.1 point
-
Hatte ich ja versucht. Bin auch der Meinung, dass ich das getan hätte, aber ich habe ja hier erfahren, dass CA evtl. nicht sauber arbeitet. Muss ich heute Abend nach der Arbeit mal schauen. Melde mich, wenn ich es getestet habe. --------edit-------- ich habe mal wieder den container gelöscht und mit CA den Ordner gelöscht. Dieses Mal nachgeschaut und der Ordner ist wirklich gelöscht. Neu installiert und ich konnte die Seite wieder nicht laden. Das ganze mache ich über Safari auf einem Mac. Dann nichts verändert und parallel über Chrome auf die Seite zugegriffen und es geht! Danach ging es auch auf Safari. Ich raff es nicht, aber es läuft. --------edit2------- hmmm, hab gedacht ich könne die Sprache auf deutsch umstellen. In der Config gibt es die Zeile: language: "en", Ich habe mal "de" eingetragen. Geht aber nicht. Zurück auf "en" geändert und nichts läuft mehr. Ganz seltsam. Selbst wenn es nicht "de" heisst, dann müsste es doch wenigstens zurück auf "en" laufen.1 point
-
...nutze es zwar selbst auch nicht, aber das ist - wie bei IPv4 keine Frage des "findens"....Du solltest ipv6 auf dem unraid host aktivieren (unter network-settings, network protocol) und dann solltest Du aus dem ipv6er Pool Deines Anbieters auch eine IPv6 vergeben können. Im Zweifel weiss Dein router welche noch frei, nicht vergeben sind und auch ausserhalb des dhcp6-pools sind1 point
-
Du kannst in den jeweiligen Container-Einstellungen das Netzwerk auf "custom br0" ändern, dann kannst du für den Docker eine IP aus deinem "normalen" Netzwerk festlegen1 point
-
I connected all the power cords for the cpu and the motherboard, and later found out that it was a memory problem.1 point
-
For unraid, I think the obvious configuration would be an array with 1 parity using the 3.5HDD, giving you 12TB storage and then the 1TB NVME as Cache Pool. Appdata (used by Docker Containers) and Domain (used by default for VMs) shares will automatically be configured to use the cache pool.1 point
-
Ding...ding...winner-winner, chicken dinner back to 6.9.1 and it works.......thanks again1 point
-
Updated from 6.9.1 -> 6.9.2 smoothly with all dockers up and running with no issues (knock on wood).1 point
-
You guys, this is the weirdest thing. My UnRaid server has a 6800 and a 6800XT. Both have been working perfectly since February. Yesterday, I installed water blocks on both cards. Since I did that, now, reset doesn't work anymore. If I reboot the VM, the display doesn't come back, and one CPU thread assigned to the VM gets stuck at around 87%. Changing the cooler on these cards couldn't possibly cause this, right? The only other thing I did was install an NVME SSD in the M.2 slot. Do you think that could cause reset to fail for both cards? Edit: False alarm. It was because the new SSD changed the IOMMU groups and for some reason, UnRaid stopped stubbing the serial bus controller for each card. This was causing reset to not work. Just in case anyone needs to know, or in case I forget this again (lol), these are the devices that need to be passed through for an AMD reference card. Obviously, your PCIe IDs will be different. AMD Radeon RX 6800/6800 XT / 6900 XT (0a:00.0) AMD Device (0a:00.1) <--- sound card AMD Device | USB controller (0a:00.2) AMD Device | Serial bus controller (0a:00.3)1 point
-
@limetech is it possible to revert/disable these changes so we can look to see if its kernel/driver specific. emhttpd: detect out-of-band device spin-up I have reverted to 6.9.1 for now. For info I have replaced doron's Smartctl wrapper with r5215 of smartctl and its working fine in 6.9.1. and 6.9.2 for both SAS and SATA. Could it be updated for 6.10 or next 6.9 release? root@Tower:/usr/sbin# ls smart* smartctl* smartctl.doron* smartctl.real* smartd* root@Tower:/usr/sbin# smartctl smartctl 7.3 2021-04-07 r5215 [x86_64-linux-5.10.21-Unraid] (CircleCI) Copyright (C) 2002-21, Bruce Allen, Christian Franke, www.smartmontools.org ERROR: smartctl requires a device name as the final command-line argument. Use smartctl -h to get a usage summary root@Tower:/usr/sbin# smartctl -n standby /dev/sde smartctl 7.3 2021-04-07 r5215 [x86_64-linux-5.10.21-Unraid] (CircleCI) Copyright (C) 2002-21, Bruce Allen, Christian Franke, www.smartmontools.org Device is in ACTIVE or IDLE mode root@Tower:/usr/sbin# smartctl -n standby /dev/sdf smartctl 7.3 2021-04-07 r5215 [x86_64-linux-5.10.21-Unraid] (CircleCI) Copyright (C) 2002-21, Bruce Allen, Christian Franke, www.smartmontools.org Device is in STANDBY BY COMMAND mode, exit(2) root@Tower:/usr/sbin#1 point
-
So I updated to 21.0.1 today and I had a few errors after. I will address them here and I hope they will help others to fix them quick. I had errors referring to my nginx config /.well-known/carddav, caldav, webfinger etc. Here is my nextcloud nginx config section about that location ^~ /.well-known { location = /.well-known/carddav { return 301 /remote.php/dav/; } location = /.well-known/caldav { return 301 /remote.php/dav/; } location = /.well-known/webfinger { return 301 /index.php$uri; } location ^~ /.well-known { return 301 /index.php$uri; } try_files $uri $uri/ =404; } I had them different before and apparently they do not work in this version. Also I had an error reffering to some db indices. Fo these you go into nextcloud container console and run sudo -u abc php /config/www/nextcloud/occ db:add-missing-indices And another one was reffering to default phone region. You have to add your phone region in config.php 'default_phone_region' => 'GB', You have to replace GB with your country specific code. You can find it here I hope this is useful info.1 point
-
Have a look at this thread. You need to add options for the i915 driver.1 point
-
I don't have pfSense but that looks correct to me1 point
-
We're working on a design that lets driver plugins be automatically updated when we issue a release.1 point
-
@ich777 will update them when he awakes. He is on the other side of the world1 point
-
@limetech, @jonp Maybe this thread should be moved by a forum admin in the "General support" section. I initially posted it as a prerelease bug report as I discovered the issue when I installed the UPS and my server was on 6.9.0 beta30, but it's obviously Unraid version agnostic. Moreover, it's very likely an apcupsd package and/or UPS firmware issue with USB connection, as others report the same under various distros in the apcupsd general mailing list. Despite, as it is the built-in Unraid solution to communicate with UPSes, I think it would make sense to have this tested workaround visible for those who'd encounter the same problems but will very likely not find this thread buried in the prerelease bug reports section... Thanks in advance for considering this move for the community.1 point
-
So this is interesting, apparently my Traktarr Docker is basically a super computer and is using >9EB of RAM: I don't even remember installing that much RAM and it seems to be holding the entirety of the internet in memory...
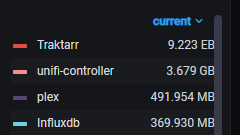 1 point
1 point -
This has nothing to do with it, since the Penryn emulated cpu is within the vm, and you need nested virtualization enabled in the host. As far as I know this is still not possible (and I doubt it will be in the future..) in mac os + amd cpu (mac os Hypervisor.framework doesn't support AMD-V). Moreover you can't have nested virtualization with emulated cpu, you need host-model or host-passthrough, which with amd can be quite complicated.1 point
-
Moved most of my NFS needs to a Ganesha-NFS via Docker and much grief in my system is now gone.. Emby loads quicker w/out randomly spinning forever, no stale file handlers, services can recover from nas restart, and Kubernetes is generally happier dealing w/NFSv4 Why this is not a priority I've no idea, it needs to be.. I'm only using SMB for TimeMachine backups, vast majority of traffic is NFS and now I've nearly abandoned unRaid's native sharing.. thank god for docker or I'd be looking at unraid alternatives at this point.1 point
-
Good to see you back! And hope you're feeling better.1 point
-
It has been some time since I visited the Unraid forums. Due to health issues I had to take a break, and unfortunately this break took way longer than anticipated. But I am back and will start giving support again to Unraid and plugins. First step is an update to the s3_sleep plugin, which now supports the latest features of Unraid 6.9 properly. Please update this plugin if you are running Unraid 6.9.0 or higher. I need to do a lot of catching up, but feel free to post issues with the Dynamix plugins here and I will look into it.1 point
-
I know that this is an old post, but for everyone who still has the same problem of rtc working on the 1st day and not the second, this is my version of the code: echo 0 > /sys/class/rtc/rtc0/wakealarm time=5:58 now=$(date +%s) other=$(date -d $time +%s) if [ $now -ge $other ] then echo `date '+%s' --date='tomorrow 5:58:00'` > /sys/class/rtc/rtc0/wakealarm else echo `date '+%s' --date='today 5:58:00'` > /sys/class/rtc/rtc0/wakealarm fi This resets the rtc clock which will make the code work every day. echo 0 > /sys/class/rtc/rtc0/wakealarm I use this code because the rtc function in my bios doesn't wake UNRAID from sleep. But this code worked a treat! If you wish to change the time, change all of the time values to your desired time. This code also has to be placed in the 'custom commands before sleep' text box.1 point
-
[I just spent 3 hours documenting the step by step work I'd been doing on this for logging in this thread. I have the same UPS and the same errors and the same problems. I don't use unRAID though but I'm sure it's nothing to do with unRaid. I've spent several nights attacking this problem from a low level USB /HID driver problem. Then, 5 minutes ago, I tried something different. And it fixed it. What... the... No guarantees, but here's what I did: # usb_modeswitch -v 0x051d -p 0x0003 --reset-usb (Check lsusb output to find out your vendor and product IDs) That's it. apctest works. apcaccess now reports ALL data.] Background: UPS: APC smc1500-2UC (same as the smc1500 but rack-mount. ) bios: 1.41, modbus enabled via front panel. ubuntu 20.04 apcupsd 3.14.14 apcupsd.conf: UPSCABLE usb UPSTYPE modbus DEVICE Unplug the usb cable then plug it back in. lsusb reports the device with the incremented port: root@sophie:/etc/apcupsd# lsusb Bus 001 Device 022: ID 051d:0003 American Power Conversion UPS dmesg shows: [Sun Jan 17 21:31:31 2021] usb 1-6.4: USB disconnect, device number 21 [Sun Jan 17 21:31:36 2021] usb 1-6.4: new full-speed USB device number 22 using xhci_hcd [Sun Jan 17 21:31:36 2021] usb 1-6.4: New USB device found, idVendor=051d, idProduct=0003, bcdDevice= 0.01 [Sun Jan 17 21:31:36 2021] usb 1-6.4: New USB device strings: Mfr=1, Product=2, SerialNumber=3 [Sun Jan 17 21:31:36 2021] usb 1-6.4: Product: Smart-UPS_1500 FW:UPS 04.1 / ID=1018 [Sun Jan 17 21:31:36 2021] usb 1-6.4: Manufacturer: American Power Conversion [Sun Jan 17 21:31:36 2021] usb 1-6.4: SerialNumber: 3S2012X12122 [Sun Jan 17 21:31:36 2021] hid-generic 0003:051D:0003.001C: hiddev1,hidraw5: USB HID v1.11 Device [American Power Conversion Smart-UPS_1500 FW:UPS 04.1 / ID=1018] on usb-0000:00:14.0-6.4/input0 Making sure that apcupsd is not running, I can run apctest but get the following: root@sophie:/etc/apcupsd# apctest 2021-01-17 21:15:44 apctest 3.14.14 (31 May 2016) debian Checking configuration ... sharenet.type = Network & ShareUPS Disabled cable.type = USB Cable mode.type = MODBUS UPS Driver Setting up the port ... 0.837 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT Doing prep_device() ... 4.091 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT You are using a MODBUS cable type, so I'm entering MODBUS test mode Hello, this is the apcupsd Cable Test program. This part of apctest is for testing MODBUS UPSes. Getting UPS capabilities...SUCCESS Please select the function you want to perform. 1) Test kill UPS power 2) Perform self-test 3) Read last self-test result 4) View/Change battery date 5) View manufacturing date 10) Perform battery calibration 11) Test alarm Q) Quit Note that it glitches during initialisation but gets there in the end. Trying a safe function (Perform self-test) works, as does 'Read last self-test result'. However, the moment I exit apctest, the following appears in dmesg: [Sun Jan 17 21:17:27 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd Ok, fine. apctest resets the device. However, if I try to re-run apctest immediately, the following occurs: root@sophie:/etc/apcupsd# apctest 2021-01-17 21:18:31 apctest 3.14.14 (31 May 2016) debian Checking configuration ... sharenet.type = Network & ShareUPS Disabled cable.type = USB Cable mode.type = MODBUS UPS Driver Setting up the port ... 0.289 apcupsd: ModbusUsbComm.cpp:258 WaitIdle: interrupt_read failed: Success 0.849 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT 1.402 apcupsd: ModbusUsbComm.cpp:142 ModbusRx: TIMEOUT 1.602 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=7, rx=21) 1.674 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=7, rx=21) 1.962 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=21, rx=7) 2.033 apcupsd: ModbusComm.cpp:201 SendAndWait: Wrong size (exp=21, rx=7) ... followed by many, many more glitchy lines, and eventually the menu. Exiting apctest and trying to start up the apcupsd daemon causes the following to start appearing in the syslogs: [Sun Jan 17 21:19:28 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:19:55 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:19:57 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:24:08 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd [Sun Jan 17 21:25:09 2021] usb 1-6.4: reset full-speed USB device number 21 using xhci_hcd Which I assume is happening as a consequence of something "not quite right". Here's the (wrong) output of apcaccess when things aren't working: root@sophie:/etc/apcupsd# systemctl start apcupsd root@sophie:/etc/apcupsd# apcaccess APC : 001,018,0436 DATE : 2021-01-17 21:19:46 -0800 HOSTNAME : sophie VERSION : 3.14.14 (31 May 2016) debian UPSNAME : sophieUPS CABLE : USB Cable DRIVER : MODBUS UPS Driver UPSMODE : Stand Alone STARTTIME: 2021-01-17 21:19:43 -0800 STATUS : MBATTCHG : 5 Percent MINTIMEL : 3 Minutes MAXTIME : 0 Seconds NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A STATFLAG : 0x05000000 END APC : 2021-01-17 21:19:46 -0800 And even when things are sort of working, here's the output of apcacess that still isn't any good: WIthout going into the 3 day jungle safari that has been my digging into learning the apcupcd code and how usb devices work when plugged into linux, suffice to say that I learned much about things I will never have a use for, but eventually worked out that I wanted to be able to disconnect and reconnect the usb device "at will", in the hopes of using the failed workaround documented by @Gnomuz. This led me through HID space and the frustrations of identifying the device path when something is plugged in. But then I discovered that 'mod_switch' has a reset parameter, and you only need to provide it with the Vendor and product IDs reported by 'lsusb'. Thus, the still-unbelievable simplicity of this: root@sophie:/etc/apcupsd# usb_modeswitch -v 0x051d -p 0x0003 --reset-usb Look for default devices ... Found devices in default mode (1) Access device 022 on bus 001 Get the current device configuration ... Current configuration number is 1 Use interface number 0 with class 3 Warning: no switching method given. See documentation Reset USB device . Device was reset -> Run lsusb to note any changes. Bye! Followed pessimistically by root@sophie:/etc/apcupsd# apctest 2021-01-17 22:38:48 apctest 3.14.14 (31 May 2016) debian Checking configuration ... sharenet.type = Network & ShareUPS Disabled cable.type = USB Cable mode.type = MODBUS UPS Driver Setting up the port ... Doing prep_device() ... You are using a MODBUS cable type, so I'm entering MODBUS test mode Hello, this is the apcupsd Cable Test program. This part of apctest is for testing MODBUS UPSes. Getting UPS capabilities...SUCCESS Please select the function you want to perform. 1) Test kill UPS power 2) Perform self-test 3) Read last self-test result 4) View/Change battery date 5) View manufacturing date 10) Perform battery calibration 11) Test alarm Q) Quit Select function number: q Where I noticed that I didn't get any of the glitch messages at all. I then repeatedly ran apctest over and over expecting errors, and got none. Anywhere. Still not believing anything, I started up apcupsd: root@sophie:/etc/apcupsd# systemctl start apcupsd and of course immediately tried the penultimate test, apcaccess. Which now reported this [you're gonna love this]: root@sophie:/etc/apcupsd# apcaccess APC : 001,038,0879 DATE : 2021-01-17 22:39:52 -0800 HOSTNAME : sophie VERSION : 3.14.14 (31 May 2016) debian UPSNAME : SophieUPS CABLE : USB Cable DRIVER : MODBUS UPS Driver UPSMODE : Stand Alone STARTTIME: 2021-01-17 22:39:45 -0800 STATUS : ONLINE LINEV : 118.4 Volts LOADPCT : 34.9 Percent LOADAPNT : 22.6 Percent BCHARGE : 98.4 Percent TIMELEFT : 28.0 Minutes MBATTCHG : 5 Percent MINTIMEL : 3 Minutes MAXTIME : 0 Seconds OUTPUTV : 118.4 Volts DWAKE : 0 Seconds DSHUTD : 180 Seconds ITEMP : 22.6 C BATTV : 26.0 Volts LINEFREQ : 60.0 Hz OUTCURNT : 2.75 Amps NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A SELFTEST : OK STATFLAG : 0x05000008 MANDATE : 2020-03-17 SERIALNO : 3S2012X12122 BATTDATE : 2020-04-14 NOMOUTV : 120 Volts NOMPOWER : 900 Watts NOMAPNT : 1440 VA FIRMWARE : UPS 04.1 / 00.5 END APC : 2021-01-17 22:40:46 -0800 It's all there, and more. My current best guess is that something isn't being initialized properly, or reset properly, within the apcupsd / apctest code. But running usb_modeswitch resets it properly/fully. That'll do me.
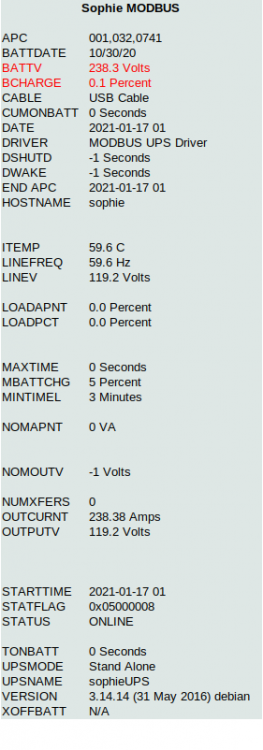 1 point
1 point -
Self-replying as this is now resolved and I can get a sustained 300mbit+. The solution was to add a new variable to the Syncthing docker container named UMASK_SET with a value of 000. I'm using the linuxserver.io docker image and it appears permissions were the cause of the speed issues.1 point
-
1. I understood the BETA nature of this plugin before using it (Please refer to the 1st line in the 1st post of this thread). 2. I have already been using the userscript version, since I found the plugin to be unstable. 3. It is important to report these issues so that: - others can know the unstable issues before using it, SO THAT THEY DON'T LOSE DATA FROM AN UNSTABLE SYSTEM. - The developer can work with those who want to find and test a fix. @Stupifier Not to be rude, but your response helps nobody. I have submitted my findings and report of what I've seen so far in this thread, so that the dev can help the people encountering strange unrelated errors and system instability. If you have something constructive to add to the discussion, please do so.1 point
-
The problem is when you have something like this https://github.com/mailcow/mailcow-dockerized/blob/master/docker-compose.yml It would be nice to have in dockerman a way to configure something the way docker compose does it, as a group. In the UI all the dockers could be nested in only one, and lets say you will configure all the dockers in the same template. It should be hard since more changes are in the UI. Somehow dockerman teamplates could be as a dockercompose yml1 point
-
I've tested these two options; 1) this Piwigo docker, accessing a separated mariadb instance. Rather complex and slow loading large amounts of images. 2) Piwigo, mariadb, nginx, php-fpm and CSF, all on 1 debian minimal VM. Both instances of piwigo access the exact same folders from an unraid share with terabytes of imagefiles. The second option performs noticeably faster, even without doing proper IO tests etc. The difference is so obvious, that I'm not even going to bother testing it with tools. Could be because I run unraid with a decent Xeon and 32GB RAM, but still; I don't see any advantage over docker instances for piwigo, and I just wanted to share that, because frankly, setting up piwigo in that VM was so much easier, other than maybe using a little fewer resources I don't understand what all the fuss on having it as a docker instance is about. The SSL/TLS cert for NGINX is located in an Unraid Share with Unraid Mount tag in the VM. Same LetsEncrypt wildcard cert I use for the unraid UI. So no weird proxying or network complexities. Plus, a csf/lfd firewall in front of the piwigo server VM, allowing me to serve the stuff through my internet-router to the world.1 point
-
09 Dec 2020 Basic usage instructions. Macinabox needs the following other apps to be installed. CA User Scripts (macinabox will inject a user script. This is what fixes the xml after edits made in the Unraid VM manager) Custom VM icons (install this if you want the custom icons for macOS in your vm) Install the new macinabox. 1. In the template select the OS which you want to install 2. Choose auto (default) or manual install. (manual install will just put the install media and opencore into your iso share) 3. Choose a vdisk size for the vm 4. In VM Images: Here you must put the VM image location (this path will put the vdisk in for the vm) 5. In VM Images again : re enter the same location as above. Here its stored as a variable. This will be used when macinabox generate the xml template. 6. In Isos Share Location: Here you must put the location of your iso share. Macinabox will put named install media and opencore here. 7. In Isos Share Location Again: Again this must be the same as above. Here its stored as a variable. Macinabox will use this when it genarates the template. 8. Download method. Leave as default unless for some reason method 1 doesnt work 9. Run mode. Choose between macinabox_with_virtmanager or virtmanager only. ( When I started rewriting macinabox i was going to only use virtmanager to make changes to the xml. However I thought it much easier and better to be able to use the Unraid vm manager to add a gpu cores ram etc, then have macinabox fix the xml afterwards. I deceided to leave vitmanager in anyway, in case its needed. For example there is a bug in Unraid 6.9.beta (including beta 35.) When you have any vm that uses vnc graphics then you change that to a passed through gpu it adds the gpu as a second gpu leaving the vnc in place. This was also a major reason i left virtmanger in macinabox. For situations like this its nice to have another tool. I show all of this in the video guide. ) After the container starts it will download the install media and put it in the iso share. Big Sur seems to take alot longer than the other macOS versions. So to know when its finished goto userscripts and run the macinabox notify script (in background) a message will pop up on the unraid webui when its finished. At this point you can run the macinabox helper script. It will check to see if there is a new autoinstall ready to install then it will install the custom xml template into the VM tab. Goto the vm tab now and run the vm This will boot up into the Opencore bootloader and then the install media. Install macOS as normal. After install you can change the vm in the Unraid VM Manager. Add cores ram gpu etc if you want. Then go back to the macinabox helper script. Put in the name of the vm at the top of the script and then run the script. It will add back all the custom xml to the vm and its ready to run. Hope you guys like this new macinabox1 point










































